
Table of Contents
The Z-Table: Mastering the Standard Normal Distribution
The Z-Table, formally recognized as the standard normal distribution table (or Unit Normal Table), is perhaps the most fundamental reference tool in inferential statistics. It provides a systematic method for calculating the cumulative probability associated with any given data point within a dataset that conforms to a bell-shaped curve. By standardizing raw data into z-scores, the table allows statisticians and analysts to quickly determine the likelihood of an observation falling above, below, or between specific values. Understanding the Z-Table is essential for moving from descriptive statistics to making powerful, data-driven inferences about large populations.
This comprehensive guide delves into the structure, interpretation, and practical applications of the Z-Table. We will explore how it serves as a bridge between observed data and theoretical distributions, enabling precise measurements of uncertainty and risk in fields ranging from quality control to psychological testing. Mastering this single table unlocks the power of the standard normal model, providing the backbone for more complex procedures like Z-tests and confidence interval construction.
The Foundation: Understanding the Standard Normal Distribution
To appreciate the Z-Table, one must first grasp the concept of the standard normal distribution. This is a specific instance of the normal distribution where the mean ($mu$) is set to 0 and the standard deviation ($sigma$) is set to 1. Any data that is normally distributed can be converted into this standardized form, regardless of its original scale or units, through a process called standardization.
Standardization is crucial because it allows us to use a single reference table (the Z-Table) for virtually any normally distributed variable, whether we are measuring human height, test scores, or manufacturing tolerances. The standard normal curve is perfectly symmetrical around its mean (0). This symmetry is key; it means that the area under the curve is divided equally, with 50% of the observations falling below the mean and 50% falling above the mean. The total area under the curve is always equal to 1, or 100%, representing the total probability space.
The standard normal distribution adheres to the empirical rule (the 68-95-99.7 rule), which dictates the percentage of data falling within specific ranges defined by standard deviations. Specifically, approximately 68% of the data falls within $pm 1$ standard deviation of the mean, 95% within $pm 2$ standard deviations, and 99.7% within $pm 3$ standard deviations. The Z-Table quantifies these percentages much more precisely, providing the exact cumulative area (or probability) for any fractional z-score.
Interpreting the Z-Score: The Language of Standard Deviation
The z-score is the fundamental input for the Z-Table. It is a measure of position that expresses how many standard deviations a raw score ($x$) is away from the population mean ($mu$). A positive z-score indicates the value is above the mean, while a negative z-score indicates the value is below the mean. A z-score of 0 means the value is exactly equal to the mean.
The formula for calculating the z-score ($Z$) is straightforward:
$$Z = frac{x - mu}{sigma}$$Here, $x$ is the individual raw score, $mu$ is the population mean, and $sigma$ is the population standard deviation. By transforming a raw score into a z-score, we are effectively converting the original scale into a standardized scale based on standard deviations. This allows us to compare scores from different normal distributions directly, a process that would be impossible using raw scores alone.
For example, if a student scores 85 on a test with a mean of 70 and a standard deviation of 10, their z-score is $Z = (85 – 70) / 10 = 1.5$. This means the student scored 1.5 standard deviations above the average. Once this standardized value is obtained, the Z-Table can be used to determine what percentage of test takers scored below this student, providing a relative measure of performance.
