Table of Contents
Introduction to Heatmap Visualization in R
Creating a heatmap within the R programming language environment using the ggplot2 package is a sophisticated yet highly accessible method for representing complex datasets. A heatmap is a two-dimensional graphical representation of data where individual values contained in a matrix are represented as colors, providing an immediate visual summary of information. This technique is particularly effective for identifying clusters, trends, and outliers within high-dimensional data that might otherwise remain obscured in a standard tabular format. By leveraging the power of data visualization, researchers and analysts can communicate intricate patterns to stakeholders with greater clarity and impact.
The ggplot2 library, developed by Hadley Wickham, is based on the Grammar of Graphics, which provides a coherent system for describing and building graphs. Unlike basic plotting functions, ggplot2 allows for a layered approach to construction, where users can independently specify data, aesthetic mappings, and geometric objects. When generating a heatmap, we primarily utilize the geom_tile function to create a grid of colored rectangles. This structured approach ensures that the resulting visualization is not only aesthetically pleasing but also mathematically sound and reproducible across different datasets.
To begin the process of building an effective heatmap, the data must be meticulously organized. Typically, this involves transforming a standard data frame or matrix into a format that ggplot2 can interpret. This often requires a “tidy data” structure where each variable is a column, each observation is a row, and each value is a cell. Throughout this tutorial, we will explore the nuances of data preparation, scaling, and aesthetic customization to ensure your heatmap is both informative and professional. Whether you are analyzing genomic sequences, financial correlations, or automotive specifications, mastering this tool is essential for modern data science.
Understanding the mtcars Dataset for Visualization
In this tutorial, we will utilize the iconic mtcars dataset, which is built directly into the R environment. This dataset originates from the 1974 Motor Trend US magazine and comprises fuel consumption and ten aspects of automobile design and performance for 32 automobiles. Because it contains a mix of continuous and discrete variables, it serves as an excellent candidate for demonstrating how a heatmap can normalize and display diverse metrics on a single cohesive scale. Understanding the underlying structure of your data is the first step toward effective exploratory data analysis.
Before we can plot the data, we must inspect its initial state. The mtcars dataset is provided in a “wide” format, where various attributes such as miles per gallon (mpg), cylinder count (cyl), and horsepower (hp) are spread across different columns. While this format is convenient for human reading and certain statistical calculations, it is not immediately compatible with the aesthetic mapping requirements of a ggplot2 heatmap. By viewing the first few rows, we can see the range of values and the names of the observations, which will eventually form the axes of our plot.
#view first six rows of mtcars
head(mtcars)
# mpg cyl disp hp drat wt qsec vs am gear carb
#Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
#Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
#Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
#Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
#Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
#Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
As observed in the output above, the row names represent the specific car models, while the column headers represent the variables. To successfully generate a heatmap, we will need to pivot this data so that “variable name” and “value” become their own distinct columns. This structural transformation is a cornerstone of working within the Tidyverse ecosystem and ensures that the fill aesthetic in ggplot2 can be correctly mapped to the values of each car-variable pair. Proper data formatting is often the most time-consuming yet critical part of the data visualization workflow.
Data Transformation: Transitioning from Wide to Long Format
To facilitate the creation of the heatmap, we must “melt” the data frame from a wide format into a long format. This is achieved using the reshape2 package, a powerful tool for restructuring data in R. In the long format, every row will represent a single observation for a single variable for a single car. This redundancy is necessary for ggplot2 to iterate through each tile of the heatmap and assign the appropriate color based on the value. Without this step, the plotting engine would not be able to differentiate between the different metrics across the x-axis.
In addition to melting the data, we must explicitly capture the car names. In the original mtcars dataset, car names are stored as row names rather than a formal column. When we transform the data, these row names can sometimes be lost or become difficult to reference. By creating a dedicated “car” column and populating it with the repeated row names of the original dataset, we ensure that our y-axis in the heatmap will be properly labeled with the correct automobile models. This attention to detail prevents errors in data alignment and improves the overall integrity of the visualization.
#load reshape2 package to use melt() function library(reshape2) #melt mtcars into long format melt_mtcars <- melt(mtcars) #add column for car name melt_mtcars$car <- rep(row.names(mtcars), 11) #view first six rows of melt_mtcars head(melt_mtcars) # variable value car #1 mpg 21.0 Mazda RX4 #2 mpg 21.0 Mazda RX4 Wag #3 mpg 22.8 Datsun 710 #4 mpg 21.4 Hornet 4 Drive #5 mpg 18.7 Hornet Sportabout #6 mpg 18.1 Valiant
Now that the data is in the long format, we can see that each row contains a specific variable (like mpg), the value associated with it, and the car it belongs to. This “tidy” structure is the prerequisite for the ggplot function. It allows us to map the “variable” column to the x-axis, the “car” column to the y-axis, and the “value” column to the fill aesthetic. This logical mapping is what transforms a simple table into a multi-dimensional heatmap, allowing for rapid comparison across different categories.
