Table of Contents
The ability to accurately compare the variability of different datasets is a fundamental requirement in statistical analysis. When dealing with two distinct populations, statisticians frequently need to determine if their underlying distributions exhibit similar levels of scatter or spread. This requirement is met efficiently through the use of the F-Test, a powerful tool derived from the F-distribution. In the modern context of data management and analysis, platforms like Google Sheets provide accessible and robust methods for executing complex statistical evaluations, including the comparison of two sample variances. Mastering this function within a spreadsheet environment allows analysts, researchers, and students to quickly assess assumptions necessary for subsequent tests, such as the two-sample T-test, or to simply draw conclusions about the inherent volatility of two groups.
To successfully perform the F-Test in Google Sheets, the user must first ensure their data is correctly structured and formatted across two separate columns, representing the two distinct samples being compared. The core of the analysis relies on the built-in =FTEST(sample1, sample2) function, which calculates the probability that the two sample variances come from populations with equal variances. This method bypasses the need for complex manual calculations of the F-statistic and directly outputs the critical P-Value. Once the P-Value is obtained, the final and most crucial step involves interpreting this result against a predetermined significance level, typically alpha ($alpha$) = 0.05, to determine whether there is sufficient evidence to reject the hypothesis that the population variances are equal. This comprehensive guide details the precise steps, theoretical underpinnings, and interpretation required to execute a statistically sound F-Test using Google Sheets.
Understanding the F-Test and Its Purpose
The F-Test is a statistical test of hypothesis based on the F-distribution. Its primary function is to compare the variances of two populations. This assessment is incredibly important across various fields, including finance (comparing volatility of two assets), quality control (checking consistency across two production lines), and experimental design (ensuring homogeneity of variance, a core assumption for ANOVA). The test statistic, known as the F-statistic, is simply the ratio of the two sample variances. If this ratio is close to 1, it suggests that the population variances are likely equal; deviations significantly larger or smaller than 1 indicate potential inequality.
The theoretical framework of the F-Test assumes that both populations from which the samples are drawn are normally distributed and that the samples are independent. While the test is generally robust to minor deviations from normality, extreme skewness or heavy tails can compromise the reliability of the result, making preliminary data inspection essential. When the F-Test is performed, it provides the analyst with the F-statistic and the corresponding P-Value, which quantifies the probability of observing the sampled data (or data more extreme) assuming the null hypothesis holds true. This probability is the key metric used for the decision-making process.
Crucially, the F-Test is not designed to compare population means; its sole focus is on the spread or variability within the data. Establishing whether two variances are equal is often a prerequisite step for selecting the correct version of other tests. For instance, when performing a two-sample t-test, the outcome of the F-Test dictates whether the pooled variance formula (assuming equal variances) or the unpooled variance formula (assuming unequal variances) should be employed. Thus, the F-Test serves as a gatekeeper for numerous higher-level statistical analyses, cementing its importance in the statistical toolkit.
Defining the Core Hypotheses
Every hypothesis test, including the F-Test, requires the formal establishment of a null hypothesis ($H_{0}$) and an alternative hypothesis ($H_{A}$). These hypotheses represent the competing statements about the population parameters that the test seeks to evaluate. The correct definition of these hypotheses is paramount, as the entire decision-making process—rejecting or failing to reject $H_{0}$—is based on their structure. For the F-Test comparing two population variances ($sigma_{1}^{2}$ and $sigma_{2}^{2}$), the structure is standardized to address the question of equality.
The standard hypotheses for a two-tailed F-Test are defined as follows:
- $H_{0}$: The population variances are equal ($sigma_{1}^{2} = sigma_{2}^{2}$). This is the assumption of no difference or the status quo that the researcher attempts to disprove.
- $H_{A}$: The population variances are not equal ($sigma_{1}^{2} neq sigma_{2}^{2}$). This is the claim that the researcher seeks to find evidence for, suggesting a statistically significant difference in variability between the two populations.
The decision to reject $H_{0}$ hinges on the comparison between the calculated P-Value and the predetermined alpha level ($alpha$). If the P-Value is smaller than $alpha$ (e.g., P-Value < 0.05), the result is deemed statistically significant, leading to the rejection of the null hypothesis. Conversely, if the P-Value is greater than $alpha$, the analyst fails to reject $H_{0}$, meaning there is insufficient evidence to conclude that the population variances are different. It is vital to remember that failing to reject $H_{0}$ does not prove equality; it merely suggests that the data does not provide enough evidence to support the alternative hypothesis.
