Table of Contents
Exponential regression is a powerful statistical technique used for modeling relationships where the dependent variable changes at an accelerating or decelerating rate relative to the independent variable. Unlike linear regression, which assumes a constant rate of change, exponential models are essential for phenomena exhibiting rapid growth or decay, such as population dynamics, compound interest, or radioactive decay. Mastering this technique in Python requires understanding how to transform the inherently nonlinear data into a solvable linear format. The goal of this regression process is to find the best-fitting curve that minimizes the sum of squared errors between the observed data points and the predicted values generated by the model equation. This guide details the mathematical foundation and the practical implementation of exponential regression using the robust numerical capabilities provided by the NumPy library.
Introduction to Exponential Regression
The necessity for exponential regression arises when data exhibits a pattern where the rate of change itself increases or decreases proportionally to the current magnitude. This is fundamentally different from linear growth, where the increase is additive and constant. To successfully implement an exponential model, data scientists often employ a linearization technique, which involves applying the natural logarithm to the response variable. This mathematical transformation converts the curved relationship into a straight line, allowing us to leverage established algorithms designed for simple linear regression.
Once the data is linearized, we can estimate the parameters of the straight line. These parameters are crucial intermediary values that directly correspond to the coefficients of the original exponential equation. This methodology ensures accurate estimation while benefiting from the computational efficiency and stability inherent in linear least squares methods. The subsequent steps involve back-transforming these parameters to interpret the final exponential model in its native form, ready for prediction and analysis.
Understanding the Exponential Model Equation
The structure of the exponential model is designed to capture non-constant rates of change. The base structure of the equation can be written in two common forms, which are mathematically equivalent:
y = abx or y = aebx.
In these expressions, the coefficients a and b are the parameters estimated by the regression model. These coefficients carry specific statistical meaning:
- y: The response variable, representing the value being predicted.
- x: The predictor variable, representing the independent input.
- a: The scaling factor or the initial value (the intercept) when the predictor variable x is zero.
- b: The growth/decay factor, describing the multiplicative rate of change between x and y.
The core challenge in solving y = abx lies in its non-linearity. To overcome this, we take the natural logarithm of both sides, resulting in the transformed equation: $ln(y) = ln(a) + x cdot ln(b)$. This is now in the linear form $Y = A + Bx$, where $Y = ln(y)$, $A = ln(a)$, and $B = ln(b)$. This linearization is the foundation for fitting the model efficiently in Python.
Applications of Exponential Regression (Growth and Decay)
Exponential regression is vital for modeling phenomena characterized by continuous, multiplicative change. It is critical to identify whether the data exhibits growth or decay patterns, as this dictates the interpretation of the calculated rate coefficient. The model is highly effective for quantifying changes over time or space where the magnitude of the change is dependent on the current state.
1. Exponential growth: This scenario is defined by an increasing rate of change. Growth begins slowly and then accelerates rapidly without bound within the scope of the model. This model is commonly applied in finance (compound interest returns), epidemiology (initial spread of infectious diseases), and biology (uninhibited cell proliferation).

In an exponential growth model, the calculated base coefficient $b$ (in $y = ab^x$) must be greater than 1. This parameter indicates that the response variable is increasing by a percentage factor for every unit increase in the predictor variable x. The graphical representation clearly shows an upward curvature, confirming the accelerating nature of the data.
2. Exponential decay: This pattern involves a decreasing rate of change. Decay begins rapidly and then gradually slows down, approaching zero (or some baseline asymptote). Applications include physics (radioactive half-life calculations), chemistry (reaction rates), and material science (wear and tear).

In an exponential decay model, the base coefficient $b$ must fall between 0 and 1. This value represents the fraction of the response variable remaining after a unit increase in x. Visual confirmation via a scatter plot is essential to verify that the data curves downward, starting sharply and flattening out toward the horizontal axis.
Step 1: Setting up the Python Environment and Data Preparation
To execute exponential regression in Python, we must first import the necessary numerical libraries, primarily NumPy, which provides the foundational array structures and mathematical functions required for data manipulation and fitting. Good programming practice dictates that we define our data variables clearly before attempting any analysis or modeling.