Generating the Initial Heatmap and Identifying Limitations
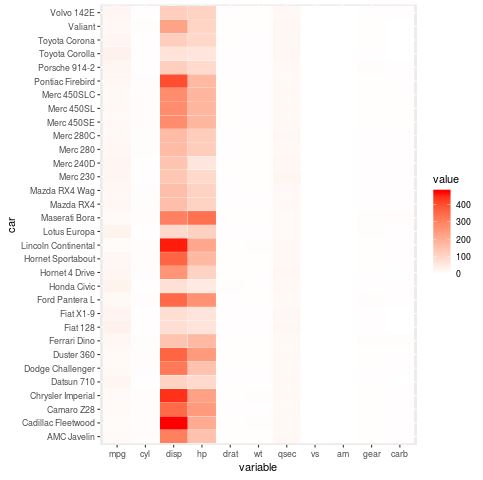
With our data correctly formatted, we can now invoke ggplot2 to generate the visual. We use the geom_tile geometric object, which is specifically designed for creating rectangular heatmaps. By specifying variable and car as our coordinates and value as our fill, we create a grid where each cell’s color is determined by its numerical magnitude. We also add a white border around each tile using the colour argument to improve the visual separation between data points, which is a common best practice in information design.
library(ggplot2) ggplot(melt_mtcars, aes(variable, car)) + geom_tile(aes(fill = value), colour = "white") + scale_fill_gradient(low = "white", high = "red")

Upon reviewing the first iteration of our heatmap, a significant issue becomes apparent. The variables in the mtcars dataset exist on vastly different scales. For instance, the displacement (disp) values often exceed 300, while the weight (wt) and quarter-mile time (qsec) values are much smaller. Because the color gradient is applied globally across all variables, the large values of “disp” dominate the scale, causing the variations in other important variables to appear washed out or indistinguishable. This is a common pitfall in data visualization when dealing with non-normalized data.
In technical terms, the dynamic range of the “disp” variable is so large that it compresses the color variation of the other columns into a very narrow segment of the color scale. To the viewer, it looks as though only one column has data, while the others are nearly identical. To fix this and make the heatmap truly useful for comparing relative performance across different car attributes, we must implement a form of normalization or feature scaling. This will allow each variable to contribute equally to the visual output, regardless of its original units of measurement.
Advanced Scaling Techniques for Comparative Analysis
To resolve the scaling disparity, we apply a technique known as Min-Max normalization. This process involves rescaling the values of each variable so they fall within a consistent range, typically between 0 and 1. By doing this, a high value for “mpg” will look just as “intense” on the heatmap as a high value for “disp,” allowing for a direct comparison of relative performance. We utilize the rescale function from the scales package and the ddply function from plyr to apply this transformation individually to each variable group within our melted data frame.
The ddply function is part of the “split-apply-combine” strategy for data analysis. It splits the data by the “variable” column, applies the rescale function to the values within that group, and then combines the results back into a single data frame. This ensures that the normalization is local to each metric rather than global across the entire dataset. This is a crucial step for ensuring that our heatmap remains factually accurate and provides a fair representation of the underlying statistical distribution of each car’s features.
#load libraries library(plyr) library(scales) #rescale values for all variables in melted data frame melt_mtcars <- ddply(melt_mtcars, .(variable), transform, rescale = rescale(value)) #create heatmap using rescaled values ggplot(melt_mtcars, aes(variable, car)) + geom_tile(aes(fill = rescale), colour = "white") + scale_fill_gradient(low = "white", high = "red")
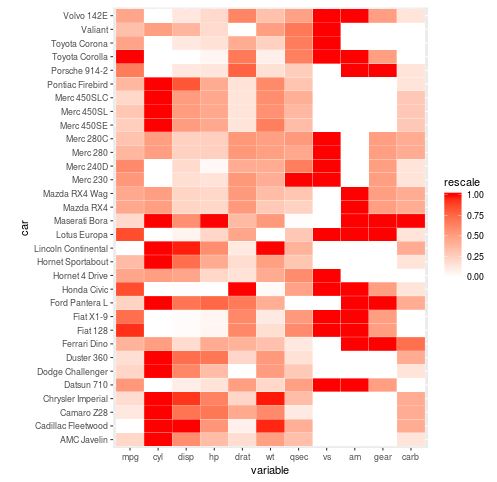
The resulting heatmap is significantly more informative. We can now clearly see patterns across all columns. For example, we might notice that cars with high “hp” (horsepower) tend to have lower “mpg” (miles per gallon), which is indicated by contrasting colors in those respective columns. By rescaling, we have transformed the heatmap from a simple display of raw numbers into a powerful tool for multivariate analysis. This allows the viewer to perform a visual correlation analysis across all dimensions of the dataset simultaneously.
