Table of Contents
The normal distribution, often referred to as the Gaussian distribution, serves as the cornerstone of modern statistics and data analysis. Within the R programming language, a suite of four primary functions—dnorm, pnorm, qnorm, and rnorm—provides researchers with the necessary tools to calculate, simulate, and visualize these distributions with precision. These functions are indispensable for performing statistical inference, as they allow for the seamless transition between theoretical probability models and empirical data observations.
Understanding these functions is essential for any data scientist or statistician working in R. Each function targets a specific aspect of the distribution: density, cumulative probability, quantiles, or random sampling. By mastering these utilities, analysts can conduct complex tasks such as hypothesis testing, power analysis, and risk modeling. This comprehensive guide will detail the mechanics of each function, providing clarity on their syntax and practical applications within the broader context of statistical research and data visualization.
The importance of the normal distribution stems from the central limit theorem, which suggests that the sum of many independent random variables tends toward a normal distribution, regardless of the original distribution of the variables themselves. Consequently, these four functions in R are frequently used across diverse fields, from psychology and biology to finance and engineering. In the following sections, we will explore how to implement these functions effectively to enhance your analytical workflows.
A Comprehensive Guide to dnorm, pnorm, qnorm, and rnorm in R
The normal distribution is characterized by its distinct bell-shaped curve and is defined by two primary parameters: the mean (μ) and the standard deviation (σ). This tutorial is designed to provide an in-depth explanation of how to manipulate this distribution using the specialized functions available in R. We will delve into the mathematical foundations and the programmatic implementation of dnorm, pnorm, qnorm, and rnorm, ensuring a robust understanding of their respective roles in data science.
Before applying these functions, it is crucial to recognize that R defaults to the standard normal distribution, where the mean is set to zero and the standard deviation is set to one. However, the flexibility of these functions allows users to specify any mean and standard deviation to fit their specific dataset. This versatility makes R an exceptionally powerful environment for statistical modeling, as it accommodates both theoretical exploration and the analysis of real-world phenomena that follow a normal pattern.
As we navigate through this guide, we will provide clear examples and code snippets to illustrate the utility of each function. Whether you are seeking to determine the likelihood of a specific observation, find a critical threshold for a confidence interval, or generate synthetic data for a simulation, the following sections will equip you with the technical expertise required to leverage the normal distribution effectively within your R scripts.
Exploring Probability Density with the dnorm Function
The dnorm function is designed to return the value of the probability density function (PDF) for a given set of parameters. Specifically, it calculates the height of the probability distribution at a specific random variable x. While the PDF value itself does not represent a probability for a continuous distribution, it is fundamental for understanding the relative likelihood of values and for constructing the visual representation of the distribution curve.
The syntax for dnorm requires the input value x, the mean, and the standard deviation. By evaluating dnorm across a range of values, an analyst can map the “spread” and “peak” of a distribution, which is vital for identifying the central tendency and the variability of the data. This is particularly useful when comparing different datasets to see which one exhibits higher kurtosis or variance.