Step 1: Create the Data
We create a synthetic dataset consisting of 20 paired observations for the predictor variable x and the response variable y. This specific dataset is designed to simulate a real-world phenomenon exhibiting accelerating growth, allowing us to accurately demonstrate the model fitting process. We use NumPy to create highly optimized arrays.
import numpy as np x = np.arange(1, 21, 1) y = np.array([1, 3, 5, 7, 9, 12, 15, 19, 23, 28, 33, 38, 44, 50, 56, 64, 73, 84, 97, 113])
The x array spans integer values from 1 up to 20, representing sequential independent measurements. The y array contains the corresponding observed values, whose magnitude increases rapidly, particularly toward the end of the sequence. These two arrays form the input structure for our exponential regression analysis.
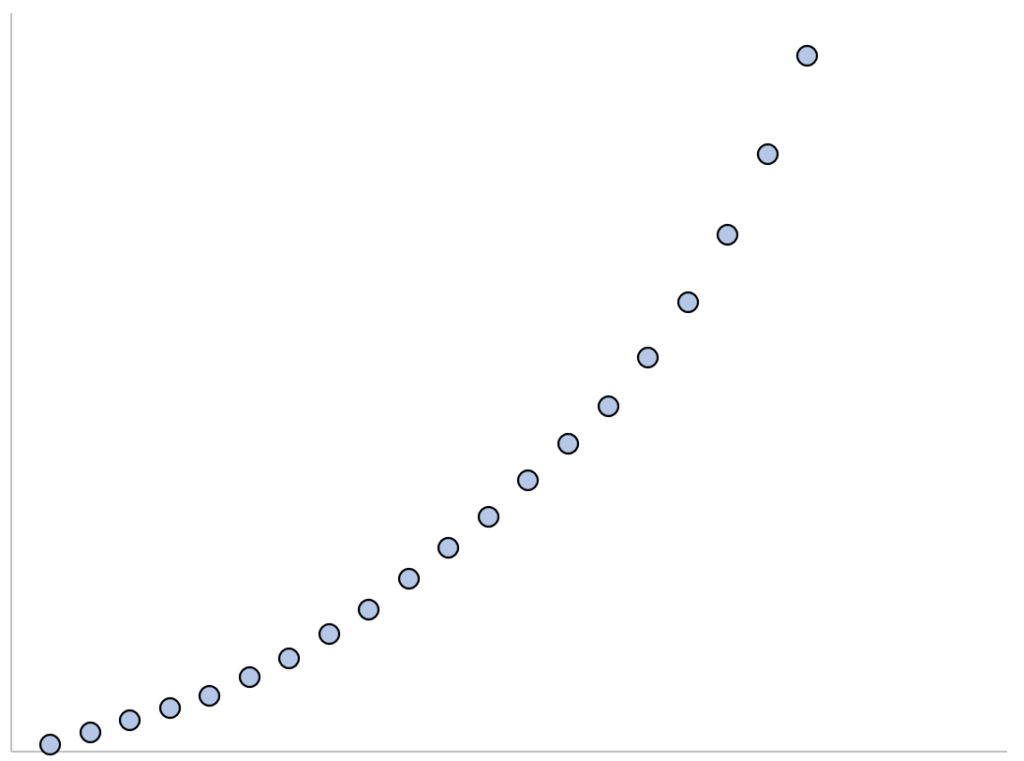
Step 2: Exploratory Data Visualization
Visualization is an indispensable step in any regression analysis, serving as the primary method to confirm the underlying relationship between variables. By plotting the raw data, we can visually confirm the non-linear nature and justify the implementation of an exponential model rather than defaulting to a standard linear regression.
