Table of Contents
The Google Sheets Query function is one of the most powerful tools available for data analysis, leveraging a syntax similar to standard Structured Query Language (SQL). When dealing with large datasets, the ability to summarize information based on specific criteria is essential. This process, known as grouping and aggregation, allows users to transform raw data into meaningful insights, such as averages, sums, or counts for different categories. Understanding how to correctly implement the GROUP BY clause is the cornerstone of effective data summarization within the Google Sheets environment.
To successfully group and aggregate data using the Query function, you must specify the range containing your data set, followed by the query string itself. The query string dictates which columns are selected and how they are summarized. The core mechanism for summarizing categorical data is the combination of an aggregate function (like SUM() or AVG()) and the GROUP BY clause, which organizes the selected data based on the unique values in the specified column(s). This structure ensures that calculations are performed not on the entire column, but separately within each defined group.
The following syntax demonstrates the standard structure for implementing grouping and aggregation in a Google Sheets Query:
=query(A1:D12, "select B, avg(D) group by B", 1)
In this fundamental example, we are targeting the cell range A1:D12, which contains our raw data. The query string "select B, avg(D) group by B" instructs the function to select Column B (our grouping category) and to calculate the average of the numerical values found in Column D. Crucially, the GROUP BY B directive ensures that this average calculation is performed independently for every distinct value present in Column B. Without the GROUP BY clause, the function would attempt to calculate a single overall average for Column D, which would lead to an error because Column B is not summarized.
The final argument in the function, the number 1, is vital for defining the structure of your data input. This value indicates that your specified range (A1:D12) includes exactly 1 header row at the very top. This is essential because the Query function uses the data types and content of this first row to determine how to process the remaining rows. If your data set contains multiple header rows, or none at all, this number must be adjusted accordingly to ensure accurate data parsing and prevent unforeseen errors in your aggregated output. Always ensure this argument correctly reflects the structure of your input range.
Essential Aggregate Functions for Data Summarization
The power of the GROUP BY clause is realized through the application of aggregate functions. These functions operate on a set of rows and return a single summary value. While the previous example used avg() to find the arithmetic mean, the Query function supports a comprehensive set of functions necessary for diverse data analysis needs. Choosing the correct function depends entirely on the analytical question you are trying to answer regarding your data groups.
For instance, if you are tracking sales data grouped by region, using sum() would provide the total revenue generated per region, while count() would tell you the number of transactions processed per region. These functions are the mechanism by which raw data transforms into actionable intelligence, providing a high-level view of performance, trends, and distribution across distinct categories.
The following list details the primary aggregate functions fully supported within the Google Sheets Query syntax:
- avg(): Calculates the average (mean) value of a numeric column within each group.
- sum(): Calculates the total sum of a numeric column within each group.
- count(): Calculates the number of non-null records (rows) within each group. This is often used to determine group size.
- min(): Identifies the minimum (smallest) value within a numeric column for each group.
- max(): Identifies the maximum (largest) value within a numeric column for each group.
Mastery of these aggregate functions, combined with precise grouping, allows analysts to move beyond simple data listing into sophisticated reporting and comparative analysis. The subsequent examples illustrate how these principles work in practice, demonstrating both single-column and multi-column grouping techniques.
Practical Application: Grouping Data by a Single Column
The simplest yet most frequent use case for the GROUP BY clause involves aggregating metrics based on a single categorical criterion, such as grouping sales figures by product line or performance scores by team. This method provides immediate, clear summary statistics for each unique category present in the dataset.