Beyond simple calculations, dnorm is a primary tool for creating aesthetic and informative plots in R. By generating a sequence of values along the x-axis and calculating their corresponding densities, users can utilize the base plotting system or packages like ggplot2 to draw the iconic bell curve. The following code provides a practical look at how dnorm operates in different scenarios:
#find the value of the standard normal distribution pdf at x=0 dnorm(x=0, mean=0, sd=1) # [1] 0.3989423 #by default, R uses mean=0 and sd=1 dnorm(x=0) # [1] 0.3989423 #find the value of the normal distribution pdf at x=10 with mean=20 and sd=5 dnorm(x=10, mean=20, sd=5) # [1] 0.01079819
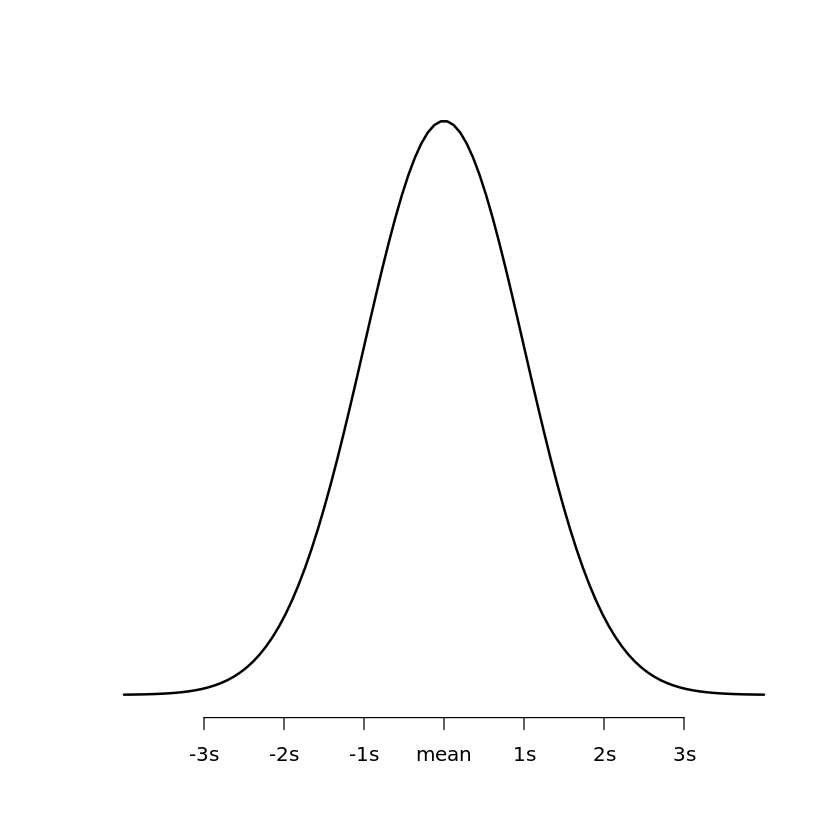
While pnorm is typically preferred for solving actual probability questions regarding ranges of values, dnorm remains the gold standard for visualizing the distribution. In the example below, we demonstrate how to use dnorm to generate a professional-grade plot that illustrates the standard deviations from the mean. This visualization technique is helpful for presenting findings to stakeholders who may require a visual context for statistical results.
#Create a sequence of 100 equally spaced numbers between -4 and 4
x <- seq(-4, 4, length=100)
#create a vector of values that shows the height of the probability distribution
#for each value in x
y <- dnorm(x)
#plot x and y as a scatterplot with connected lines (type = "l") and add
#an x-axis with custom labels
plot(x,y, type = "l", lwd = 2, axes = FALSE, xlab = "", ylab = "")
axis(1, at = -3:3, labels = c("-3s", "-2s", "-1s", "mean", "1s", "2s", "3s"))The resulting visualization provides a clear view of the mathematical symmetry inherent in the normal distribution. Analysts can see exactly where the majority of the data lies—specifically within three standard deviations of the center. This type of graphical analysis is often the first step in exploratory data analysis before moving on to more formal statistical tests.

Calculating Cumulative Probabilities via the pnorm Function
The pnorm function serves as the cumulative distribution function (CDF) for the normal distribution. Unlike dnorm, which provides the density at a point, pnorm calculates the total area under the curve to the left of a specific value q. This area represents the probability that a random variable from the distribution will be less than or equal to q. This is one of the most frequently used functions in R for conducting p-value calculations and general probability assessments.
Standard use of pnorm assumes a “lower tail” calculation, meaning it sums the probability from negative infinity up to the point q. However, many statistical questions require finding the probability of a value being greater than a certain threshold. In these instances, the lower.tail = FALSE argument can be used to calculate the area to the right of the point. This flexibility is essential for “greater-than” tests and for understanding the upper extremes of a dataset.
The syntax pnorm(q, mean, sd) is straightforward yet powerful. It allows for the rapid assessment of percentiles and likelihoods across any normal distribution without the need for manual Z-score conversion and table lookups. By automating this process, pnorm reduces the risk of human error and increases the efficiency of the analytical process, especially when dealing with large-scale simulations or automated reporting.