Deconstructing the Z-Table: Structure and Components
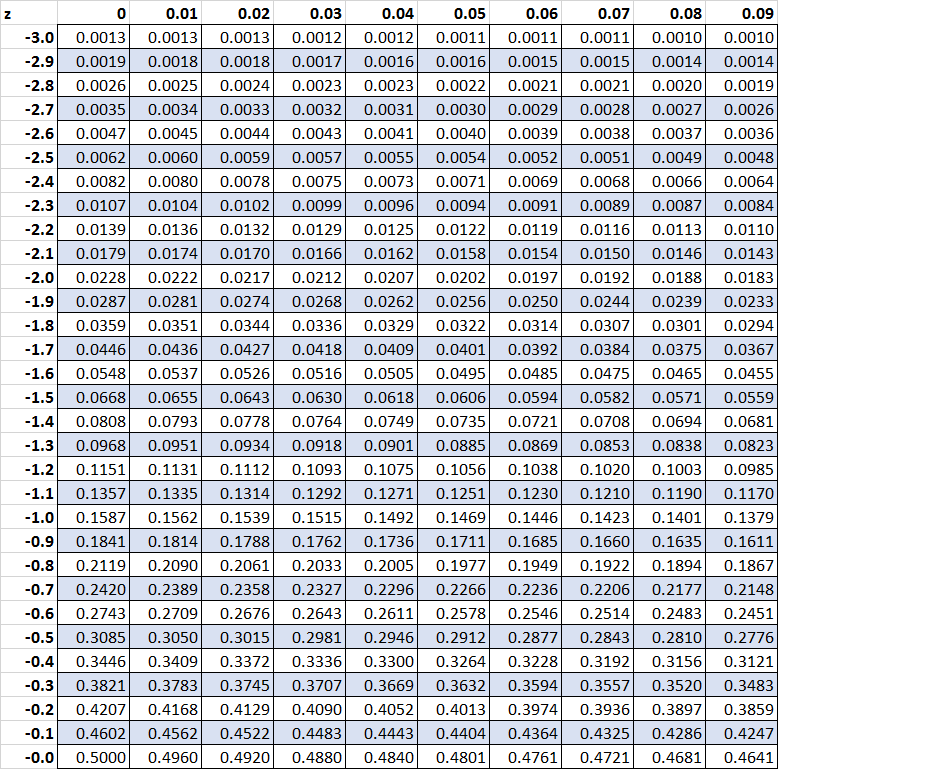
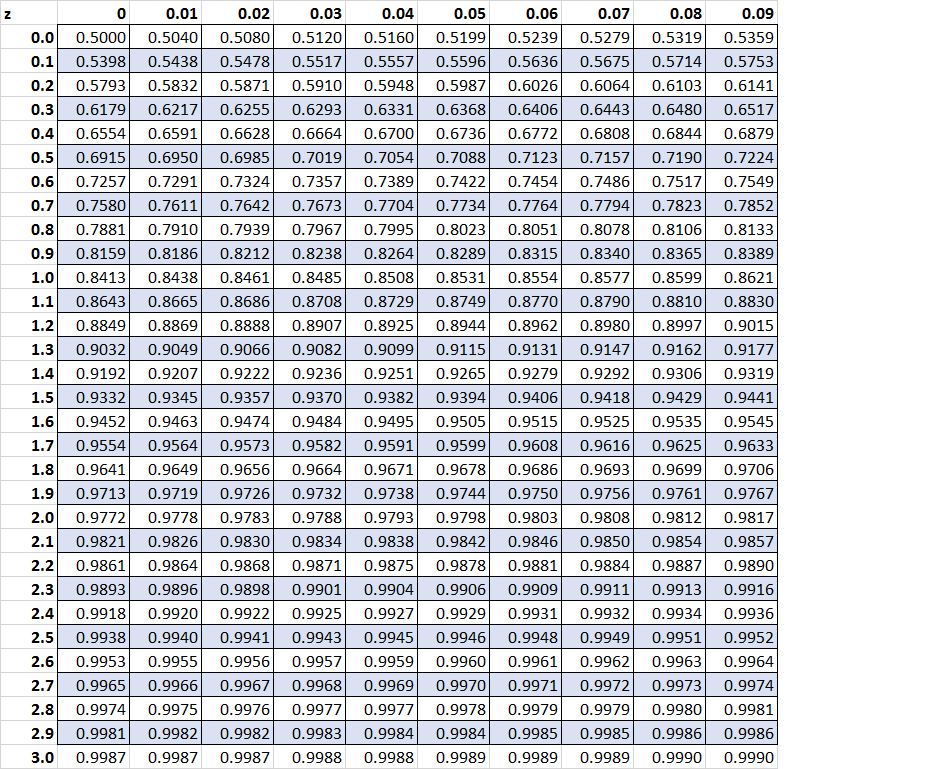
The Z-Table is structured to display the cumulative area under the standard normal curve. This area always represents the probability of observing a value less than (to the left of) the specified z-score. Because the curve is symmetrical, the Z-Table is typically presented in two separate sections: one for negative z-scores and one for positive z-scores.
