Table of Contents
Generating effective data visualization is a fundamental step in any data analysis workflow. When dealing with complex categorical variables, the Pandas library provides robust tools for summarizing frequencies. Specifically, the pandas.crosstab() function is indispensable for calculating a cross-tabulation table of two or more factors. However, raw frequency tables are often difficult to interpret quickly; this is where the power of the Bar Plot comes into play. A bar plot provides an immediate, intuitive visual representation of these counts, making comparisons straightforward.
This comprehensive guide details the precise methodology for transforming a Pandas crosstab object directly into a usable bar chart. We will leverage the built-in plotting capabilities of Pandas, which are themselves wrappers around the powerful Matplotlib library. By understanding how to integrate the frequency calculation of the crosstab with the visualization methods provided by .plot(kind='bar'), data scientists can efficiently convey insights derived from multivariate categorical data structures. We will explore two primary visualization methods: the grouped bar plot and the stacked bar plot, detailing when and how to apply each effectively.
The Role of the Pandas crosstab() Function in Data Summarization
Before any visualization can occur, we must first aggregate our raw data into meaningful counts. This is the primary function of the pandas.crosstab() method. This function computes a simple cross-tabulation of two or more factors, providing frequency tables that are crucial for statistical analysis. Unlike the value_counts() method, which only handles a single series, crosstab() allows us to examine the joint distribution of multiple categorical variables simultaneously, forming a DataFrame where the indices and columns represent the categories being compared.
The resulting crosstab DataFrame is perfectly structured for plotting. Since the index often represents the primary grouping variable (like ‘Team’) and the columns represent the secondary variable (like ‘Position’), the transition to a visual representation is seamless. The values within the table are the counts, which translate directly into the height of the bars in our subsequent plot. This fundamental step ensures that the data fed into the plotting function is already structured in a way that aligns perfectly with standard bar chart conventions.
Understanding the structure of the crosstab output is key to effective plotting. Each row in the resulting table corresponds to a category on the x-axis of the eventual bar plot, and each column corresponds to a different color or group within those bars. The flexibility of crosstab() allows analysts to normalize the counts (using parameters like normalize=True) to view proportions instead of raw frequencies, enabling visualizations that compare relative distributions across categories, not just absolute counts. However, for standard frequency visualization, we typically rely on the default raw count output.
Setting Up the Environment and Sample Data
To demonstrate the plotting process, we first need to import the necessary libraries—primarily Pandas for data manipulation and visualization setup, and implicitly, Matplotlib, as Pandas plotting functions rely on its backend. We then define a sample dataset, typically a Pandas DataFrame, containing the categorical variables we wish to analyze. For this example, we use a dataset describing players, their teams, and their positions.
The following code snippet demonstrates the creation of a sample DataFrame and the subsequent generation of the crosstab object, which will serve as the input for all our visualizations. This preliminary step ensures reproducibility and clarity throughout the visualization process, allowing us to focus solely on the plotting mechanics in the subsequent sections.
import pandas as pd #create DataFrame df = pd.DataFrame({'team': ['A', 'A', 'A', 'B', 'B', 'B', 'B', 'C', 'C', 'C', 'C'], 'position':['G', 'G', 'F', 'G', 'F', 'F', 'F', 'G', 'G', 'F', 'F'], 'points': [22, 25, 24, 39, 34, 20, 18, 17, 20, 19, 22]}) #create crosstab to display count of players by team and position my_crosstab = pd.crosstab(df.team, df.position) #view crosstab print(my_crosstab) position F G team A 1 2 B 3 1 C 2 2
The resulting my_crosstab object clearly summarizes the count of players (F and G positions) within each team (A, B, and C). This matrix is now ready to be visualized. The index (Team) will define the groups on the x-axis, and the columns (Position) will define the individual bars or segments within those groups. This structure is essential for generating both grouped and stacked visualizations effectively.
Example 1: Generating a Grouped Bar Plot from Crosstab
The grouped bar plot, often referred to simply as a bar plot when using Pandas’ .plot() method, is the default visualization for a multi-column DataFrame derived from a crosstab. This method displays separate bars for each category within the primary grouping variable, allowing for direct comparison of the frequency counts across all combinations. This is the ideal choice when the absolute magnitude of each subgroup count is the primary focus of the analysis.
To create a grouped bar plot, we simply call the .plot() method on the crosstab object and specify kind='bar'. We also commonly include the rot=0 argument to prevent the x-axis labels from overlapping, ensuring readability, especially when the category names are long. This straightforward command leverages the intrinsic structure of the DataFrame—the index and columns—to define the axes and the coloring scheme automatically.