Practical Implementation of pnorm in Statistical Scenarios
To better understand how pnorm facilitates real-world analysis, let us consider several practical examples. These scenarios reflect common questions in fields such as biostatistics and quality control, where determining the probability of specific outcomes is a daily requirement. Each example utilizes the pnorm function to derive precise answers from defined population parameters.
Example 1: Suppose the height of males at a specific educational institution is normally distributed with a mean of 70 inches and a standard deviation of 2 inches. If we want to determine the percentage of males taller than 74 inches, we focus on the upper tail of the distribution.
#find percentage of males that are taller than 74 inches in a population with #mean = 70 and sd = 2 pnorm(74, mean=70, sd=2, lower.tail=FALSE) # [1] 0.02275013
The output indicates that approximately 2.275% of the male population at this school exceeds 74 inches in height. This information could be vital for health assessments or architectural planning within the facility. By adjusting the parameters, the same logic can be applied to any measurement following a normal curve.
Example 2: In a biological study, the weight of a specific species of otter is found to be normally distributed with a mean of 30 lbs and a standard deviation of 5 lbs. Researchers might need to know the probability of an otter weighing less than 22 lbs to identify potentially underweight individuals in the population.
#find percentage of otters that weight less than 22 lbs in a population with #mean = 30 and sd = 5 pnorm(22, mean=30, sd=5) # [1] 0.05479929
The calculation shows that about 5.48% of the species weigh less than 22 lbs. This allows researchers to set benchmarks for ecological health and individual wellness. The pnorm function thus acts as a bridge between raw data parameters and actionable ecological insights.
Example 3: In agricultural research, the height of plants in a specific region follows a normal distribution with a mean of 13 inches and a standard deviation of 2 inches. An analyst may need to find the percentage of plants that fall within a specific range, such as between 10 and 14 inches. This requires calculating the difference between two cumulative probabilities.
#find percentage of plants that are less than 14 inches tall, then subtract the #percentage of plants that are less than 10 inches tall, based on a population #with mean = 13 and sd = 2 pnorm(14, mean=13, sd=2) - pnorm(10, mean=13, sd=2) # [1] 0.6246553
The result demonstrates that approximately 62.47% of the plants fall within this height interval. This technique of subtracting one pnorm result from another is a standard method for calculating probabilities for any given range within a continuous distribution.
Identifying Quantiles and Z-Scores with qnorm
The qnorm function is the inverse of pnorm. It is known as the quantile function. While pnorm takes a value and returns a probability, qnorm takes a probability (or percentile) and returns the corresponding value from the distribution. This is exceptionally useful for determining critical values in hypothesis testing and for setting boundary conditions for confidence intervals.
In many statistical applications, analysts need to find the Z-score that corresponds to a specific quantile. For instance, if you are conducting a two-tailed test at a 95% confidence level, you would use qnorm to find the values that leave 2.5% in each tail. The syntax qnorm(p, mean, sd) facilitates this, where p is the desired probability level. If no mean or standard deviation is provided, R calculates the Z-score for the standard normal distribution.
The following examples demonstrate the versatility of qnorm in finding specific thresholds within a distribution. These values are essential for establishing the “cutoff” points in many statistical methodologies:
#find the Z-score of the 99th quantile of the standard normal distribution qnorm(.99, mean=0, sd=1) # [1] 2.326348 #by default, R uses mean=0 and sd=1 qnorm(.99) # [1] 2.326348 #find the Z-score of the 95th quantile of the standard normal distribution qnorm(.95) # [1] 1.644854 #find the Z-score of the 10th quantile of the standard normal distribution qnorm(.10) # [1] -1.281552
By using qnorm, researchers can easily convert theoretical probabilities into actual data units. This is particularly relevant in fields like finance for calculating Value at Risk (VaR) or in education for determining standardized test score cutoffs. It provides the mathematical precision needed to make objective decisions based on probability thresholds.
Simulating Stochastic Data using the rnorm Function
The rnorm function is used for random number generation. Specifically, it produces a vector of random variables that are sampled from a normal distribution with a specified mean and standard deviation. This function is a fundamental component of Monte Carlo simulations and other stochastic modeling techniques where researchers need to generate synthetic data that mimics real-world patterns.
