Table of Contents
Comprehensive Overview of the Q-Q Plot in Statistical Analysis
In the realm of exploratory data analysis, the Q-Q plot, or quantile-quantile plot, serves as a fundamental graphical tool used to compare the distributions of two datasets or to compare a sample dataset against a theoretical distribution. This visualization is particularly indispensable when researchers need to determine whether a specific set of observations originates from a population that follows a normal distribution. While many statistical procedures, including ANOVA and t-tests, rely on the assumption of normality, the Q-Q plot provides an intuitive, non-formal method to assess this assumption before proceeding with parametric testing.
The core utility of this plot lies in its ability to reveal not just whether a distribution is non-normal, but also the specific nature of the deviation. By plotting quantiles against one another, the Q-Q plot allows analysts to identify characteristics such as skewness, kurtosis, and the presence of heavy or light tails. Unlike a histogram, which can be sensitive to the choice of bin width, the quantile-based approach provides a more robust and granular view of the data’s behavior, especially at the extremes of the distribution. This makes it an essential part of the diagnostic toolkit for anyone working with the R programming language.
Furthermore, the Q-Q plot facilitates the identification of an outlier or a cluster of anomalous data points that might disproportionately influence statistical models. If the data points follow a straight diagonal line, it suggests that the two distributions being compared are similar. Conversely, systematic departures from this line indicate that the sample data may require transformation or that a non-parametric alternative to a standard test should be considered. This visual check is often the first step in ensuring the integrity of a statistical inference.
Theoretical Foundations: Quantiles and Distributional Assumptions
To fully grasp the mechanics of a Q-Q plot, one must first understand the concept of a quantile. In statistics, quantiles are cut points dividing the range of a probability distribution into contiguous intervals with equal probabilities. For instance, the 0.5 quantile is the median, representing the value below which 50% of the data reside. In the context of a Q-Q plot, we compare the observed quantiles from our sample against the expected quantiles of a theoretical distribution, most commonly the normal distribution.
The construction of the plot involves ranking the sample data from smallest to largest and calculating the corresponding percentile for each value. These sample percentiles are then mapped to the values that would be expected if the data were perfectly distributed according to the theoretical model. If the sample is drawn from the theoretical distribution, the relationship between the sample and theoretical quantiles will be linear. This linear relationship is what researchers look for when evaluating the goodness of fit between their observed data and the assumed model.
While the normal distribution is the default benchmark for many researchers, it is important to note that a Q-Q plot can be used to compare any two probability distributions. For example, an engineer might use a Q-Q plot to check if failure times follow a Weibull distribution or an exponential distribution. This flexibility makes the Q-Q plot a versatile instrument for validating the assumptions of various advanced econometric and scientific models.

