Table of Contents
Comprehensive Overview of Random Name Selection in Excel
In the modern landscape of data analysis, the ability to extract unbiased information from a dataset is a fundamental skill. Whether you are conducting a simple random sample for a research project, selecting a winner for a corporate giveaway, or assigning tasks to team members, Microsoft Excel provides a robust suite of tools to automate these processes. By leveraging built-in formulas, users can move beyond manual selection, which is often prone to human bias and errors, and instead rely on a mathematical algorithm to ensure every entry has an equal probability of selection.
The process of selecting names at random involves the orchestration of several distinct functions that work in tandem to navigate cell references and generate numerical values. Primarily, the RAND function and its counterpart, the RANDBETWEEN function, serve as the engine for randomization. These functions generate values that can be mapped to specific rows within a spreadsheet, allowing for a dynamic and repeatable selection process. Understanding how these functions interact is crucial for any professional looking to maintain high standards of data integrity and transparency in their workflows.
This guide will explore two primary scenarios that users frequently encounter when managing lists in Microsoft Excel. The first scenario focuses on identifying a single individual from a comprehensive list, a task common in quick decision-making or spot-checking. The second scenario addresses the more complex requirement of selecting multiple individuals simultaneously while ensuring that no single name is chosen more than once. By mastering these techniques, you will be able to transform a static list into a functional tool for sophisticated organizational tasks.
Exploring the Mechanics of the INDEX and RANDBETWEEN Functions
To effectively select a random name, one must first understand the INDEX function, which is one of the most powerful lookup tools available in the spreadsheet environment. The INDEX function retrieves a value from a specific position within a range or array based on the row and column numbers provided. When we combine this with a random number generator, we essentially tell Excel to “look at this list of names and give me the name found at a random row position.” This eliminates the need for manual scrolling or subjective picking.
The RANDBETWEEN function is the second critical component of this formula. Unlike the standard RAND function, which returns any decimal between 0 and 1, RANDBETWEEN function allows the user to specify a lower and upper bound. This is particularly useful for list management because we can set the lower bound to 1 and the upper bound to the total number of items in our list. By doing so, the function always returns a valid row index that corresponds to an actual entry in our dataset.
To make the formula even more flexible and automated, we incorporate the ROWS function. This function automatically counts the total number of rows in a specified range. By using ROWS function as the upper limit for our random number, we ensure that if we add or remove names from our source list, the formula adapts without requiring manual updates to the numerical parameters. This creates a sustainable and scalable solution for dynamic datasets.
Execution of Single Name Selection via Formulaic Implementation
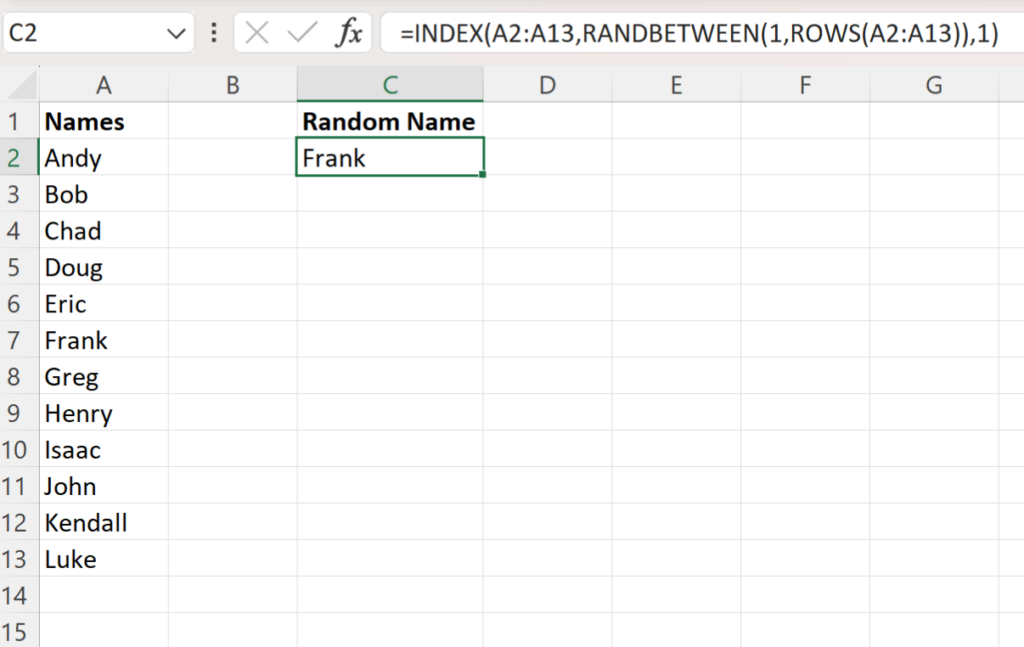
In this example, we will demonstrate how to isolate a single random name from a dataset. Suppose you have a list of names located in the range A2:A13. To retrieve a random result, you can input a specific nested formula into cell C2. This formula effectively bridges the gap between static data and probability, providing a seamless output every time the spreadsheet is updated. The syntax is designed to be concise yet powerful, leveraging the internal logic of Microsoft Excel to handle the heavy lifting.
The specific formula required for this operation is as follows:
=INDEX(A2:A13,RANDBETWEEN(1,ROWS(A2:A13)),1)
The following screenshot illustrates the practical application of this formula within the interface, highlighting the relationship between the source data and the generated result:

