Table of Contents
Understanding the Fundamentals of the Coefficient of Variation
The Coefficient of Variation, frequently denoted as CV, represents a specialized statistical measure designed to quantify the dispersion of data points in a dataset relative to its mean. Unlike standard variance or deviation, which are expressed in the original units of the data, the CV is a dimensionless number. This unique characteristic allows researchers and analysts to compare the degree of variation between two or more datasets even if they have vastly different scales or units of measurement. By normalizing the distribution, the Coefficient of Variation provides a clear picture of relative volatility that absolute measures simply cannot convey.
In the broader context of descriptive statistics, the CV is often referred to as the relative standard deviation. It is essentially a ratio that expresses the magnitude of the standard deviation as a percentage of the average. When the CV is low, it indicates that the data points are tightly clustered around the mean, suggesting high precision or stability. Conversely, a high CV suggests a high level of dispersion relative to the average, which might indicate significant volatility or a lack of consistency within the observed data. This makes it an indispensable tool for fields ranging from biology to finance, where understanding the scale of “noise” relative to the “signal” is paramount.
To ensure the Coefficient of Variation remains a valid and meaningful metric, it must be applied to data measured on a ratio scale. A ratio scale is a type of variable measurement scale which is quantitative and possesses a “true zero” point. Because the formula involves dividing by the mean, the CV becomes mathematically unstable or even undefined as the mean approaches zero. Furthermore, if the dataset includes negative values, the interpretation of the CV can become misleading. Therefore, it is a standard best practice in data analysis to use this metric primarily for positive values where the mean is significantly greater than zero.
The utility of the CV extends to its ability to facilitate “apples-to-apples” comparisons. For instance, if one were comparing the weight variation of elephants to the weight variation of mice, the absolute standard deviation of the elephants would naturally be much larger due to their size. However, the Coefficient of Variation would allow a scientist to determine which species actually exhibits more variation relative to its own size. This level of abstraction is what gives the CV its power in complex scientific research and industrial quality control settings.
The Mathematical Framework Behind the CV Formula
The mathematical architecture of the Coefficient of Variation is elegant in its simplicity, yet profound in its application. It is defined by the formula CV = σ / μ, where σ represents the standard deviation and μ represents the mean. In this equation, the standard deviation serves as the numerator, capturing the absolute spread of the data, while the mean serves as the denominator, acting as the scaling factor. By dividing the spread by the average, the resulting value removes the unit of measurement, producing a ratio that can be easily understood and communicated across different domains.
When calculating this in a practical environment like Microsoft Excel, it is important to distinguish between a population and a sample. If the dataset represents an entire population, the standard deviation is calculated using the STDEV.P function. If the data is merely a sample of a larger population, the STDEV.S function is used. This distinction is vital because the sample standard deviation uses Bessel’s correction (n-1) to provide an unbiased estimate of the population variance. Choosing the correct function in Microsoft Excel ensures that your Coefficient of Variation remains statistically accurate and reliable for further inference.
While the basic ratio provides the CV in decimal form, it is a common convention to express the result as a percentage. This is achieved by multiplying the ratio by 100. For example, a CV of 0.15 is frequently reported as 15%. This percentage format is often preferred in professional presentations and academic papers because it provides an intuitive grasp of the relative variability. A 15% CV tells the audience that the “spread” of the data is 15% the size of the “average,” which is a much more relatable concept than an abstract decimal or a raw standard deviation value in units like kilograms or dollars.
Mathematically, the Coefficient of Variation can also be interpreted as the reciprocal of the signal-to-noise ratio. In engineering and physics, the signal-to-noise ratio compares the level of a desired signal to the level of background noise. In statistics, if we consider the mean as the “signal” (the central tendency we are trying to observe) and the standard deviation as the “noise” (the uncertainty or variation), then the CV effectively measures how much noise exists per unit of signal. This perspective is particularly useful when evaluating the reliability of laboratory measurements or the consistency of manufacturing processes.