Customizing Color Palettes and Visual Aesthetics
Color choice is a vital aspect of data visualization, as different palettes can evoke different interpretations and improve accessibility. While the default red-and-white gradient is functional, it may not always be the best choice for professional reports or presentations. In ggplot2, the scale_fill_gradient function allows for complete control over the color transition. By choosing a “steelblue” or other professional color schemes, we can make the heatmap more visually appealing and easier to read for individuals with specific color vision deficiencies.
When selecting a color scale, it is important to consider whether the data is sequential or diverging. In this case, since our rescaled values range from 0 (lowest) to 1 (highest), a sequential color scale is appropriate. A sequential scale uses variations in lightness and saturation of a single hue to represent increasing values. Using “white” as the low point and a dark “steelblue” as the high point creates a clear, intuitive progression that the human eye can easily categorize. This enhances the user experience of the data consumer.
#create heatmap using blue color scale
ggplot(melt_mtcars, aes(variable, car)) +
geom_tile(aes(fill = rescale), colour = "white") +
scale_fill_gradient(low = "white", high = "steelblue")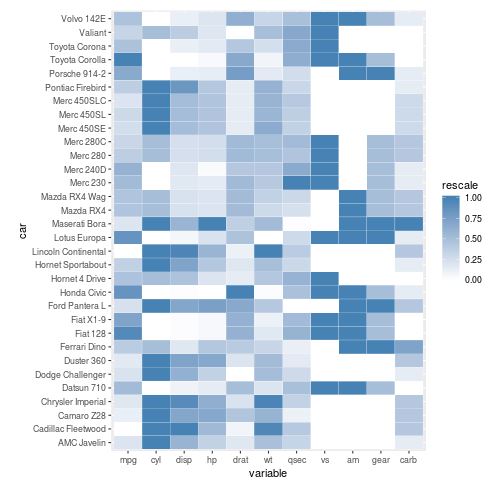
Furthermore, consistent use of color helps in establishing a brand or academic identity for your work. Beyond just aesthetics, the colour = “white” argument within geom_tile acts as a grid line, which helps the eye distinguish between adjacent cells that might have very similar color values. This subtle design choice prevents the heatmap from becoming a blurry “blob” of color and maintains the precision required for scientific visualization. Small adjustments in R can lead to significant improvements in the communicative power of your charts.
Optimizing Data Order for Enhanced Readability
By default, ggplot2 often orders categorical variables—like the car names on our y-axis—alphabetically. While this makes it easy to find a specific car, it rarely reveals meaningful patterns in the data. To make the heatmap more analytical, it is often beneficial to reorder the rows based on the values of a specific variable. For instance, ordering the cars by their “mpg” allows us to see how other variables change as fuel efficiency increases or decreases. This is a common technique in cluster analysis and data profiling.
In R, we can reorder factors using the reorder() function. By setting the “car” factor levels according to the “mpg” variable, we force ggplot2 to display the cars in a meaningful sequence. This transformation must happen before the data is melted or during a specific preprocessing step to ensure the y-axis reflects the intended logic. When the cars are sorted from highest to lowest “mpg,” the heatmap naturally develops a “flow” that makes trends much easier to spot at a glance.
#define car name as a new column, then order by mpg descending mtcars$car <- row.names(mtcars) mtcars$car <- with(mtcars, reorder(car, mpg)) #melt mtcars into long format melt_mtcars <- melt(mtcars) #rescale values for all variables in melted data frame melt_mtcars <- ddply(melt_mtcars, .(variable), transform, rescale = rescale(value)) #create heatmap using rescaled values ggplot(melt_mtcars, aes(variable, car)) + geom_tile(aes(fill = rescale), colour = "white") + scale_fill_gradient(low = "white", high = "steelblue")
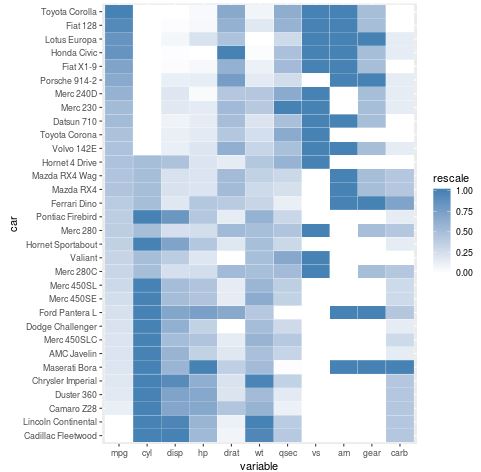
The visual impact of reordering cannot be overstated. With the cars now sorted by miles per gallon, we can observe clear blocks of color shifts. This helps in identifying correlations—for example, as we move up the y-axis toward more fuel-efficient cars, we might see a corresponding decrease in “cyl” (cylinders) and “disp” (displacement). This type of data storytelling is what separates a basic plot from a truly insightful analysis. Sorting turns a collection of tiles into a structured narrative about the automotive data.