Upon entering the formula, you will observe that Microsoft Excel identifies a name—such as Frank in this instance—and displays it in the target cell. It is important to note that the result is not static. Because the functions used are “volatile,” the selected name will change whenever the workbook recalculates. If you wish to trigger a new selection, you can simply double-click the cell and press Enter, or use the F9 shortcut to refresh the entire sheet, ensuring a truly random experience for every use case.
Managing Dynamic Updates and Workbook Recalculation
One of the most important concepts to grasp when working with randomization in spreadsheet software is the nature of volatile functions. Both RAND function and RANDBETWEEN function fall into this category. This means that every time you make a change to any cell in the workbook, Excel triggers a recalculation of these formulas. While this is beneficial for generating new random samples on the fly, it can occasionally lead to confusion if you intended to keep a specific result fixed for a period of time.
To “freeze” a randomly selected name, users often copy the cell and use the “Paste Values” feature. This converts the dynamic formula into a static text string, preserving the result of the algorithm for documentation or reporting purposes. This is a critical step in data analysis workflows where an audit trail is required. Without pasting as values, your random selection might change the next time you open the file or sort another column, potentially undermining the consistency of your selection process.
Understanding recalculation is also vital for performance optimization. In very large workbooks with thousands of random formulas, the constant recalculation can lead to processing delays. However, for the purpose of selecting names from a list of several hundred or thousand entries, the impact is negligible. By mastering the balance between dynamic volatility and static reporting, you can ensure that your Microsoft Excel models remain both accurate and user-friendly.
Advanced Strategy for Multiple Selections Without Duplicate Entries
In many professional scenarios, selecting a single name is insufficient. You may need to select a committee of five people or a subset of ten customers for a focus group. The challenge here is ensuring that the same person is not selected twice—a concept known as sampling without replacement. To achieve this in Microsoft Excel, we utilize a helper column strategy that assigns a unique, random decimal to every name in the original list.
The first step involves creating this helper column in an adjacent space, such as column B. By using the RAND function, we generate a high-precision decimal value between 0 and 1 for each row. Because the RAND function calculates values to many decimal places, the probability of two names receiving the exact same value is virtually zero, which is essential for the next stage of the ranking process.
Enter the following formula into cell B2 and drag it down to the end of your list:
=RAND()
The visual representation below shows how the helper column populates with unique identifiers for each entry, providing the necessary foundation for the subsequent selection logic:

The Architectural Role of Helper Columns in Complex Datasets
Once the helper column is established with random values, we can use the RANK function to determine the relative position of each name. By ranking the random numbers from largest to smallest (or vice versa), we essentially create a randomized order for the entire list. We then use the INDEX function to pull names based on their rank. For example, the name with the highest random number becomes “Rank 1,” the second highest becomes “Rank 2,” and so on.
To extract the first random name based on these rankings, you can use the following formula in cell D2:
=INDEX($A$2:$A$13,RANK(B2,$B$2:$B$13))
By dragging this formula down to subsequent cells (e.g., D3, D4, D5), you can select as many names as you require. Each subsequent cell will look at the random value in its respective row in column B and determine its rank within the entire range of column B, then pull the corresponding name from column A. This method is foolproof for avoiding duplicates because each rank is unique.
The final result is a clean, randomized list of names as shown in the screenshot below. This multi-step approach is the standard professional method for simple random sample generation within a spreadsheet environment, offering both flexibility and precision for high-stakes tasks.

Improving Workflow Efficiency with Automated Randomization
Implementing these techniques significantly enhances the efficiency of any workflow involving selection processes. Instead of manually picking names—which can lead to accusations of favoritism or simple human error—the use of INDEX function and RAND function provides a defensible and objective methodology. This is particularly important in fields such as human resources, finance, and quality assurance, where the integrity of a sample is paramount for compliance and data analysis.
Furthermore, these formulas are highly adaptable. You can expand the ranges to include thousands of rows or modify the INDEX function to return data from multiple columns (such as both a name and an ID number). The logic remains the same: use probability to drive the selection and lookup functions to retrieve the data. This modularity is what makes Microsoft Excel an indispensable tool for data management professionals worldwide.
As you continue to refine your skills, you might explore even newer functions available in modern versions of the software, such as SORTBY or RANDARRAY. However, the methods detailed in this guide remain the most compatible and widely understood across all versions of the application. By mastering these foundational techniques, you ensure that your work is accessible to colleagues using different software versions while maintaining the highest levels of accuracy and sophistication in your spreadsheet operations.
Cite this article
stats writer (2026). How to Randomly Select Names in Excel: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-randomly-select-names-in-excel/
stats writer. "How to Randomly Select Names in Excel: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 15 Feb. 2026, https://scales.arabpsychology.com/stats/how-can-i-randomly-select-names-in-excel/.
stats writer. "How to Randomly Select Names in Excel: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-randomly-select-names-in-excel/.
stats writer (2026) 'How to Randomly Select Names in Excel: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-randomly-select-names-in-excel/.
[1] stats writer, "How to Randomly Select Names in Excel: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Randomly Select Names in Excel: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.