Prerequisites and Assumptions for Reliable Analysis
Before executing the F-Test in Google Sheets, analysts must confirm that the underlying assumptions are reasonably met to ensure the validity and reliability of the results. The F-Test, like many parametric tests, is built upon specific mathematical prerequisites. Ignoring these assumptions can lead to erroneous conclusions, potentially misdirecting subsequent analytical decisions or practical applications. Therefore, a careful assessment of the data characteristics is an indispensable initial step.
The most critical assumption is that the populations from which the two samples are drawn must be normally distributed. The F-Test is particularly sensitive to violations of this normality assumption, especially when the sample sizes are small. While Google Sheets does not natively offer robust normality testing functions like specialized statistical software, analysts should use summary statistics (like skewness and kurtosis) or visual tools (such as histograms or Q-Q plots) constructed from the data to gauge the distribution shape. If strong evidence of non-normality exists, non-parametric alternatives or data transformation methods may be necessary before proceeding.
Secondly, the samples must be independent. This means that the data points in Sample 1 must not influence, nor be influenced by, the data points in Sample 2. For example, comparing test scores from two entirely separate groups of students would satisfy independence, whereas comparing pre-test and post-test scores from the same group would violate this assumption, requiring a paired test instead. Finally, while sample sizes do not have to be equal for the F-Test to be performed, larger sample sizes generally improve the power of the test, increasing the likelihood of detecting a true difference if one exists. Ensuring that data collection methodology adheres to these principles is essential for robust hypothesis testing.
Step 1: Preparing Your Data for Analysis
The first practical step in performing the F-Test within Google Sheets involves organizing the raw data into a clean, columnar format. Statistical functions require that the data belonging to the two groups being compared are placed into separate, dedicated columns. This preparation minimizes errors in range selection and ensures that the FTEST() function correctly differentiates between the two samples. For instance, if comparing the reaction times of two experimental groups (Group A and Group B), the reaction times for Group A must occupy one column (e.g., Column A), and the reaction times for Group B must occupy a separate, adjacent column (e.g., Column B).
It is recommended practice to label the columns clearly in the first row (e.g., “Sample 1” and “Sample 2”) but to exclude these header cells when defining the range for the statistical function. The data itself should consist entirely of numerical entries; non-numeric values, blank cells, or error codes within the selected range will cause the FTEST() function to return an error value. Furthermore, while the F-Test accommodates unequal sample sizes, all data relevant to each sample must be included in its respective column, starting from the first numerical entry and extending downward to the last. This meticulous preparation streamlines the subsequent application of the function.
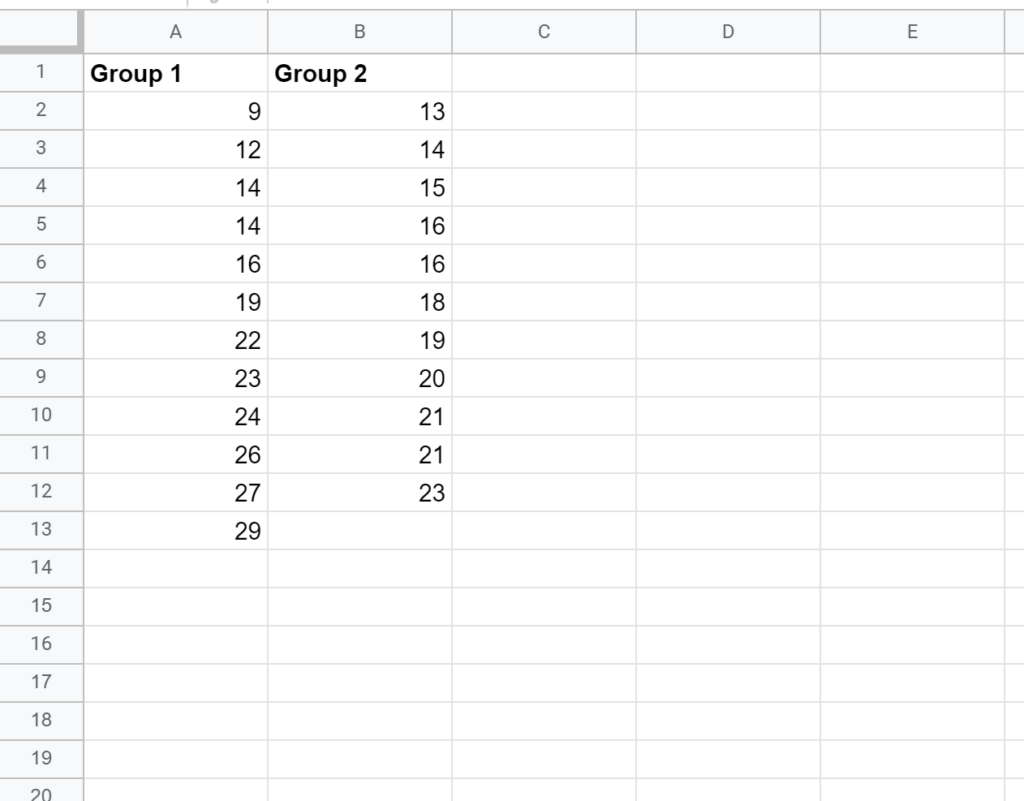
Consider the following example data structure for two distinct samples, perhaps representing the test scores from two different teaching methodologies. The data is entered side-by-side, ensuring easy identification and selection for the formula input:

