Table of Contents
Understanding the Fundamentals of ANOVA and Its Statistical Requirements
The Analysis of Variance, commonly known as ANOVA, represents one of the most vital tools in the arsenal of inferential statistics. Its primary purpose is to allow researchers to compare the means of three or more independent groups to determine if at least one group mean is significantly different from the others. While a t-test is suitable for comparing two groups, ANOVA is preferred for multiple groups because it controls the Type I error rate that would otherwise inflate if multiple pairwise comparisons were conducted. By analyzing the ratio of variance between groups to the variance within groups, the F-test provides a single global assessment of statistical significance.
However, the mathematical validity of the F-distribution used in ANOVA relies on specific characteristics of the underlying data. These characteristics, known as statistical assumptions, must be verified before the results can be interpreted with confidence. If these assumptions are violated, the resulting p-value may be misleading, potentially leading to a false rejection of the null hypothesis or an inability to detect a true effect. Therefore, rigorous diagnostic checking is an essential phase of any data analysis workflow involving parametric tests.
There are four primary assumptions that researchers must consider: normality, homogeneity of variance, independence of observations, and random sampling. Each of these plays a distinct role in ensuring that the standard error is calculated correctly and that the test maintains its theoretical power. In this guide, we will explore these assumptions in depth, demonstrating how to test them using the R programming language and discussing the appropriate remedial measures when assumptions are not met.
The Critical Role of the Normality Assumption
The normality assumption in ANOVA dictates that the residuals (the differences between the observed values and the group means) should follow a normal distribution. This is important because the F-test is a parametric test that assumes the sampling distribution of the mean is normal. In many cases, if the sample size is sufficiently large, the Central Limit Theorem suggests that the sampling distribution will tend toward normality even if the underlying population data does not. However, for smaller datasets, severe skewness or heavy tails can significantly bias the results.
To evaluate this assumption, statisticians often employ a combination of visual inspection and formal hypothesis testing. Visual tools such as histograms and Q-Q plots (quantile-quantile plots) are highly recommended as they provide a nuanced view of how the data deviates from the expected distribution. While formal tests provide a definitive p-value, they can sometimes be overly sensitive in large samples or under-powered in small samples, making graphical assessment a vital component of the diagnostic process.
In the context of a weight-loss study, for instance, we might expect the amount of weight lost to be normally distributed within each treatment group. If one group contains extreme outliers or exhibits a non-symmetrical distribution, the mean may not accurately represent the central tendency of that group. This distortion can lead to inaccurate comparisons between the different weight-loss programs being evaluated, ultimately compromising the internal validity of the entire experiment.
Implementing Normality Checks in the R Environment
When using the R programming language to perform an ANOVA, the first step is typically to fit the model and then extract the residuals for testing. The following example demonstrates how to simulate a dataset and fit a one-way ANOVA model to investigate the effects of different programs on a dependent variable. By using reproducible code, researchers can ensure that their diagnostic steps are transparent and easily shared with collaborators.
#make this example reproducible
set.seed(0)
#create data frame
data <- data.frame(program = rep(c("A", "B", "C"), each = 30),
weight_loss = c(runif(30, 0, 3),
runif(30, 0, 5),
runif(30, 1, 7)))
#fit the one-way ANOVA model
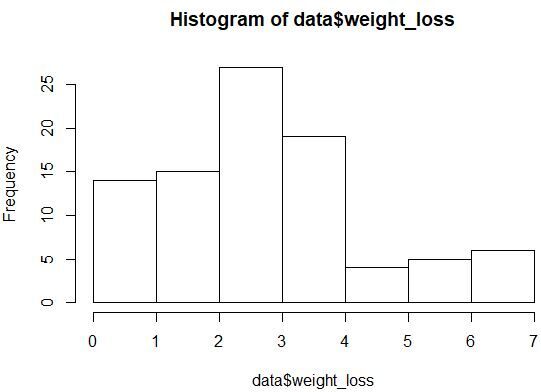
model <- aov(weight_loss ~ program, data = data)After fitting the model, a histogram of the data or the residuals can provide an initial glimpse into the distribution. A perfectly normal distribution would appear as a symmetric, bell-shaped curve. In real-world data, however, the distribution is rarely perfect. The data visualization produced by the following code helps in identifying obvious departures from normality, such as bimodal patterns or extreme clustering.