Here is the implementation code, followed by a discussion of its interpretation. Note that while we include import matplotlib.pyplot as plt for standard practice, the plot command itself is executed directly on the Pandas object, demonstrating the convenience of the Pandas plotting API.
import matplotlib.pyplot as plt #create grouped bar plot my_crosstab.plot(kind='bar', rot=0)

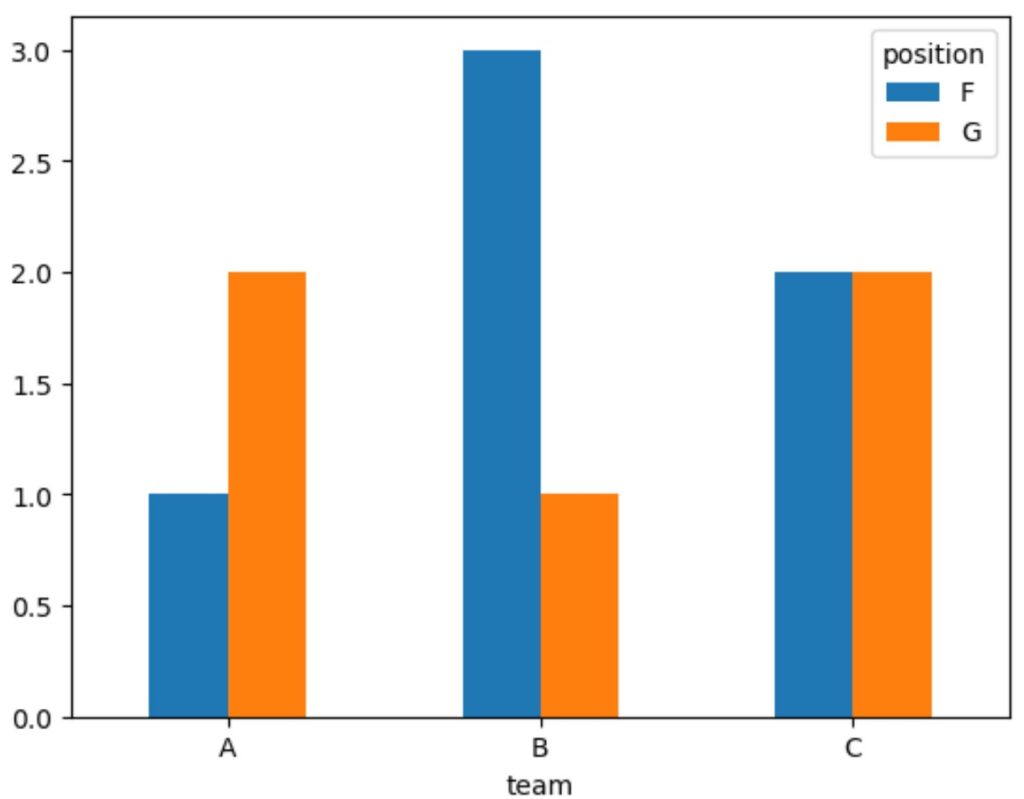
In this visualization, the x-axis represents the primary grouping variable (Team), while the grouped bars show the frequency count for each position (F and G) within that team. The argument rot=0 ensures that the team names are displayed horizontally for maximum clarity, a critical detail for production-ready graphics. The resulting plot allows for immediate observations regarding subgroup distributions.
Understanding and Customizing Grouped Bar Charts
A grouped Bar Plot excels at facilitating comparisons across categories. For instance, by observing the plot, we can easily ascertain which team has the highest count of ‘F’ players versus ‘G’ players. The height of the individual bars directly correlates to the value in the original crosstab table.
- Team A: Shows 1 player in position F and 2 players in position G.
- Team B: Shows 3 players in position F and 1 player in position G.
- Team C: Shows 2 players in position F and 2 players in position G.
While the basic plot command provides a good starting point, Pandas plotting, backed by Matplotlib, allows for extensive customization. Common enhancements include adding titles (title='...'), labeling axes (which often requires capturing the Matplotlib Axes object), and modifying the legend location. Furthermore, to enhance visual impact, color palettes can be adjusted, and grid lines can be added or removed. For example, to make the comparison between the F and G positions even more distinct, one might manually set contrasting colors using the color parameter within the .plot() function.
For high-quality reports, it is often necessary to go beyond the default settings. Adjusting figure size using figsize=(width, height) before the plot call (e.g., my_crosstab.plot(kind='bar', figsize=(8, 6))) ensures the visualization fits the desired output format without distortion or crowding. Although the basic example is functional, mastering these customization parameters is essential for producing publication-quality visualizations that clearly communicate complex data relationships.