Why the Coefficient of Variation is Essential in Statistical Analysis
One of the primary reasons the Coefficient of Variation is so essential is its role in handling heteroscedasticity. In many real-world datasets, the variance tends to increase in proportion to the mean. For example, in economics, wealthier nations might show higher absolute fluctuations in their annual GDP compared to smaller nations. By using the CV, an economist can determine if the relative economic stability of a large nation is actually better or worse than that of a small nation, regardless of the massive difference in their total output. Without the CV, comparisons across different scales would be heavily biased toward datasets with smaller absolute values.
The Coefficient of Variation is also a cornerstone of quality control and Six Sigma methodologies. In manufacturing, consistency is key to ensuring product reliability. If a factory produces bolts, the absolute variation in bolt length must be extremely small. By monitoring the CV, quality assurance managers can track whether the production process is remaining stable over time. If the CV begins to rise, it serves as an early warning system that the process is becoming less predictable, even if the average bolt length remains within acceptable limits. This makes the CV a proactive tool for maintaining operational excellence.
In the field of analytical chemistry and medical testing, the CV is used to assess the “repeatability” and “reproducibility” of laboratory results. When a blood test is performed multiple times on the same sample, the results should ideally be identical. The Coefficient of Variation allows clinicians to quantify the precision of their equipment. A low CV in this context means that the diagnostic tool is highly reliable. If the CV exceeds a certain threshold, it may indicate that the equipment requires recalibration or that the testing procedure is prone to human error, which could lead to incorrect medical diagnoses.
Furthermore, the Coefficient of Variation is invaluable when dealing with diverse data types in multivariate statistics. When analyzing a system that involves different units—such as temperature in Celsius, pressure in Pascals, and volume in Liters—it is impossible to compare their standard deviations directly. The CV transforms these disparate measurements into a common language of percentages. This transformation enables researchers to identify which variable in a complex system is the most volatile, providing critical insights into system dynamics and potential points of failure.
Practical Applications in Finance and Risk Management
In the world of finance, the Coefficient of Variation is a vital metric for assessing the risk-return trade-off. Investors are constantly seeking to maximize their returns while minimizing their exposure to risk. While the mean expected return tells an investor what they might earn on average, the standard deviation tells them how much that return might fluctuate. However, comparing two different investments based on standard deviation alone can be deceptive. The CV provides a more nuanced view by calculating the amount of risk (volatility) assumed per unit of expected return.
Consider an institutional investor evaluating two different asset classes: high-yield bonds and blue-chip stocks. The stocks might have a higher standard deviation, which traditionally suggests higher risk. However, if the stocks also offer a significantly higher average return, their Coefficient of Variation might actually be lower than that of the bonds. In this scenario, the CV reveals that the stocks are a more efficient investment because they provide a better “risk-adjusted” return. This application of CV is a fundamental component of Modern Portfolio Theory, helping managers construct diversified portfolios that optimize performance.
Risk managers also utilize the Coefficient of Variation to monitor market volatility across different sectors. For instance, during periods of economic instability, the CV of the technology sector might rise more sharply than the CV of the utilities sector. By analyzing these relative shifts, risk managers can rebalance portfolios to protect capital. The CV acts as a standardized gauge, allowing for the comparison of volatility in the stock market, foreign exchange market, and commodity markets simultaneously, despite their differing price points and liquidity levels.
Beyond individual investments, the CV is used in actuarial science to determine insurance premiums. Actuaries analyze the Coefficient of Variation of claim frequencies and claim amounts to understand the predictability of losses. A high CV in claim amounts indicates that losses are highly variable and unpredictable, which typically results in higher premiums to cover the increased risk of a “fat-tail” event. By using the CV, insurance companies can more accurately price their products, ensuring they remain solvent while providing fair rates to their policyholders.
Comparative Analysis Using Real-World Scenarios
To illustrate the practical utility of the Coefficient of Variation, let us examine a detailed comparison involving mutual fund performance. Suppose an investor is deciding between two different funds, Fund A and Fund B, over a five-year period. Fund A has demonstrated an average annual return of 7% with a standard deviation of 12.4%. On the surface, Fund A seems attractive due to its higher average return. However, Fund B shows an average annual return of 5% with a much lower standard deviation of 8.2%. To make an informed decision, the investor must look at the relative risk.