#create histogram
hist(data$weight_loss)

As noted in the visual output, the distribution might not perfectly align with the theoretical normal curve. To gain a more detailed perspective, the Q-Q plot is employed. This plot compares the quantiles of the sample data against the quantiles of a theoretical normal distribution. If the data points lie along the diagonal reference line, the assumption is generally considered satisfied. Significant deviations at the ends of the line suggest that the data has “fat” or “thin” tails compared to a normal distribution.
#create Q-Q plot to compare this dataset to a theoretical normal distribution qqnorm(model$residuals) #add straight diagonal line to plot qqline(model$residuals)

Formal Statistical Testing for Normality
To complement visual inspections, researchers often utilize formal normality tests. One of the most widely used is the Shapiro-Wilk test, which evaluates the null hypothesis that a sample comes from a normally distributed population. A high p-value (typically greater than 0.05) suggests that we fail to reject the null hypothesis, meaning the normality assumption holds. Conversely, a low p-value indicates significant evidence that the data is non-normal.
#Conduct Shapiro-Wilk Test for normality shapiro.test(data$weight_loss) #Shapiro-Wilk normality test # #data: data$weight_loss #W = 0.9587, p-value = 0.005999
In this specific example, the p-value of 0.005999 is below the standard significance level of 0.05, suggesting that the normality assumption has been violated. However, it is important to remember that ANOVA is relatively robust to minor violations of normality, especially when group sizes are equal and sufficiently large. The decision to proceed or pivot to a different test depends on the severity of the violation and the overall goals of the research.
If the violation is severe, researchers have several options. They may choose to apply a data transformation, such as a log or square root transformation, to stabilize the distribution. Alternatively, they can utilize non-parametric statistics, which do not rely on the assumption of normality. The Kruskal-Wallis test is the standard non-parametric alternative to the one-way ANOVA and is based on the ranks of the data rather than the actual values.
Assumption of Homogeneity of Variance
The second major assumption is homogeneity of variance, also known as homoscedasticity. This assumption requires that the variance within each of the groups being compared is approximately equal. ANOVA is designed to test for differences in means, but it uses the pooled within-group variance as a baseline. If one group has a much larger variance than the others, the pooled estimate becomes skewed, which can lead to an inaccurate F-statistic and an increased risk of Type II errors (failing to detect a real difference).
Checking for equal variances is particularly crucial when sample sizes are unequal. When group sizes are balanced, ANOVA is fairly resilient to heteroscedasticity. However, if the group with the smallest sample size also has the largest variance, the test becomes overly liberal, leading to a higher-than-expected rate of false positives. Conversely, if the largest group has the largest variance, the test becomes too conservative, making it harder to find significant results even when they exist.
To assess this assumption, researchers commonly use boxplots to visually compare the spread of data across groups. A formal test, such as Bartlett’s test or Levene’s test, can also be applied. While Bartlett’s test is powerful, it is also very sensitive to departures from normality. Levene’s test is often preferred in practice because it is more robust to non-normal data, providing a more reliable assessment of variance equality in diverse datasets.
Visualizing and Testing Variance Equality in R
In R, the boxplot() function provides an intuitive way to compare the distributions of different groups. The vertical length of the “box” represents the interquartile range (IQR), which is a measure of statistical dispersion. If the boxes for the various programs have drastically different heights, it serves as a visual indicator that the homogeneity of variance assumption may be at risk.