Example 2: Creating a Stacked Bar Plot from Crosstab
In contrast to the grouped bar plot, the stacked bar plot is designed to emphasize the total count for the primary category while simultaneously showing the contribution of each subgroup to that total. This visualization is particularly useful when the analyst is interested in comparing the overall magnitude of the primary groups (the length of the entire bar) and the proportional breakdown within them.
The transition from a grouped to a stacked bar plot requires the addition of a single, crucial parameter to the .plot() function: stacked=True. By setting this flag, Pandas reinterprets the DataFrame structure, placing the column values on top of one another instead of side-by-side. This modification immediately changes the visual narrative, shifting the focus from individual subgroup comparison to total composition analysis.
import matplotlib.pyplot as plt #create stacked bar plot my_crosstab.plot(kind='bar', stacked=True, rot=0)

The resulting visualization offers a clear view of the total number of players per team. The height of the entire bar for Team B, for example, represents the total count of 4 players (3 F + 1 G). The individual colored segments within that bar show the breakdown by position. This structure inherently facilitates the visualization of the total count of elements for each unique value on the x-axis, making it powerful for compositional analysis.
When to Use Stacked vs. Grouped Bar Plots
Choosing between a stacked and a grouped bar plot depends entirely on the analytical question being addressed. Each type serves a distinct purpose in data visualization.
The Grouped Bar Plot is superior when the primary goal is to compare the magnitude of the subgroups directly across different categories. For instance, if the goal is to quickly identify which team has the highest count of ‘F’ players compared to all other teams, the side-by-side arrangement of the grouped plot makes this comparison immediate and precise. However, summing the totals for each team requires mental effort from the viewer, as the bars do not visually aggregate the counts.
Conversely, the Stacked Bar Plot is best utilized when the total magnitude of the primary category (the entire bar height) is as important as, or more important than, the individual subgroup counts. It is especially effective when visualizing compositional data, such as market share breakdown or demographic percentages. While it clearly shows the total and the composition, comparing the size of internal segments (e.g., comparing the size of the ‘F’ segment in Team A versus Team B) can be challenging because the segments do not share a common baseline.
Data analysts must strategically select the plot type that best supports their narrative. If the focus is on differential frequency counts across the row index of the crosstab, use grouped. If the focus is on the aggregate total and internal distribution, use stacked.
Further Customization and Best Practices for Visualization
While Pandas handles the initial rendering beautifully, applying standard visualization best practices ensures that the plots are informative and professional. Since Pandas plotting returns a Matplotlib Axes object, full control over the aesthetic elements is available. This is crucial for finalizing plots intended for reports or publications.
One essential customization involves labeling. Clear titles (using ax.set_title()) and descriptive axis labels (using ax.set_xlabel() and ax.set_ylabel()) transform a raw plot into a comprehensive figure. Furthermore, customizing the legend is often necessary, especially when dealing with many categorical variables. Placing the legend strategically (e.g., outside the plot area) prevents it from obscuring important data points.
For instance, to finalize the presentation, one might use the following extended workflow, capturing the Axes object for manipulation:
import matplotlib.pyplot as plt ax = my_crosstab.plot(kind='bar', stacked=True, rot=0, figsize=(8, 5)) ax.set_title('Player Position Breakdown by Team') ax.set_ylabel('Count of Players') plt.show()
This demonstrates the integration of Pandas’ convenience functions with Matplotlib’s granular control. By adhering to these practices—ensuring readability, accurate labeling, and appropriate plot choice—data analysts can confidently present their categorical frequency data derived from the initial Pandas cross-tabulation.
Cite this article
stats writer (2025). How to Easily Create a Bar Plot from a Pandas Crosstab. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-create-a-bar-plot-from-a-pandas-crosstab/
stats writer. "How to Easily Create a Bar Plot from a Pandas Crosstab." PSYCHOLOGICAL SCALES, 20 Nov. 2025, https://scales.arabpsychology.com/stats/how-to-create-a-bar-plot-from-a-pandas-crosstab/.
stats writer. "How to Easily Create a Bar Plot from a Pandas Crosstab." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-create-a-bar-plot-from-a-pandas-crosstab/.
stats writer (2025) 'How to Easily Create a Bar Plot from a Pandas Crosstab', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-create-a-bar-plot-from-a-pandas-crosstab/.
[1] stats writer, "How to Easily Create a Bar Plot from a Pandas Crosstab," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, November, 2025.
stats writer. How to Easily Create a Bar Plot from a Pandas Crosstab. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.