Table of Contents
The ability to accurately quantify the relationship between categorical variables is fundamental in statistics and data analysis. One of the most reliable and widely used measures for this purpose is Cramer’s V, which assesses the strength of association between two nominal variables organized within a contingency table. Unlike simpler metrics, Cramer’s V is specifically designed to handle tables of any dimension (R x C), making it a versatile tool for researchers across various disciplines. Understanding how to calculate this statistic efficiently, especially using powerful tools like Microsoft Excel, is essential for data practitioners.
Cramer’s V provides a standardized measure, meaning its output is always bound between 0 and 1, facilitating straightforward interpretation regardless of the dataset size or the number of categories involved. This standardization is crucial for comparing the magnitude of association across different studies. If the variables were independent, we would expect a value close to zero; conversely, a value near one suggests a near-perfect relationship between the variables under observation.
Understanding Cramer’s V: A Measure of Association
When analyzing cross-tabulated data, we often need a single figure that summarizes how much one variable depends on the other. Cramer’s V fulfills this requirement by extending the utility of the standard Chi-square statistic. While the Chi-square test tells us whether an association exists (i.e., whether the variables are statistically dependent), it does not quantify the strength of that association. Because the magnitude of the Chi-square statistic is heavily influenced by the total sample size (n) and the dimensions of the table, it cannot be used directly to compare the strength of relationships across different datasets.
This is where Cramer’s V steps in. It adjusts the raw Chi-square value by dividing it by the maximum possible Chi-square value for that specific sample size and table dimensions. This normalization process ensures the final result is a true measure of effect size, independent of the sample size. The final value allows researchers to confidently state whether the observed relationship is small, moderate, or large, providing much-needed context to the often-abstract results of hypothesis testing.
The range of Cramer’s V is strictly defined, making interpretation unambiguous:
- 0 indicates absolutely no association or relationship between the two categorical variables.
- 1 indicates a perfect or strong association between the two variables, meaning the value of one variable almost entirely predicts the value of the other.
The Mathematical Foundation: Chi-Square and Cramer’s V Formula
Before attempting the calculation in Excel, it is imperative to understand the underlying mathematical relationship. Cramer’s V is fundamentally derived from the Pearson’s Chi-square test for independence. The core idea is to measure the deviation between the observed frequencies in the contingency table and the frequencies that would be expected if the two variables were perfectly independent. A larger deviation results in a larger Chi-square value, which subsequently leads to a larger Cramer’s V, assuming other factors remain constant.
The complete formula for calculating Cramer’s V is as follows. Note that the square root is applied to the entire normalized ratio to bring the resulting value back onto a linear scale, thereby establishing the range between 0 and 1:
Cramer’s V = √(X2/n) / min(c-1, r-1)
Each component of this formula plays a critical role in standardizing the result:
- X2: This represents the calculated Chi-square statistic, obtained by comparing observed and expected cell counts.
- n: This is the total sample size, which is the sum of all cell counts in the contingency table.
- r: This denotes the number of rows in the contingency table (excluding totals).
- c: This denotes the number of columns in the contingency table (excluding totals).
- min(c-1, r-1): This term determines the minimum possible degrees of freedom used in the normalization, ensuring the calculated V is bounded by 1.
Since Excel does not have a single built-in function to calculate Cramer’s V directly, we must calculate the components sequentially. The most complex part is generating the X2 (Chi-square) value, as this requires calculating the expected frequencies for every cell in the table based on marginal totals. The remaining components—n, r, and c—are typically straightforward counts derived directly from the structure of the data input.
Setting Up Your Data for Analysis in Excel
To calculate Cramer’s V in Excel, the initial step involves properly structuring your raw frequency counts into a contingency table. This table must represent the observed counts for the intersections of the two categorical variables being studied. For instance, if analyzing the relationship between ‘Exam Prep Method’ (Variable 1) and ‘Exam Outcome’ (Variable 2), the cells must contain the counts of students who fall into specific combinations (e.g., ‘Method A’ and ‘Passed’).
We will use a practical example to illustrate this process. Suppose we want to determine if there is a meaningful association between the specific method students used to prepare for an exam (Method A vs. Method B) and their ultimate performance (Pass vs. Fail). This results in a 2×2 contingency table. The organizational layout in Excel is crucial, as marginal totals (row totals and column totals) must be calculated immediately adjacent to the core data matrix for use in the expected frequency calculations.