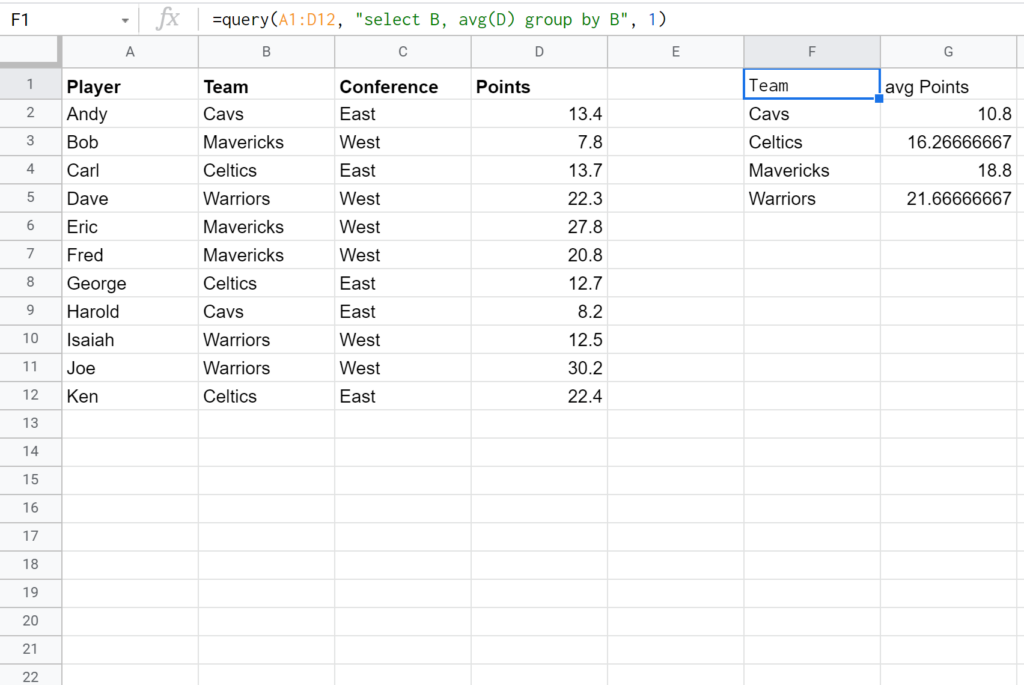
Consider a scenario where we have player data containing the team they play for and their individual points scored. We want to determine the average scoring performance for each team. We use the following Query formula to select the Team column and find the average of the Points column, ensuring the aggregation is segmented correctly by Team:

The resulting output is a concise summary table. By using avg(Points) group by Team, the system processes all rows belonging to the same team identifier together before calculating the mean value of the Points column for that specific team. This transformation turns a list of individual performance records into a comparative team performance report.
Analyzing the results generated by this query provides immediate actionable insights, revealing the typical scoring output expected from players associated with specific teams:
- The average points scored by players on the Cavs is 10.8.
- The average points scored by players on the Celtics is 12.7.
This single-column grouping approach is highly efficient for preliminary analysis and reporting, offering a clear distribution of numerical data across discrete groups. Further analysis can then be built upon this foundation, perhaps by sorting the results using the ORDER BY clause, which helps to rank teams based on their summarized performance metrics.
Advanced Grouping: Summarizing Data Across Multiple Criteria
While grouping by one column is straightforward, real-world data often requires aggregation across combinations of categories. This is achieved by listing multiple columns in the GROUP BY clause. When multiple columns are specified, the system creates unique groups based on the unique combination of values across all specified grouping columns.
For example, if we have data categorized by Team and also by Conference, and we want to find the maximum score achieved within each specific Team/Conference pairing, we must group by both dimensions. This allows for a more granular level of analysis, differentiating results based on hierarchical or intersecting categories.
The following formula demonstrates the selection of Team, Conference, and Points, followed by the calculation of the maximum points, grouped simultaneously by both Team and Conference:

In this multi-column grouping scenario, the max() aggregate function is applied. Instead of finding the overall maximum point score for, say, the Cavs team regardless of location, the query isolates the maximum score achieved by a Cavs player specifically within the East Conference. This is crucial for reports where context, defined by the second grouping column, drastically alters the interpretation of the aggregated statistic.
The outcome provides highly specific data points:
- The max points scored by any player on the Cavs team in the East Conference is 13.4.
- The max points scored by any player on the Celtics team in the East Conference is 22.4.
This technique is indispensable when working with complex datasets where results must be partitioned by intersecting categories, ensuring that the aggregation is relevant to the most precise categorical definition available. Note that the order in which columns are listed in the GROUP BY clause does not affect the final result set, but it often dictates the organizational logic of the output table.
