Table of Contents
The ability to perform sophisticated data analysis is paramount in modern business intelligence, and one of the most powerful tools available in the Google Workspace suite is the combination of the Google Sheets Query function and the concept of a Pivot Table. Creating a Pivot Table in Google Sheets directly is convenient, but leveraging the QUERY function offers unparalleled flexibility and precision. This approach allows users to dynamically organize, analyze, and summarize large datasets using SQL-like syntax, transforming raw information into insightful summaries effortlessly.
A Pivot Table serves as a dynamic summarization tool, helping users explore data dimensions quickly. When combined with the QUERY function, this process becomes automated and repeatable. Instead of manually selecting ranges and configuring settings through the standard interface, the QUERY function provides a single, formula-driven solution. This method is particularly beneficial when dealing with continuously updated data sources, as the resulting pivot structure will automatically refresh based on the formula’s criteria, ensuring that the analysis is always current and reliable. Mastering this syntax is crucial for anyone seeking to move beyond basic spreadsheet manipulation into advanced data management.
Leveraging the QUERY Function for Dynamic Pivots
While Google Sheets provides a native tool for creating pivots via the ‘Data’ menu, the QUERY function offers significant advantages, particularly regarding automation and complexity. The standard Pivot Table interface requires manual configuration of rows, columns, and values, and while effective, it generates static output that must be manually refreshed or recreated if the source data structure changes significantly. Conversely, a pivot structure built using the QUERY function is an active formula, meaning it adapts instantly to changes in the underlying dataset without user intervention, making your spreadsheets significantly more robust and scalable for automated reporting tasks.
The core power of the Google Sheets Query function lies in its use of the Google Visualization API Query Language, which closely resembles standard SQL. This powerful language allows for complex filtering (using where clauses), grouping (using group by), and, most importantly, cross-tabulation (using the pivot clause). By integrating these clauses, we move beyond simple data retrieval and into sophisticated data transformation. This level of control is essential for experts who need to precisely define how columns should intersect to display aggregated values, offering a level of granularity unmatched by the standard GUI tool.
The initial setup for a standard, interface-driven Pivot Table involves selecting the data range, navigating to ‘Data’ > ‘Pivot Table,’ and then dragging and dropping fields into the row, column, and value sections. While intuitive, this approach lacks the declarative power of the QUERY language. When using QUERY, you define the entire structure—including which column becomes rows, which column becomes intersecting columns, and which column is aggregated—all within one concise formula. This transition from graphical configuration to formulaic definition is the hallmark of truly advanced spreadsheet manipulation.
Understanding the Core Syntax of the Pivot Clause
To successfully create a dynamic pivot using the QUERY function, you must understand the specific components of the formula string. The string must include three fundamental SQL clauses: select, group by, and pivot. The select clause determines the aggregated data (the values inside the pivot), the group by clause defines the row headers (the primary categorization), and the pivot clause defines the column headers (the secondary categorization that spreads across the top of the table).
The general structure required for pivoting within the QUERY function follows this specific sequence: First, you specify the data range. Second, you provide the query string, which must contain the select statement identifying the column you wish to aggregate (e.g., sum(C)). Third, you use group by to select the column that will form the primary rows of the resulting table (e.g., group by A). Finally, and most critically, you use the pivot clause to define the column whose unique values will become the new column headers (e.g., pivot B). This structure ensures that for every unique combination of the row group (A) and the column pivot (B), the aggregated value (sum of C) is displayed.
The following syntax template illustrates the structure necessary to create a pivot table using the Google Sheets Query function. Note the mandatory inclusion of both the group by and pivot clauses, which are essential for defining the cross-tabulation structure. If the group by clause were omitted, the query would only return a single row representing the total aggregation across the entire dataset, pivoted by the defined column, losing the row-level categorization necessary for a meaningful pivot table.
You can use the following syntax to create a pivot table using Google Sheets Query:
=query(A1:C13, "select A, sum(C) group by A pivot B")
In this example, we choose column A to represent the rows of the pivot table, column B to represent the columns of the pivot table, and the values in column C to be displayed inside the pivot table, aggregated using the SUM() function.