By applying the CV formula, we find that the Coefficient of Variation for Fund A is 1.77 (12.4% / 7%), while the CV for Fund B is 1.64 (8.2% / 5%). In this context, a lower CV is generally preferred because it signifies that the investment offers a more stable return relative to the risk taken. Despite having a lower absolute return, Fund B is actually the “safer” and more consistent performer when risk is accounted for. This type of analysis prevents investors from being blinded by high average returns that come with excessive and potentially ruinous volatility.
Another scenario involves supply chain management. A company may be sourcing a critical component from two different suppliers. Supplier X has an average delivery time of 10 days with a standard deviation of 2 days. Supplier Y has an average delivery time of 20 days with a standard deviation of 3 days. While Supplier X is faster on average, their CV is 0.20 (2/10), whereas Supplier Y has a CV of 0.15 (3/20). Surprisingly, Supplier Y is more consistent relative to their average lead time. Depending on the company’s inventory strategy, the consistency of Supplier Y might be more valuable than the average speed of Supplier X, especially in Just-In-Time (JIT) manufacturing environments.
In agricultural economics, the CV is used to compare crop yields across different regions with different climates. A region with a high average yield but a very high CV might be prone to occasional crop failures due to weather instability. A different region might have a lower average yield but a much lower CV, indicating a more reliable food source. Policymakers use the Coefficient of Variation to identify which areas require more investment in irrigation or drought-resistant technology to stabilize the local economy and ensure food security.
Step-by-Step Guide to Calculating CV in Microsoft Excel
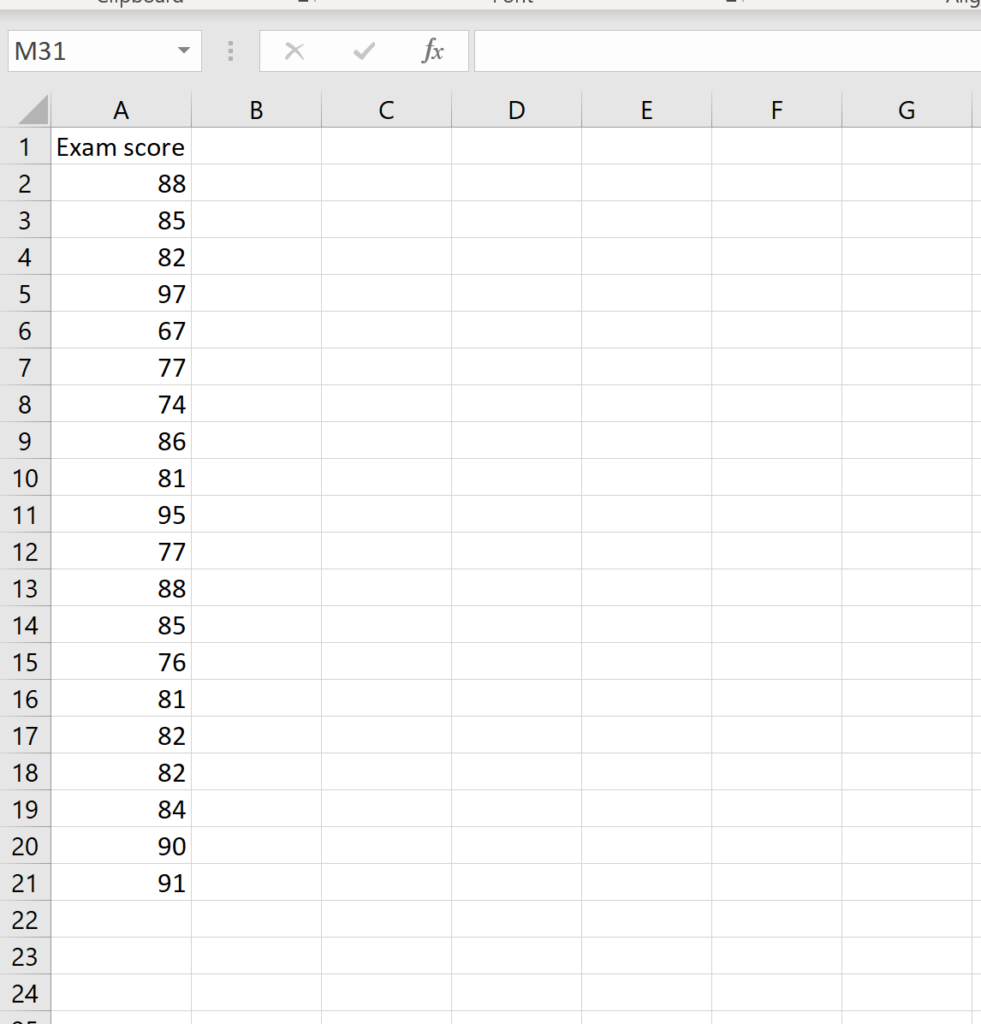
Calculating the Coefficient of Variation in Microsoft Excel is a straightforward process that involves using built-in statistical functions. To begin, you must have your data organized in a clear, contiguous range. For this example, let us assume we are analyzing a dataset consisting of the exam scores of 20 students, located in cells A2 through A21. Visualizing the data is the first step in ensuring there are no obvious outliers or entry errors that could skew your results.