Note: As illustrated above, the sizes of the two samples do not necessarily need to be identical. The F-Test is inherently flexible regarding sample size asymmetry, provided that there is a sufficient number of observations in both groups to yield meaningful variance estimates. For basic analysis, selecting the data range accurately is the only requirement, regardless of whether the ranges are of equal length.
Step 2: Executing the FTEST() Function
Once the data is properly prepared and entered into adjacent columns, the execution of the F-Test in Google Sheets is simplified by using the native =FTEST(sample1, sample2) function. This function is specifically designed to perform the two-sample F-Test for variances and immediately returns the two-tailed P-Value, eliminating the intermediate step of calculating the F-statistic and consulting critical value tables. The syntax is straightforward: the user specifies the range corresponding to the first sample and the range corresponding to the second sample, separated by a comma.
To implement this, select an empty cell where the result should appear (e.g., cell C2). Type the formula, substituting the generic terms “sample1” and “sample2” with the exact cell ranges containing the numerical data. For the example data provided in Step 1, where Sample 1 is in Column A and Sample 2 is in Column B, the formula would look like =FTEST(A2:A10, B2:B12). It is vital to ensure that the ranges accurately capture all data points for both groups and exclude any non-numerical headers or labels. The order in which the samples are entered (i.e., whether Sample 1 is listed first or second) does not affect the resulting P-Value for a two-tailed test, as the test is symmetrical, although convention often dictates listing the sample with the larger variance first when calculating the F-statistic manually.
The result of this function is a single numerical value representing the probability of observing the variances if the null hypothesis were true. Observe the function execution in the following illustration, applied directly to the sample data:

As depicted, the function immediately processes the ranges and yields the P-Value. This simplicity makes Google Sheets an extremely efficient tool for preliminary statistical screening, allowing researchers to quickly establish whether the variance assumption holds before proceeding to more complex models or analyses.
Step 3: Interpreting the F-Statistic and P-Value
For the sample calculation demonstrated, the P-Value returned by the FTEST() function is 0.0367. This P-Value is the linchpin of the hypothesis test, providing the probability against which the decision rule is applied. The interpretation of this value requires comparison with the predetermined significance level ($alpha$), which is conventionally set at 0.05. This $alpha$ value represents the maximum risk the analyst is willing to accept of incorrectly rejecting a true null hypothesis (Type I Error).
In this specific case, 0.0367 is less than the standard significance level of 0.05 (0.0367 < 0.05). According to the statistical decision rule, when the P-Value is less than $alpha$, the analyst must reject the null hypothesis ($H_{0}$). Rejecting $H_{0}$ means that the data provides statistically sufficient evidence to conclude that the alternative hypothesis ($H_{A}$) is true: that the population variances are not equal ($sigma_{1}^{2} neq sigma_{2}^{2}$). In practical terms regarding the example data, we would conclude that the variability in test scores between the two teaching methodologies is significantly different.