#Create box plots that show distribution of weight loss for each group boxplot(weight_loss ~ program, xlab='Program', ylab='Weight Loss', data=data)

Following the visual check, Bartlett’s test can be conducted to provide a formal statistical conclusion. This test checks the null hypothesis that all input populations have equal variances. If the p-value is significant, we conclude that the variances are not equal, necessitating a change in the analytical approach.
#Conduct Bartlett's Test for homogeneity of variances bartlett.test(weight_loss ~ program, data=data) #Bartlett test of homogeneity of variances # #data: weight_loss by program #Bartlett's K-squared = 8.2713, df = 2, p-value = 0.01599
In our example, the p-value of 0.01599 is less than 0.05, indicating that the assumption of equal variances is violated. When this occurs, one common solution is to use Welch’s ANOVA. Unlike the standard ANOVA, Welch’s version does not assume equal variances and adjusts the degrees of freedom to provide a more accurate p-value. This ensures that the results remain valid even when the groups exhibit different levels of dispersion.
The Paramount Importance of Independence
Perhaps the most critical assumption of ANOVA is the independence of observations. This assumption implies that the data points in one group are not influenced by the data points in another group, and that each individual observation within a group is independent of the others. Violations of independence can lead to a severe underestimation of the standard error, which artificially inflates the F-statistic and makes the results appear much more significant than they actually are.
Independence is largely a matter of experimental design rather than statistical testing. For example, if you were measuring the test scores of students, and several students studied together in a group, their scores might be correlated, violating the independence assumption. Similarly, time-series data where measurements are taken from the same subject over time (repeated measures) requires a different statistical approach, such as a Repeated Measures ANOVA or a mixed-effects model.
Because there is no simple statistical test to “prove” independence, researchers must rely on rigorous randomization procedures during the data collection phase. Random sampling and random assignment to treatment groups are the best ways to ensure that the observations are truly independent. If the independence assumption is fundamentally compromised—for instance, due to a cluster effect that was not accounted for—the ANOVA results should be treated with extreme caution, and it is often better to redesign the experiment entirely.
Final Considerations for Reliable ANOVA Results
Conducting a one-way ANOVA is a powerful way to uncover differences between groups, but it is only as reliable as the assumptions upon which it is built. By systematically checking for normality, homogeneity of variance, and independence, you protect your research from common pitfalls and ensure that your conclusions are based on solid evidence-based practice. Using tools like R for diagnostic plotting and statistical testing makes this process both efficient and reproducible.
In summary, while the ANOVA is known for its robustness, researchers should never take its assumptions for granted. When normality is in doubt, visual inspection and the Shapiro-Wilk test provide clarity. When variances are unequal, Bartlett’s test and boxplots highlight the issue, allowing for the use of Welch’s ANOVA. Most importantly, ensuring independence through sound random sampling is the cornerstone of any high-quality statistical analysis.
By adhering to these rigorous standards, you can confidently report your findings, knowing that they reflect genuine patterns in your data rather than statistical artifacts. Whether you are comparing educational techniques, medical treatments, or marketing strategies, a well-validated ANOVA is an essential step toward achieving statistical significance and meaningful insights.
Cite this article
stats writer (2026). How to Check ANOVA Assumptions for Accurate Results. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-are-the-anova-assumptions-that-need-to-be-checked/
stats writer. "How to Check ANOVA Assumptions for Accurate Results." PSYCHOLOGICAL SCALES, 5 Mar. 2026, https://scales.arabpsychology.com/stats/what-are-the-anova-assumptions-that-need-to-be-checked/.
stats writer. "How to Check ANOVA Assumptions for Accurate Results." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-are-the-anova-assumptions-that-need-to-be-checked/.
stats writer (2026) 'How to Check ANOVA Assumptions for Accurate Results', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-are-the-anova-assumptions-that-need-to-be-checked/.
[1] stats writer, "How to Check ANOVA Assumptions for Accurate Results," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Check ANOVA Assumptions for Accurate Results. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.