The following practical scenarios demonstrate how to apply this versatile syntax in real-world data reporting.
Deconstructing the Query Formula for Pivoting
Let us analyze the components of the generalized formula: =QUERY(A1:C13, "select A, sum(C) group by A pivot B"). The first argument, A1:C13, defines the source range—the specific block of raw data we intend to analyze. It is crucial that this range encompasses all columns (A, B, and C) referenced in the query string. If the data range is dynamic or may expand, using an open-ended reference like A1:C is often better practice, ensuring new rows are automatically included in the analysis.
The second argument, the query string itself, is where the magic of transformation happens. "select A, sum(C) group by A pivot B" instructs Google Sheets to perform several actions simultaneously. First, select A identifies the column that contains the category labels for the rows (e.g., Product Names or Employee IDs). Second, sum(C) is the aggregation function applied to the values in column C. This determines what calculation is performed at the intersection of the row and column headers. While we use SUM here, this could be any aggregation function like COUNT, AVG, MAX, or MIN.
The combination of group by A and pivot B creates the multidimensional view. The group by A command ensures that all identical entries in column A are consolidated into a single row, establishing the primary categorization. Subsequently, pivot B takes every unique value found in column B and transforms it into a separate column header in the resulting pivot table. The aggregated value (sum(C)) then populates the cell corresponding to the intersection of the row category (A) and the column category (B). This entire process defines the powerful cross-tabulation capability inherent in SQL-like query languages.
Example 1: Summarizing Data Using the SUM Aggregation
In many financial or sales reporting contexts, the most common requirement is to calculate the total amount of a metric across different dimensions. The SUM() aggregation function is ideally suited for this purpose, providing a clear picture of total volume or value. Consider a dataset detailing sales transactions, where Column A lists the Product ID, Column B lists the Region of Sale, and Column C lists the Sales Amount. To determine the total sales broken down by both Product and Region, we utilize the SUM function within our query.
The following formula is engineered to calculate the aggregated total sales (Column C) grouped by the product (Column A) and pivoted by the region (Column B). This provides an instantaneous matrix showing how much each product contributed to the total revenue within specific geographical areas. This structure allows managers to quickly identify top-performing products and regions, or conversely, areas requiring greater strategic focus.
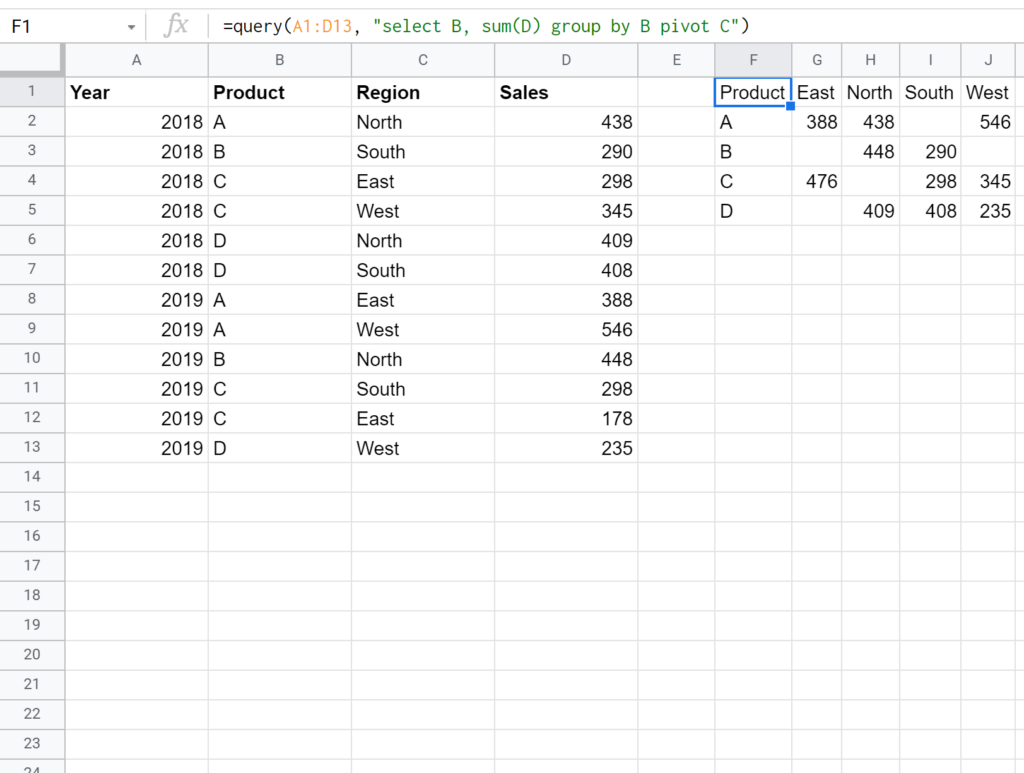
We can use the following formula to create a pivot table that displays the total sales by product and by region for a certain company, demonstrating the efficacy of the SUM function within the pivot structure:

This visual output immediately translates complex transaction data into actionable business insights. The row headers clearly list the different products (A, B, C, D), while the column headers categorize the data by region (East, North, West). The intersection points contain the precise sum of sales for that specific product-region combination, fulfilling the objective of comprehensive cross-tabulation reporting using the QUERY language.