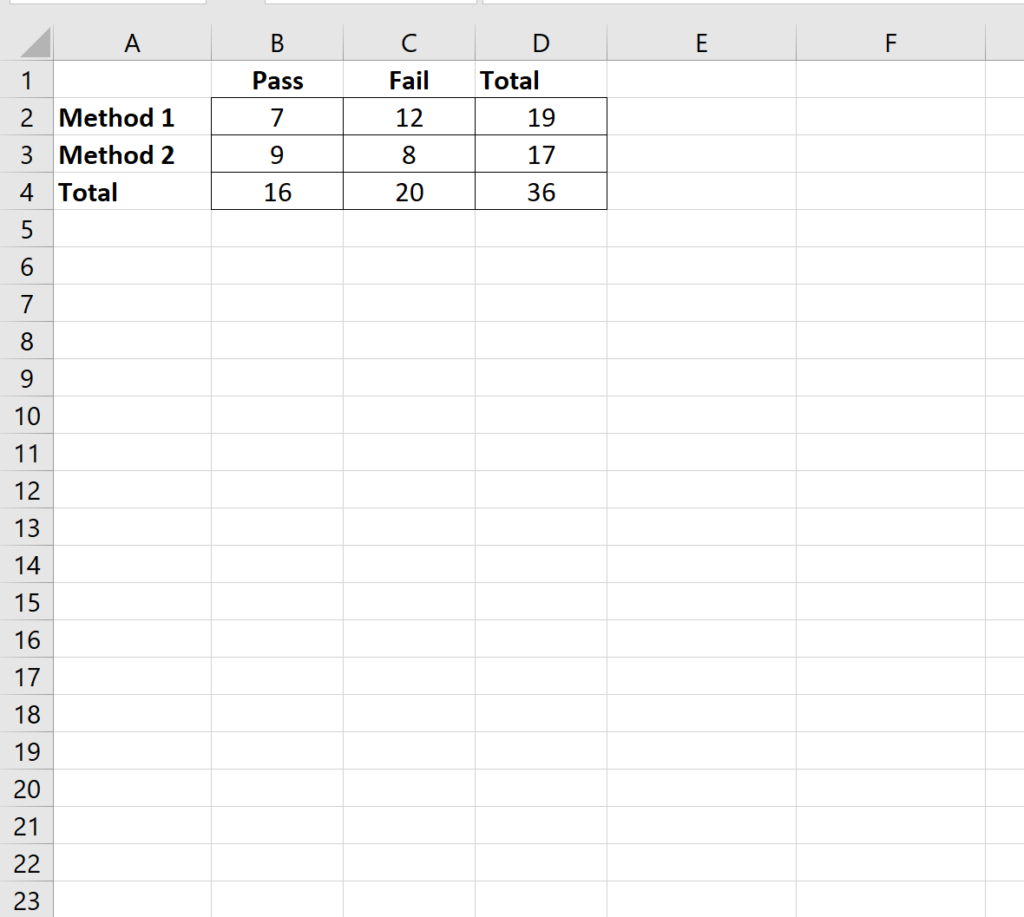
The following table represents the raw observed frequencies for our scenario. Notice how the structure clearly delineates the categories and their associated counts:

From this setup, we can immediately identify the dimensions: two rows (Passed, Failed) and two columns (Method A, Method B). This means r=2 and c=2. The total sample size (n) is derived by summing all four internal cells, or by summing the marginal totals. Once the observed data is secure, the next critical step is to calculate the corresponding expected frequencies, which are essential for the subsequent Chi-square calculation.
Step-by-Step Guide: Calculating the Chi-Square Statistic
The calculation of the Chi-square statistic (X2) involves three primary sub-steps: calculating the expected frequency for each cell, calculating the Chi-square contribution for each cell, and finally, summing these contributions. The expected frequency (E) for any given cell is calculated using the formula: E = (Row Total * Column Total) / Total Sample Size (n). This value represents the frequency we would mathematically anticipate if the variables were completely independent.
For our example, the total sample size (n) is 36. If the table is set up such that the observed counts are in cells B2:C3, and the marginal totals are calculated in column D and row 4, the expected frequency for the cell in B2 (Method A, Passed) would be calculated using the Excel formula: =(D2*B4)/D4. This procedure must be meticulously repeated for every cell in the original 2×2 matrix. Accuracy here is vital, as any error propagates directly into the final Cramer’s V value.
Once the expected frequencies are calculated, the next step is to find the Chi-square contribution for each cell using the formula: (Observed – Expected)2 / Expected. This term measures how far the actual observation deviates from the expectation under the null hypothesis of independence. Finally, the total Chi-square statistic (X2) is the sum of all these individual cell contributions. Alternatively, Excel provides a simplified function, CHISQ.TEST, which can calculate the P-value directly, but to obtain the X2 value itself for use in Cramer’s V, it is often easier and more transparent to utilize the component calculation method or the CHISQ.INV.RT function combined with the P-value and degrees of freedom. For a 2×2 table, the direct calculation of cell contributions is generally the most straightforward path.
Determining Degrees of Freedom and Sample Size (n, r, c calculation)
The successful calculation of Cramer’s V hinges on correctly identifying the remaining parameters in the denominator of the formula: the total sample size (n), the number of rows (r), and the number of columns (c). These parameters collectively determine the maximum possible association achievable, which is necessary for normalization.
The total sample size, n, is simply the count of all observations included in the study. In our running example concerning 36 students, n = 36. This value is used in the numerator of the normalized Chi-square term (X2/n). The number of rows (r) and columns (c) refer exclusively to the dimensions of the core data matrix, excluding any total rows or columns added for summary statistics. In a 2×2 table, r=2 and c=2.