The Step-by-Step Workflow for Generating a Q-Q Plot
The systematic creation of a Q-Q plot in R follows a logical sequence of operations designed to ensure data accuracy and visual clarity. The process typically begins with data acquisition and preparation, where a dataset is either imported from an external source, such as a CSV file, or generated within the R environment for simulation purposes. Once the data is available, it must be properly structured—usually as a numeric vector—to be compatible with R’s internal plotting functions.
The standard procedural steps include the following:
- Import the Dataset: Load your data into the R environment using functions like
read.csv()orread.table()to ensure the dataset is ready for manipulation. - Sort the Data: Arrange the observations in ascending order. This is a prerequisite for calculating order statistics and empirical quantiles.
- Calculate Quantiles: Utilize the
quantile()function to determine the specific points in the data that correspond to various probability thresholds. - Generate the Plot: Use the
qqnorm()function to plot the sample data against the theoretical normal distribution. - Add a Reference Line: Apply the
qqline()function to superimpose a diagonal line that represents a perfect fit, facilitating easier visual interpretation. - Labeling and Customization: Enhance the visualization by adding descriptive titles, axis labels, and color-coding to make the findings clear to stakeholders.
By following this structured approach, analysts can maintain a high degree of reproducibility in their workflows. Each step, from the initial sort to the final aesthetic adjustment, contributes to a more accurate diagnostic of the data’s distributional properties. This rigor is essential for professional reporting in fields such as data science, finance, and academic research.
Utilizing Built-in R Functions for Normality Assessment
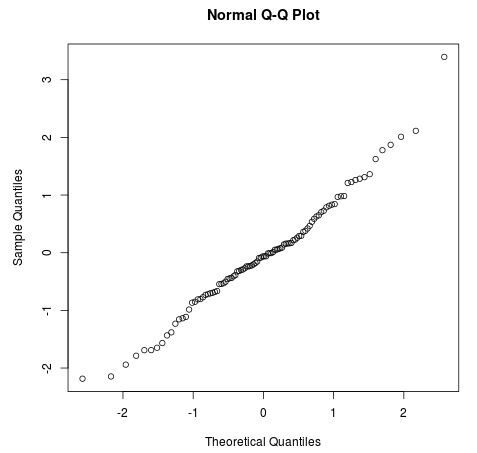
The R programming language simplifies the generation of these visualizations through highly optimized built-in functions. The primary tool for this task is qqnorm(), which automatically calculates the necessary theoretical quantiles and pairs them with the sample data. To demonstrate this, we can generate a random variable that follows a normal distribution and observe how it appears on the plot. Setting a seed ensures that the pseudorandom number generation is consistent across different sessions.
#make this example reproducible set.seed(11) #generate vector of 100 values that follows a normal distribution data <- rnorm(100) #create Q-Q plot to compare this dataset to a theoretical normal distribution qqnorm(data)

While the qqnorm() function creates the scatter plot, it is often difficult to judge the degree of linearity without a reference. The qqline() function addresses this by drawing a line through the first and third quartiles. If the data is normally distributed, the points should cluster tightly around this line. This combination of functions provides a powerful visual confirmation of whether the sample matches the theoretical expectations of the normal distribution.
#create Q-Q plot qqnorm(data) #add straight diagonal line to plot qqline(data)
Visualizing Deviations in Non-Normal Distributions
One of the most valuable aspects of the Q-Q plot is its ability to highlight when a dataset deviates from the normal distribution. For example, if we examine data following a gamma distribution, which is inherently skewed, the resulting plot will show a distinct curve rather than a straight line. This curvature indicates that the quantiles of the sample do not scale linearly with the quantiles of a normal distribution, signaling that parametric tests assuming normality would be inappropriate.
#make this example reproducible set.seed(11) #generate vector of 100 values that follows a gamma distribution data <- rgamma(100, 1) #create Q-Q plot to compare this dataset to a theoretical normal distribution qqnorm(data) qqline(data)

Similarly, the Chi-Square distribution often exhibits significant departures from normality, particularly when the degrees of freedom are low. By plotting such data, we can observe “heavy tails” or “light tails,” where the extreme values are either more or less frequent than what a normal distribution would predict. These visual cues are essential for a statistician to determine if the data requires a log transformation or other adjustments before analysis.
#make this example reproducible set.seed(11) #generate vector of 100 values that follows a Chi-Square distribution data <- rchisq(100, 5) #create Q-Q plot to compare this dataset to a theoretical normal distribution qqnorm(data) qqline(data)