Step 2: Visualize the Data
We employ the matplotlib.pyplot library to generate a scatterplot. This code block is concise but highly effective at illustrating the relationship between the predictor x and the response y.
import matplotlib.pyplot as plt plt.scatter(x, y) plt.show()

The visual output confirms the data exhibits a clear upward, accelerating curve. The points do not cluster around a straight line, making it evident that a linear model would poorly fit and inaccurately represent the underlying relationship. The strong curvature justifies proceeding with an exponential regression approach, which is specifically suited for this type of non-linear growth pattern.
Step 3: Transforming Data and Fitting the Model (Linearization)
To fit the exponential model, we must first perform the linearization step. This involves taking the natural logarithm of the response variable y. The transformed data $(text{x}, ln(y))$ will approximate a linear relationship, allowing us to use linear fitting algorithms.
Step 3: Fit the Exponential Regression Model
We utilize the NumPy function polyfit() to estimate the coefficients of the linearized equation. We calculate $ln(y)$ using `np.log(y)` and fit a first-degree polynomial (a straight line, indicated by the ‘1’) to the transformed data. The function returns the coefficients $B$ (slope) and $A$ (intercept) for the equation $ln(y) = A + Bx$.
#fit the model: finding coefficients B (slope) and A (intercept) for the linear model Y = Bx + A fit = np.polyfit(x, np.log(y), 1) #view the output of the model print(fit) [0.2041002 0.98165772]
The output array `[0.2041002, 0.98165772]` provides the estimated parameters. The first element, 0.2041, is the slope $B$ ($ln(b)$), and the second element, 0.9817, is the intercept $A$ ($ln(a)$).
The resulting linear equation based on the transformed variables is:
ln(y) = 0.9817 + 0.2041(x).
This intermediate result successfully models the data in a linear domain, setting the stage for the final step of back-transformation.
Step 4: Interpreting the Results and Making Predictions
The final and most crucial step is to convert the linearized coefficients back into the parameters of the original exponential equation, $y = ab^x$. We must exponentiate the intercept $A$ and the slope $B$ using Euler’s number ($e$).
The original coefficient a (the starting value) is found by $a = e^{0.9817} approx 2.6689$. The original coefficient b (the growth factor) is found by $b = e^{0.2041} approx 1.2264$.
The definitive fitted exponential regression equation for our data is:
y = 2.6689 * 1.2264x
The growth factor $b = 1.2264$ indicates that for every increase of one unit in the predictor variable x, the response variable y increases by a factor of 1.2264, confirming a strong multiplicative growth rate (22.64% per unit of x).
We can now utilize this equation for accurate prediction. For example, to estimate the value of y when x is 12, we substitute 12 into the equation:
$$ y = 2.6689 times 1.2264^{12} approx 30.897 $$
Therefore, the model predicts that when the predictor variable x is 12, the response variable y will be approximately 30.897. This final prediction validates the successful implementation of the exponential regression methodology.
Bonus: Feel free to use this online tool to automatically compute the exponential regression equation for a given predictor and response variable.
Summary of the Exponential Regression Process
Performing exponential regression involves a systematic transition from a non-linear problem to a solvable linear one. The process starts with Exploration (visualizing the data to confirm exponential fit), moves to Transformation (applying the natural logarithm to $y$), proceeds to Modeling (using polyfit() to find linear coefficients), and concludes with Interpretation (exponentiating the results back to the original equation $y=ab^x$). This method provides a rigorous and efficient way to model complex growth and decay dynamics using standard Python libraries.
Cite this article
stats writer (2025). How to Easily Perform Exponential Regression in Python. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-perform-exponential-regression-in-python-step-by-step/
stats writer. "How to Easily Perform Exponential Regression in Python." PSYCHOLOGICAL SCALES, 6 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-perform-exponential-regression-in-python-step-by-step/.
stats writer. "How to Easily Perform Exponential Regression in Python." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-perform-exponential-regression-in-python-step-by-step/.
stats writer (2025) 'How to Easily Perform Exponential Regression in Python', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-perform-exponential-regression-in-python-step-by-step/.
[1] stats writer, "How to Easily Perform Exponential Regression in Python," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Perform Exponential Regression in Python. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.