Primary Function: Cumulative Area
The table entry corresponding to a specific z-score provides the total area under the curve stretching from the far left tail up to that z-score. This area is the cumulative probability $P(Z < z)$.
Structure for Positive and Negative Z-Scores
Since the standard normal distribution is symmetrical, tables for negative z-scores (values below the mean) list probabilities less than 0.5000, while tables for positive z-scores (values above the mean) list probabilities greater than 0.5000. Some compact tables only provide positive z-scores, relying on the user to utilize symmetry rules for negative values.
Reading the Coordinates
The lookup process requires combining the row and column values to form the precise z-score:
- Rows: Represent the whole number and the first decimal place of the z-score (e.g., 1.0, 1.1, -0.5).
- Columns: Represent the second decimal place of the z-score (e.g., .00, .01, .02, up to .09).
For example, to find the probability for $Z = 1.23$, you would look for the row labeled “1.2” and the column labeled “.03”. The cell at their intersection contains the cumulative probability associated with $Z = 1.23$.
Step-by-Step Guide to Using the Z-Table
Using the Z-Table effectively involves a methodical approach, ensuring the raw data is properly standardized and the correct area of the curve is identified. The steps below detail how to find the probability of a specific observation occurring.
Step 1: Calculate the Z-Score
Begin by transforming your raw data point ($x$) into a standardized z-score using the formula $Z = (x – mu) / sigma$. Ensure you know both the population mean ($mu$) and the standard deviation ($sigma$). Round the calculated z-score to two decimal places, as this is the precision level the standard Z-Table supports.
Step 2: Locate the Correct Table Section
Determine whether your z-score is positive or negative. If $Z > 0$, use the positive Z-Table (probabilities greater than 0.5000). If $Z < 0$, use the negative Z-Table (probabilities less than 0.5000). If $Z = 0$, the probability should be exactly 0.5000.
Step 3: Find the Row and Column Intersection
Use the whole number and the first decimal place of the z-score to locate the correct row in the table. Use the second decimal place to locate the correct column. The value at this intersection is the cumulative probability, $P(Z < z)$.
Step 4: Interpret the Resulting Area
The probability found in the table represents the area to the left of your z-score. This is the probability that a randomly selected observation from the population will have a value less than or equal to your original raw score ($x$). If you need the probability of a value being greater than $x$, subtract the table value from 1 (since the total area under the curve is 1).
Calculating Probabilities: Beyond the Left Tail
While the Z-Table intrinsically provides the area to the left (the cumulative probability), statisticians frequently need to calculate probabilities for other regions of the distribution, such as the area to the right, or the area between two specific z-scores. These calculations rely on the fundamental properties of the standard normal curve—specifically, that the total area is 1 and the curve is symmetrical.
1. Area to the Right ($P(Z > z)$): To find the probability that an observation is greater than a given z-score, we use the complement rule. Since the table gives $P(Z < z)$, the area to the right is $1 – P(Z < z)$. This is often used in hypothesis testing to find the p-value when testing an upper-tail hypothesis.
2. Area Between Two Z-Scores ($P(z_1 < Z < z_2)$): To find the probability that an observation falls between two values, $z_1$ and $z_2$ (where $z_2 > z_1$), we calculate the cumulative probability for both scores and subtract the smaller from the larger. Specifically, the area is $P(Z < z_2) – P(Z < z_1)$. This technique is vital for determining the likelihood of a value falling within a specified range, such as a quality tolerance band or a specific grade level.
3. Two-Tailed Probabilities ($P(|Z| > z)$): For scenarios involving two tails, such as identifying extreme outliers or conducting two-tailed Z-tests, we often need the area outside of a central range ($pm z$). Because of symmetry, the area in the two tails is equal to $2 times P(Z z)$. Alternatively, it can be calculated as $1 – P(-z < Z < z)$, where $P(-z < Z < z)$ is the central area calculated using the method above.