Customizing Aesthetics for Professional Visualizations
For technical reports and academic publications, the default aesthetics of R’s plotting functions may not be sufficient. R allows for extensive customization of the Q-Q plot, enabling users to modify titles, axis labels, point colors, and line styles. These modifications improve the readability and professionalism of the output, ensuring that the visual evidence for or against normality is communicated effectively to the audience.
The qqnorm() function accepts several graphical parameters, such as main for the title, xlab and ylab for the axis labels, and col for the color of the data points. By choosing distinct colors like ‘steelblue’, the data points become more prominent against the background. Such visual enhancements are not merely cosmetic; they help distinguish between multiple datasets or highlight specific trends within a single dataset.
#make this example reproducible
set.seed(11)
#generate vector of 100 values that follows a normal distribution
data <- rnorm(100)
#create Q-Q plot
qqnorm(data, main = 'Q-Q Plot for Normality', xlab = 'Theoretical Dist',
ylab = 'Sample dist', col = 'steelblue')
Furthermore, the reference line added by qqline() can be customized using the lwd (line width) and lty (line type) parameters. A dashed red line with increased thickness is often used to provide a clear contrast against the sample data points. This level of detail in data visualization ensures that the diagnostic line is unmistakable, helping the viewer quickly assess the linear relationship between the sample and the theoretical distribution.
qqline(data, col = 'red', lwd = 2, lty = 2)

Interpreting Results and Identifying Distributional Anomalies
Interpreting a Q-Q plot requires a careful eye for patterns in the scatter of points. When points fall along the diagonal line, we conclude that the sample is consistent with the normal distribution. However, if the points curve upward at both ends (an “S” shape), it indicates that the distribution has heavy tails, meaning there are more extreme values than expected. Conversely, a downward curve at the ends suggests light tails.
An outlier is easily spotted as a point that sits significantly far from the general trend of the diagonal line. Identifying these points is crucial because they can exert undue influence on the mean and standard deviation of the dataset. By examining the Q-Q plot, a researcher can decide whether to investigate these anomalies further or apply robust statistical methods that are less sensitive to extreme values.
Beyond simple normality, the Q-Q plot can reveal skewness. If the points form a curve that stays above or below the line for a large portion of the range, the data may be positively or negatively skewed. Understanding these nuances allows for a more sophisticated interpretation of the data, moving beyond a simple “normal vs. non-normal” binary and providing deeper insights into the underlying process that generated the observations.
Formal Statistical Tests for Distributional Validation
While the Q-Q plot is an excellent tool for visual inspection, it is often used in conjunction with formal statistical hypothesis tests to provide a more objective conclusion. These tests provide a p-value that quantifies the evidence against the null hypothesis of normality. Relying on both visualization and formal testing creates a more rigorous and defensible analysis.
Commonly used tests include:
- Shapiro-Wilk Test: Frequently cited as one of the most powerful tests for normality, particularly for smaller sample sizes.
- Anderson-Darling Test: A modification of the Kolmogorov-Smirnov test that gives more weight to the tails of the distribution, making it highly sensitive to extreme deviations.
- Kolmogorov-Smirnov Test: A non-parametric test used to compare a sample with a reference probability distribution, though it is often considered less sensitive than the Shapiro-Wilk test for normality.
In conclusion, the Q-Q plot in R is a versatile and essential component of the data analysis pipeline. By combining the visual intuition of quantile-based plotting with the objective rigor of formal statistical tests, analysts can confidently verify their distributional assumptions. This dual approach ensures that subsequent statistical models are built on a solid foundation, leading to more accurate and reliable conclusions.
Cite this article
stats writer (2026). How to Create and Interpret Q-Q Plots in R for Data Analysis. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-the-process-for-creating-and-interpreting-a-q-q-plot-in-r/
stats writer. "How to Create and Interpret Q-Q Plots in R for Data Analysis." PSYCHOLOGICAL SCALES, 4 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-the-process-for-creating-and-interpreting-a-q-q-plot-in-r/.
stats writer. "How to Create and Interpret Q-Q Plots in R for Data Analysis." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-the-process-for-creating-and-interpreting-a-q-q-plot-in-r/.
stats writer (2026) 'How to Create and Interpret Q-Q Plots in R for Data Analysis', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-the-process-for-creating-and-interpreting-a-q-q-plot-in-r/.
[1] stats writer, "How to Create and Interpret Q-Q Plots in R for Data Analysis," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Create and Interpret Q-Q Plots in R for Data Analysis. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.