Interpretation of Results: SUM() Example Deep Dive
Interpreting the results of a SUM() based Pivot Table is straightforward: each cell represents the combined total of the aggregated column (C, Sales) for the intersecting categories (Row A and Column B). For example, if we look at the row for Product A and the column for the East region, the value 388 signifies the cumulative sales revenue generated by Product A exclusively within the East region across the entire period covered by the source data range.
Analyzing the generated table provides immediate, valuable metrics. Observe the row corresponding to Product B: in both the East and West regions, the total sales figure is 0. This indicates either that Product B was not sold in those regions during the reporting period, or that the sales amount entries (Column C) associated with those specific product/region combinations were zero or non-numeric and thus excluded from the summation. This type of insight is critical for inventory management and sales strategy adjustment.
Furthermore, the high value of 476 for Product C in the East region suggests a strong performance or a focused sales effort in that specific market segment. Conversely, analyzing the total sales column (often generated implicitly by the select A part of the formula, showing the aggregated total for all pivoted columns) allows for a quick comparison of overall product performance. Understanding these intersections is essential for deriving meaning from the aggregated output generated by the query:
- The total sales of product A in the East region was 388. This represents the total monetary value generated by Product A specifically in the East geographic area.
- The total sales of product B in the East region was 0. This suggests a potential gap in sales coverage or product availability in the East market for Product B.
- The total sales of product C in the East region was 476. This indicates a very successful market penetration for Product C in the East region.
- The total sales of product D in the East region was 0. Similar to Product B, this warrants investigation into distribution or demand issues for Product D in the East.
And so on. These discrete totals provide the foundation for detailed performance reviews and forecasting models.
Example 2: Calculating Central Tendency with the AVG Aggregation
While SUM() is excellent for calculating totals, data analysis often requires understanding the central tendency—the typical or average performance. For this, the AVG() (Average) aggregation function is used. If we retain the same dataset structure (Product, Region, Sales Amount), replacing sum(C) with avg(C) fundamentally changes the meaning of the resulting Pivot Table. Instead of total revenue, each cell now represents the mean sales amount per transaction for that specific product-region combination.
Using the average provides a normalized view of the data, helping to mitigate the skew caused by a large number of low-value transactions or a small number of extremely high-value transactions. Analyzing averages allows businesses to assess consistency and typical performance, rather than just cumulative volume. For instance, a product might have high total sales (SUM), but if its average transaction value (AVG) is low, it suggests that the high total volume is achieved through many small sales, which might have implications for cost management.