Practical Applications in Statistical Inference
The Z-Table is not just a theoretical tool; it is the cornerstone of several key procedures in statistical inference, allowing researchers to draw conclusions about populations based on sample data. Its application spans hypothesis testing and the construction of confidence intervals, providing quantifiable measures of certainty.
Hypothesis Testing
The Z-Table is indispensable when conducting a Z-test, which is used to test hypotheses about population means or proportions when the population standard deviation is known (or when the sample size is large enough to assume the population standard deviation is known). After calculating the test statistic (which is a z-score), the Z-Table is used to find the critical value or the p-value. The critical value approach requires looking up the z-score that corresponds to a predefined significance level ($alpha$), while the p-value approach uses the Z-Table to find the exact probability of observing the test statistic, assuming the null hypothesis is true.
Constructing Confidence Intervals
Confidence intervals (CIs) provide a range of plausible values for an unknown population parameter (like the population mean) based on sample data. The construction of a CI requires determining the critical z-score ($z_{alpha/2}$) that defines the boundaries of the interval. For instance, to construct a 95% confidence interval, we need the z-scores that cut off the top 2.5% and the bottom 2.5% of the distribution. By consulting the Z-Table backward (finding the area closest to 0.025 and 0.975), we determine that the critical z-scores are approximately $pm 1.96$. This value is then used in the margin of error calculation, illustrating the Z-Table’s direct role in parameter estimation.
Determining Percentiles and Quartiles
If you know the population parameters, the Z-Table allows you to reverse the process—starting with a desired probability or percentile (e.g., the 90th percentile, which corresponds to an area of 0.9000), you can locate that probability inside the table. Then, by identifying the corresponding z-score from the row and column headers, you can transform that z-score back into the raw data value using the inverse z-score formula: $x = mu + Z sigma$. This is extremely useful in educational assessment and standardized testing.
Limitations and Considerations
While the Z-Table is a powerful tool, its utility is contingent upon certain assumptions and limitations. Relying on the Z-Table inappropriately can lead to flawed statistical conclusions, emphasizing the need for critical evaluation of the underlying data structure.
The primary limitation is the inherent assumption that the data follows a true normal distribution. If the data is significantly skewed, heavy-tailed, or bimodal, applying the Z-Table probabilities will result in inaccurate conclusions. While the Central Limit Theorem often ensures that the distribution of sample means approaches normality even if the population is not normal, applying the Z-Table to individual raw scores requires genuine normality.
Furthermore, when conducting inference with small sample sizes ($n < 30$) and the population standard deviation ($sigma$) is unknown, the Z-Table is inappropriate. In such cases, the uncertainty introduced by estimating the standard deviation requires the use of the Student’s t-distribution and the corresponding t-table. The t-distribution accounts for the additional variability introduced by the small sample size, and its shape changes based on the degrees of freedom, unlike the single, universal standard normal distribution used by the Z-Table.
Finally, modern statistical software has largely automated the process of calculating these probabilities. However, understanding the Z-Table remains crucial for conceptualizing probability distributions, interpreting software outputs, and gaining a deep appreciation for how continuous probability distributions are mapped and analyzed in classical statistics.
Cite this article
Mohammed looti (2026). How to Use a Z Table to Find Probabilities. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/z-table/
Mohammed looti. "How to Use a Z Table to Find Probabilities." PSYCHOLOGICAL SCALES, 4 Jan. 2026, https://scales.arabpsychology.com/stats/z-table/.
Mohammed looti. "How to Use a Z Table to Find Probabilities." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/z-table/.
Mohammed looti (2026) 'How to Use a Z Table to Find Probabilities', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/z-table/.
[1] Mohammed looti, "How to Use a Z Table to Find Probabilities," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, January, 2026.
Mohammed looti. How to Use a Z Table to Find Probabilities. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.