The first requirement for our calculation is the mean of the dataset. In Microsoft Excel, the mean is calculated using the =AVERAGE() function. You would enter =AVERAGE(A2:A21) into an empty cell to find the average score. Next, you need the standard deviation. For a standard sample of students, you would use the =STDEV.S() or simply =STDEV() function. By entering =STDEV(A2:A21), Excel will compute the absolute spread of the exam scores.

Once you have these two values, the final step to find the Coefficient of Variation is to divide the standard deviation by the mean. If your mean is in cell C2 and your standard deviation is in cell C3, you would enter the formula =C3/C2. This will return the CV in decimal format. To make this more readable, you can use the “Percentage” format button in the Excel ribbon, which will automatically multiply the value by 100 and add the “%” symbol.

In this specific example of student scores, the Coefficient of Variation is calculated to be 0.0864, or 8.64%. This tells the educator that the variation in student performance is relatively low compared to the average score. Such a result suggests that the teaching methods are reaching most students consistently, as there isn’t a massive relative spread in the grades achieved across the class.
Advanced Excel Techniques for Dataset Variability
For users who prefer efficiency, Microsoft Excel allows you to calculate the Coefficient of Variation in a single, nested formula. Instead of using multiple cells for the mean and standard deviation, you can combine them into one: =STDEV(A2:A21)/AVERAGE(A2:A21). This approach is particularly useful when you are working with large workbooks or “dashboards” where space is limited and you need to perform quick comparisons across multiple columns of data.

When working with dynamic datasets that change over time, you can utilize Excel Tables or named ranges. By converting your data into a table (using Ctrl+T), your formulas will automatically update as you add new rows. For example, if your table is named “ExamData” and the column is “Scores,” your formula would become =STDEV(ExamData[Scores])/AVERAGE(ExamData[Scores]). This ensures your Coefficient of Variation remains accurate without needing to manually adjust the cell references every time new information is added.
Another advanced technique involves using the Data Analysis Toolpak in Excel. This add-in provides a “Descriptive Statistics” feature that generates a comprehensive report including the mean, standard deviation, variance, and more in a single click. While it does not calculate the CV directly, it provides all the necessary components in a clean table. This is highly beneficial when you need to perform an in-depth statistical analysis and want to document all the underlying metrics alongside the CV for a professional report.
For those performing complex probability modeling, you can also calculate the CV across different rows using array formulas or the newer MAP and LAMBDA functions in Office 365. These functions allow you to apply the CV calculation to multiple datasets simultaneously without dragging formulas across thousands of cells. This level of automation is essential for data scientists and financial analysts who deal with high-frequency data where manual entry is not feasible.
Interpreting the Results and Making Data-Driven Decisions
Interpreting a Coefficient of Variation requires context, as there is no universal “good” or “bad” CV value. In some fields, like high-precision engineering, a CV of 1% might be considered unacceptably high. In other fields, such as social sciences or psychology, a CV of 20% or 30% might be perfectly normal given the inherent variability of human behavior. Understanding the industry standard or the historical CV of your specific dataset is crucial for making a correct assessment.