Refining the Sorting Direction and Logic
Depending on the goals of your analysis, you may want to sort your data in either ascending or descending order. In R, this is easily adjusted by adding a negative sign to the variable within the reorder() function. Sorting in descending order (e.g., from highest “mpg” to lowest) can highlight the “top performers” at the top of the chart, which is often the most natural way for readers to consume information. This flexibility allows the analyst to tailor the heatmap to the specific questions being asked of the data.
Applying a descending sort often clarifies the relationship between variables that have an inverse relationship. If “mpg” is sorted descending, the heatmap might show a “diagonal” trend where other variables like “wt” (weight) increase as “mpg” decreases. These visual diagonals are key indicators for statisticians and data analysts when identifying strong linear or non-linear relationships. Mastery of the reorder function is a simple yet powerful way to enhance the usability of any categorical plot in ggplot2.
#define car name as a new column, then order by mpg descending mtcars$car <- row.names(mtcars) mtcars$car <- with(mtcars, reorder(car, -mpg)) #melt mtcars into long format melt_mtcars <- melt(mtcars) #rescale values for all variables in melted data frame melt_mtcars <- ddply(melt_mtcars, .(variable), transform, rescale = rescale(value)) #create heatmap using rescaled values ggplot(melt_mtcars, aes(variable, car)) + geom_tile(aes(fill = rescale), colour = "white") + scale_fill_gradient(low = "white", high = "steelblue")

By experimenting with different sorting variables, you can uncover different facets of the same dataset. For example, sorting by “hp” would emphasize the performance characteristics of the cars, while sorting by “wt” would highlight the physical dimensions. In multivariate statistics, being able to toggle between these views is essential for a holistic understanding of the data. The heatmap acts as a flexible canvas that can be reconfigured to suit various analytical perspectives with just a few lines of R code.
Finalizing the Visual: Removing Clutter and Chartjunk
The final stage of creating a professional heatmap involves “polishing” the aesthetics by removing unnecessary elements, a concept often championed by Edward Tufte as reducing chartjunk. In many cases, the axis labels are redundant if the row and column names are self-explanatory. Similarly, if the heatmap is intended for relative comparison rather than precise value lookup, the legend might be discarded to provide more space for the plot itself. This results in a cleaner, more modern look that focuses entirely on the data patterns.
In ggplot2, these modifications are handled by the theme() and labs() functions. The theme() function is incredibly versatile, allowing you to modify almost every non-data element of the plot, including the background, grid lines, and legend position. By setting legend.position = “none”, we remove the color scale key. Using labs(x = “”, y = “”) effectively strips the axis titles while keeping the car names and variable names. This creates a minimalist aesthetic that is often preferred in data journalism and high-end reporting.
#create heatmap with no axis labels or legend ggplot(melt_mtcars, aes(variable, car)) + geom_tile(aes(fill = rescale), colour = "white") + scale_fill_gradient(low = "white", high = "steelblue") + labs(x = "", y = "") + theme(legend.position = "none")

A finalized, clean heatmap is a testament to the power of R and ggplot2. By following these steps—preparing the data, normalization, choosing a color palette, reordering for logic, and cleaning the final output—you transform raw numbers into a compelling visual story. This workflow is highly adaptable and can be scaled to much larger datasets, such as gene expression matrices or correlation tables in financial modeling. With these skills, you are well-equipped to perform high-level data visualization and communication in any technical field.
Cite this article
stats writer (2026). How to Create Heatmaps in R with ggplot2: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-create-a-heatmap-in-r-using-ggplot2/
stats writer. "How to Create Heatmaps in R with ggplot2: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-i-create-a-heatmap-in-r-using-ggplot2/.
stats writer. "How to Create Heatmaps in R with ggplot2: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-create-a-heatmap-in-r-using-ggplot2/.
stats writer (2026) 'How to Create Heatmaps in R with ggplot2: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-create-a-heatmap-in-r-using-ggplot2/.
[1] stats writer, "How to Create Heatmaps in R with ggplot2: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Create Heatmaps in R with ggplot2: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.