The formula below demonstrates how to adjust the query string to incorporate the AVG() function, keeping the row and pivot definitions consistent to allow for direct comparison with the previous SUM() example. This highlights the flexibility of the QUERY function, where changing a single aggregation clause alters the entire reporting focus while maintaining the structural integrity of the pivot:

This new pivot table structure visually presents the average sales per transaction. Notice the significant change in values compared to the summation example. For example, Product C in the East region now displays 238 instead of 476. This implies that while the total sales volume was 476, this was achieved through two transactions (476 / 238 = 2), or a similar distribution of underlying raw data points, providing a crucial contextual difference between volume and typical transaction size.
Interpreting Average Sales Metrics
The interpretation of the AVG() results requires careful consideration of the source data structure. If the source data listed every individual sale, the average represents the mean value of those individual transactions. If the source data was already partially aggregated (e.g., weekly totals), the average represents the mean of those weekly totals. Assuming a standard transactional log where each row is a sale, the figures presented here define the average value of a single sale for that specific product/region combination.
In the new context, where Product C in the East region shows an average of 238, this means that, on average, every time Product C was sold in the East, the transaction value was 238. Comparing this average to other regions or products helps establish benchmarks for pricing and performance consistency. For instance, if Product C in the West region showed a significantly higher average sale value, it might indicate that sales in the West frequently involve bulk purchases or higher-priced variants.
The zero values (0) for Product B and Product D in the East region remain consistent with the SUM() example, indicating the absence of any transactions for those combinations. However, the non-zero values now represent normalized performance:
- The average sales of product A in the East region was 388. This suggests that Product A may have only had one transaction valued at 388, or that all transactions consistently averaged this high figure.
- The average sales of product B in the East region was 0. No recorded transactions.
- The average sales of product C in the East region was 238. This is a critical metric for understanding the typical transaction size for this profitable product/region pairing.
- The average sales of product D in the East region was 0. No recorded transactions.
And so on. These average figures provide insights into the quality and consistency of sales performance across the distinct dimensions defined by the pivot.
Conclusion: Advanced Data Transformation Capabilities
Utilizing the QUERY function in Google Sheets to construct pivot tables represents a substantial upgrade from relying solely on the built-in GUI tool. This method provides dynamic results, superior customization through advanced filtering (not shown here, but easily added using a where clause), and the ability to seamlessly switch between various aggregation metrics like SUM, AVG, COUNT, and others, all while maintaining a consistent and clean output structure. This formulaic approach is inherently more efficient for large-scale data management and automated reporting pipelines.
The ability to define rows using group by and intersecting columns using pivot allows for precise control over the resulting analytical report. Whether the goal is to calculate total volume using the SUM function or determine typical performance using the AVG function, the power of the query language transforms Google Sheets from a simple spreadsheet application into a lightweight, yet highly effective, data analysis tool. For content creators and data professionals, mastering the pivot clause within QUERY is fundamental for producing complex, scalable, and insightful reports.
By implementing these structured queries, users ensure that their data summaries are not only accurate but also self-updating, minimizing manual intervention and maximizing efficiency. This ensures the integrity and currency of vital business intelligence, allowing teams to focus on interpreting the data rather than struggling with its compilation and maintenance.
Cite this article
stats writer (2025). How to Easily Create a Pivot Table from a Google Sheets Query. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-create-a-pivot-table-in-google-sheets-query/
stats writer. "How to Easily Create a Pivot Table from a Google Sheets Query." PSYCHOLOGICAL SCALES, 5 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-create-a-pivot-table-in-google-sheets-query/.
stats writer. "How to Easily Create a Pivot Table from a Google Sheets Query." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-create-a-pivot-table-in-google-sheets-query/.
stats writer (2025) 'How to Easily Create a Pivot Table from a Google Sheets Query', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-create-a-pivot-table-in-google-sheets-query/.
[1] stats writer, "How to Easily Create a Pivot Table from a Google Sheets Query," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Create a Pivot Table from a Google Sheets Query. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.