If the P-Value had been, for example, 0.15, which is greater than 0.05, the analyst would fail to reject $H_{0}$. This would imply that, based on the sampled data, there is not enough statistical evidence to claim a difference in the population variances. The conclusion must always be framed in terms of the evidence provided by the sample; a P-Value close to the significance level, such as 0.049, still warrants the rejection of $H_{0}$, emphasizing the strict threshold nature of the decision rule.
Special Considerations: Two-Tailed vs. One-Tailed Tests
It is important to recognize that the FTEST() function in Google Sheets, by default, returns the P-Value for a two-tailed test. A two-tailed test is designed to detect a difference in either direction—that Sample 1 variance is greater than Sample 2 variance, or vice versa—which aligns with the standard null hypothesis ($H_{0}: sigma_{1}^{2} = sigma_{2}^{2}$) and the alternative hypothesis ($H_{A}: sigma_{1}^{2} neq sigma_{2}^{2}$). This is the most common application of the F-Test when simply checking the assumption of equal variance prior to a T-test or ANOVA.
However, there are scenarios where researchers are interested only in whether the variance of one specific population is significantly greater than the other. This requires a one-tailed test. For example, the alternative hypotheses for one-tailed tests would be either $H_{A}: sigma_{1}^{2} > sigma_{2}^{2}$ (right-tailed) or $H_{A}: sigma_{1}^{2} < sigma_{2}^{2}$ (left-tailed). Since the FTEST() function provides the two-tailed P-Value, a simple adjustment is needed to derive the correct one-tailed P-Value.
To convert the two-tailed P-Value ($P_{2text{-tail}}$) provided by Google Sheets into the one-tailed P-Value ($P_{1text{-tail}}$), the result should be divided by two: $P_{1text{-tail}} = P_{2text{-tail}} / 2$. This mathematical adjustment is necessary because the two-tailed P-Value accounts for the probability mass in both extremes of the F-distribution, whereas the one-tailed test focuses only on the probability mass in the single tail relevant to the directional hypothesis. After performing this division, the analyst compares the resulting one-tailed P-Value against the significance level ($alpha$) to make the final decision regarding the directional hypothesis.
Conclusion and Practical Applications
The execution of the F-Test in Google Sheets is a highly efficient process, leveraging the powerful built-in FTEST() function to quickly return the critical P-Value. This method allows for immediate assessment of whether two population variances are statistically distinct, provided the underlying assumptions of independence and approximate normality are met. The example demonstrated resulted in a P-Value (0.0367) below the typical $alpha = 0.05$ threshold, leading to the necessary rejection of the null hypothesis of equal variance.
The primary practical application of this result is its implication for subsequent statistical modeling. If the variances are found to be unequal (as concluded in our example), any future two-sample T-tests comparing the means of these two groups must utilize the Welch’s T-test, which does not assume equal variances. Conversely, if the F-Test had failed to reject $H_{0}$, the standard T-test assuming pooled variance would be appropriate. Thus, the F-Test is not merely an isolated analysis but a crucial diagnostic step that determines the correct path for comparative inference.
In summary, Google Sheets provides an accessible, non-specialized environment for performing rigorous statistical tests. By following the steps outlined—data preparation, function execution, and careful interpretation of the two-tailed P-Value (with appropriate adjustment for one-tailed scenarios)—users can confidently draw conclusions about population variability, thereby strengthening the foundation of their overall statistical research and decision-making processes.
Cite this article
stats writer (2025). How to Perform an F-Test in Google Sheets: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-perform-an-f-test-in-google-sheets-step-by-step/
stats writer. "How to Perform an F-Test in Google Sheets: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 5 Dec. 2025, https://scales.arabpsychology.com/stats/how-can-i-perform-an-f-test-in-google-sheets-step-by-step/.
stats writer. "How to Perform an F-Test in Google Sheets: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-can-i-perform-an-f-test-in-google-sheets-step-by-step/.
stats writer (2025) 'How to Perform an F-Test in Google Sheets: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-perform-an-f-test-in-google-sheets-step-by-step/.
[1] stats writer, "How to Perform an F-Test in Google Sheets: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Perform an F-Test in Google Sheets: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.