When you observe a CV that is significantly higher than expected, it should trigger a deeper investigation into the data. Is the high variation caused by a few outliers, or is the entire dataset widely dispersed? In Microsoft Excel, you can use conditional formatting to highlight data points that fall more than two standard deviations away from the mean. This helps you determine if the high Coefficient of Variation is a result of data entry errors or a genuine reflection of a volatile process.
Data-driven decision-making relies on the ability to distinguish between absolute and relative change. If a company’s revenue grows by 10% but the CV of its daily sales also increases by 50%, the growth may be less sustainable than it appears. The increased CV suggests that while the “average” is higher, the business has become much more unpredictable. A savvy manager would use the Coefficient of Variation to argue for stabilization strategies, such as diversifying the customer base or improving inventory management, rather than just celebrating the increase in mean revenue.
Finally, the CV is a powerful communication tool. When presenting findings to stakeholders who may not be experts in statistics, the CV simplifies complex concepts. Saying “the risk is 1.7 times the return” is a powerful statement that is easily understood. By providing a standardized metric, the Coefficient of Variation bridges the gap between raw data and actionable insights, enabling organizations to make more objective, risk-aware decisions in an increasingly complex world.
Common Pitfalls and Considerations When Using CV
Despite its many advantages, there are critical pitfalls to avoid when using the Coefficient of Variation. The most significant limitation is that the CV is only meaningful for variables measured on a ratio scale. If you attempt to calculate the CV for temperature in Celsius or Fahrenheit, the results will be nonsensical. This is because these scales have an arbitrary zero point. If the mean temperature is 1 degree, a small change in standard deviation will cause the CV to explode. In such cases, one should use the Kelvin scale, which has an absolute zero, or stick to other measures of dispersion.
Another common mistake is applying the Coefficient of Variation to datasets that contain both positive and negative values. If a dataset has a mean near zero because the positive and negative values cancel each other out, the CV will approach infinity, regardless of the actual spread of the data. In financial analysis, this can happen with “net profit” or “total return” datasets that include losses. In these instances, the CV is not the appropriate tool, and analysts often turn to the Sharpe Ratio or other risk-adjusted metrics specifically designed for such data structures.
It is also important to remember that the Coefficient of Variation is sensitive to the mean. If the mean is very small, even a tiny amount of variation will result in a very large CV. This can lead to an overestimation of the “instability” of a process. Users must always look at the CV in conjunction with the raw mean and standard deviation to maintain a balanced perspective. A high CV in a dataset with a mean of 0.001 might be less concerning than a moderate CV in a dataset with a mean of 1,000,000, depending on the practical implications of the variation.
Lastly, ensure that the standard deviation function you use in Microsoft Excel matches your data type. Using STDEV.P (population) when you should use STDEV.S (sample) will result in a slightly lower CV, which could lead to an underestimation of risk. While the difference might be negligible in very large datasets, it can be significant in smaller samples. Consistency in your methodology is essential for ensuring that your Coefficient of Variation remains a trustworthy metric for your analysis.
Cite this article
stats writer (2026). How to Calculate Coefficient of Variation in Excel Easily. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-i-calculate-the-coefficient-of-variation-in-excel/
stats writer. "How to Calculate Coefficient of Variation in Excel Easily." PSYCHOLOGICAL SCALES, 6 Mar. 2026, https://scales.arabpsychology.com/stats/how-do-i-calculate-the-coefficient-of-variation-in-excel/.
stats writer. "How to Calculate Coefficient of Variation in Excel Easily." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-do-i-calculate-the-coefficient-of-variation-in-excel/.
stats writer (2026) 'How to Calculate Coefficient of Variation in Excel Easily', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-i-calculate-the-coefficient-of-variation-in-excel/.
[1] stats writer, "How to Calculate Coefficient of Variation in Excel Easily," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Calculate Coefficient of Variation in Excel Easily. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.