The term min(c-1, r-1) is crucial because it accounts for the table’s degrees of freedom (df). The degrees of freedom for a contingency table are generally calculated as (r-1)*(c-1). However, Cramer’s V uses the minimum of (r-1) or (c-1) in its denominator to ensure that the resulting normalized statistic never exceeds 1. If we used the standard degrees of freedom (df), the normalization would be incorrect for non-square tables where the association is less constrained. For our 2×2 example, r-1 = 1 and c-1 = 1, so min(c-1, r-1) = 1. This value is denoted as k-1 in some texts, where k = min(r, c).
By determining these parameters, we isolate the two final components needed for the final calculation: the ratio (X2/n) and the normalization factor (min(c-1, r-1)). These values will be combined under the square root, yielding the final measure of effect size.
Calculating the Final Cramer’s V Value in Excel
Once the Chi-square statistic (X2) has been determined, applying the full formula in Excel becomes a relatively simple task using standard arithmetic and the SQRT and MIN functions. This step synthesizes all the intermediate calculations into the single, interpretable Cramer’s V metric.
Using the structure from our example, the calculations for X2, n, r, and c should be placed in designated cells for clarity. Assuming X2 is calculated in cell G2, n in cell G3, r in G4, and c in G5, the full Cramer’s V formula would be structured in Excel as follows:
=SQRT( (G2/G3) / MIN(G4-1, G5-1) )
This powerful single-line formula performs the normalization and square root transformation required. The numerator calculates the association normalized by sample size, while the denominator divides this by the minimum adjusted dimension, effectively rescaling the entire value to fit within the 0 to 1 range.
The following screenshot provides a visual confirmation of the exact formulas and resulting values used in our 2×2 table example involving 36 students. Note how the individual components (observed, expected, and contribution) feed into the final comprehensive calculation:

Following the execution of these formulas, the calculated Cramer’s V value for this specific dataset turns out to be precisely 0.1617. This derived value is now ready for interpretation against standardized benchmarks for effect size.
Interpreting Cramer’s V and Effect Size Conventions
The resulting value of Cramer’s V (0.1617 in our example) must be interpreted within the context of statistical conventions. Unlike correlation coefficients, where interpretation is relatively standard, the meaningfulness of V depends slightly on the degrees of freedom (df) used, specifically the minimum of (r-1) or (c-1). Because the maximum possible association is constrained by the number of categories, slightly different benchmarks are often applied for 2×2 tables versus larger RxC tables.
Cohen (1988) provided widely accepted guidelines for interpreting effect size measures derived from Chi-square statistics, particularly for the related Phi coefficient (which is equivalent to Cramer’s V in a 2×2 context). These guidelines help categorize the strength of association into small, medium, and large effects. It is critical to consult these benchmarks, as a V value of 0.3 might be considered large in a 2×2 table but only moderate in a 5×5 table.
We can use the following widely accepted table, which defines standard conventions for effect size based on the minimum degrees of freedom (k-1, where k is the minimum dimension):

For our specific example, which is a 2×2 table, the minimum dimension is k=2, meaning the relevant degrees of freedom (k-1) is 1. Consulting the table under df=1, a small effect is defined as V=0.10, a medium effect as V=0.30, and a large effect as V=0.50. Since our calculated Cramer’s V is 0.1617, it falls slightly above the threshold for a small effect but remains well below the medium effect size marker.
In practical terms, this suggests that while there is a statistically observable relationship between the exam preparation method used and the students’ passing rate (assuming the X2 test was significant), the magnitude of this association is relatively weak. The exam preparation method accounts for a small proportion of the variance in the outcome. Researchers should conclude that the choice of prep method has a minor influence on the likelihood of passing or failing the exam, necessitating the exploration of other, potentially more influential variables.
Conclusion and Best Practices for Data Quality
Calculating Cramer’s V in Excel is a multi-step yet rewarding process that transforms raw contingency data into a standardized, interpretable measure of association. It is a vital statistic for moving beyond simple hypothesis testing (which only confirms dependency) to quantifying the practical significance, or effect size, of the observed relationship. Mastery of the individual calculation steps—from determining expected frequencies to applying the normalization factor—ensures that the resulting V value is robust and accurate.
To maintain the highest level of data integrity when using these methods, always ensure that your input data meets the prerequisites for the Chi-square statistic: observations must be independent, and expected cell counts should ideally be 5 or greater (though less strict rules apply for 2×2 tables). If these assumptions are severely violated, alternative measures of association might be more appropriate. However, for well-formed nominal data, Cramer’s V remains the gold standard for summarizing association strength, providing clear quantitative evidence for decision-making and reporting.
Cite this article
stats writer (2025). How to Easily Calculate Cramer’s V in Excel. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-calculate-cramers-v-in-excel/
stats writer. "How to Easily Calculate Cramer’s V in Excel." PSYCHOLOGICAL SCALES, 5 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-calculate-cramers-v-in-excel/.
stats writer. "How to Easily Calculate Cramer’s V in Excel." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-calculate-cramers-v-in-excel/.
stats writer (2025) 'How to Easily Calculate Cramer’s V in Excel', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-calculate-cramers-v-in-excel/.
[1] stats writer, "How to Easily Calculate Cramer’s V in Excel," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Calculate Cramer’s V in Excel. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.