Generating random data is essential for testing the robustness of statistical models. By creating datasets with known parameters, analysts can verify if their algorithms correctly identify underlying trends or if they are prone to overfitting. The rnorm function allows for the creation of datasets of any size, from small samples to massive populations containing millions of observations.
In the following code snippet, we illustrate how to use rnorm to create multiple distributions with different levels of variance. This comparison is helpful for understanding how the standard deviation affects the “width” or “dispersion” of the data points around the central mean.
#generate a vector of 5 normally distributed random variables with mean=10 and sd=2 five <- rnorm(5, mean = 10, sd = 2) five # [1] 10.658117 8.613495 10.561760 11.123492 10.802768 #generate a vector of 1000 normally distributed random variables with mean=50 and sd=15 narrowDistribution <- rnorm(1000, mean = 50, sd = 15) #generate a vector of 1000 normally distributed random variables with mean=50 and sd=25 wideDistribution <- rnorm(1000, mean = 50, sd = 25) #generate two histograms to view these two distributions side by side, specify #50 bars in histogram and x-axis limits of -50 to 150 par(mfrow=c(1, 2)) #one row, two columns hist(narrowDistribution, breaks=50, xlim=c(-50, 150)) hist(wideDistribution, breaks=50, xlim=c(-50, 150))
When viewing the resulting histograms, the impact of the standard deviation becomes immediately apparent. The distribution with an SD of 25 is significantly more “spread out” across the x-axis than the one with an SD of 15. Despite this difference in spread, both datasets remain centered around the specified mean of 50, demonstrating the reliability of rnorm in adhering to user-defined parameters.

Summary and Best Practices for Normal Distributions in R
The four functions discussed—dnorm, pnorm, qnorm, and rnorm—form a complete toolkit for managing normal distributions within the R environment. By understanding the distinction between density, cumulative probability, quantiles, and random sampling, you can approach any statistical problem with confidence. These tools are not just for theoretical exercises; they are the workhorses of professional data science and academic research.
When working with these functions, it is a best practice to always explicitly state your mean and standard deviation arguments to avoid unintended results from R‘s default standard normal settings. Additionally, when using rnorm for reproducible research, it is highly recommended to use the set.seed() function. This ensures that the “random” numbers generated are the same every time the code is run, which is crucial for peer review and debugging.
In conclusion, the ability to manipulate the normal distribution is a vital skill. Whether you are visualizing a PDF with dnorm, calculating probabilities with pnorm, identifying critical thresholds with qnorm, or simulating data with rnorm, these functions provide the mathematical rigor required for high-quality analysis. As you continue your journey in statistics, you will find these utilities to be some of the most frequently used and valuable assets in your R programming library.
Cite this article
stats writer (2026). How to Use dnorm, pnorm, qnorm, and rnorm in R for Normal Distribution Analysis. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-the-purpose-of-dnorm-pnorm-qnorm-and-rnorm-in-r-and-how-can-they-be-used-to-assist-with-statistical-analysis/
stats writer. "How to Use dnorm, pnorm, qnorm, and rnorm in R for Normal Distribution Analysis." PSYCHOLOGICAL SCALES, 2 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-the-purpose-of-dnorm-pnorm-qnorm-and-rnorm-in-r-and-how-can-they-be-used-to-assist-with-statistical-analysis/.
stats writer. "How to Use dnorm, pnorm, qnorm, and rnorm in R for Normal Distribution Analysis." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-the-purpose-of-dnorm-pnorm-qnorm-and-rnorm-in-r-and-how-can-they-be-used-to-assist-with-statistical-analysis/.
stats writer (2026) 'How to Use dnorm, pnorm, qnorm, and rnorm in R for Normal Distribution Analysis', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-the-purpose-of-dnorm-pnorm-qnorm-and-rnorm-in-r-and-how-can-they-be-used-to-assist-with-statistical-analysis/.
[1] stats writer, "How to Use dnorm, pnorm, qnorm, and rnorm in R for Normal Distribution Analysis," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Use dnorm, pnorm, qnorm, and rnorm in R for Normal Distribution Analysis. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.