Maintaining Query Integrity: Preventing #VALUE! Errors
One of the most common issues encountered when using the Query function with aggregation is the appearance of the dreaded #VALUE! error. This error almost always stems from a violation of the fundamental SQL aggregation rule: every column referenced in the SELECT statement must either be aggregated or be used as a grouping criterion.
When the Query function executes, it expects a single output value for every group it creates. If you include a non-aggregated column (e.g., a specific transaction ID) in the SELECT statement that is not also listed in the GROUP BY clause, the system will not know which of the potentially numerous individual values to return for that single summarized group, thus resulting in the error. This principle is often the source of confusion for new users migrating from simple data filtering to advanced aggregation.
To ensure a clean and valid aggregated result, every column explicitly listed in the SELECT clause of your query string must strictly adhere to one of the following two criteria:
- The column Has an aggregate function applied to it (e.g.,
sum(D),max(C)). This transforms multiple raw inputs into a single, summarized numerical output for the group. - The column Is included in the GROUP BY statement (e.g.,
group by B, C). This column defines the category and determines the boundaries of the groups, providing the necessary context for the aggregated values.
As long as each column reference in the select statement meets one of these two criteria, the Query function will execute successfully, avoiding the #VALUE! error and producing coherent, summarized results that align perfectly with the structure defined by your grouping columns. Always cross-reference your SELECT and GROUP BY clauses before executing the query.
Best Practices for Optimizing Grouped Queries
To maximize the efficiency and reliability of your Google Sheets Query function, especially when dealing with grouping and aggregation, several best practices should be observed. First and foremost, ensure that the data types in your columns are consistent and accurate. The Query function is strict; grouping by a column that contains mixed data types (e.g., text and numbers) will likely lead to unpredictable or incorrect group definitions, as the function struggles to interpret what constitutes a unique category.
Furthermore, careful construction of the SELECT statement is crucial. Only include columns necessary for the grouping criteria or the aggregated calculation. Including unnecessary columns that are neither aggregated nor grouped will immediately trigger an error, as discussed previously. Always prioritize readability in your query string; use clear column identifiers (A, B, C) and ensure clear separation between the SELECT, WHERE (if applicable), and GROUP BY clauses. Adding comments or notes outside the formula itself is also helpful for future maintenance.
When dealing with large datasets, performance management is key. Although the Query function is highly optimized, complex queries involving multiple aggregate functions across numerous grouping columns can slow down spreadsheet recalculation. If performance is an issue, consider pre-filtering the data using the WHERE clause before the GROUP BY clause executes. This reduces the number of rows the aggregation process must examine, significantly speeding up the final result generation.
Handling Date and Time Grouping Challenges
A common pitfall in aggregation involves how to correctly summarize data over specific time periods. If a column contains full timestamps (date and time), simply grouping by that column will result in hundreds or thousands of unique groups, as every second or minute might be unique. The goal is usually to group by broader categories, such as the year, month, or day of the week.
The Google Sheets Query language provides specialized functions for handling dates and times that must be employed within the query string itself. These functions—such as year(), month(), day(), quarter(), and dayOfWeek()—allow you to extract a standardized component of the date for grouping purposes. It is absolutely vital that any date function used in the SELECT statement is precisely repeated in the GROUP BY statement.
For example, to summarize sales (Column B) annually from a timestamp column (Column A), the syntax would be: "select year(A), sum(B) group by year(A)". Note that the month() function in Query is zero-indexed (0=January, 11=December), requiring careful adjustment if the output needs to match standard month numbers. Accurate use of these temporal functions ensures that data spanning long periods can be correctly consolidated and compared.
Cite this article
stats writer (2025). How to Group and Aggregate Data in Google Sheets Using Query. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-use-google-sheets-query-use-group-by/
stats writer. "How to Group and Aggregate Data in Google Sheets Using Query." PSYCHOLOGICAL SCALES, 5 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-use-google-sheets-query-use-group-by/.
stats writer. "How to Group and Aggregate Data in Google Sheets Using Query." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-use-google-sheets-query-use-group-by/.
stats writer (2025) 'How to Group and Aggregate Data in Google Sheets Using Query', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-use-google-sheets-query-use-group-by/.
[1] stats writer, "How to Group and Aggregate Data in Google Sheets Using Query," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Group and Aggregate Data in Google Sheets Using Query. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.