Table of Contents
Introduction to the Kruskal-Wallis H Test
The Kruskal-Wallis H test, often referred to as the one-way ANOVA on ranks, is a non-parametric statistical procedure used to determine if there are statistically significant differences between three or more independent groups of an independent variable on a continuous or ordinal dependent variable. Unlike the standard One-Way ANOVA, which relies on the comparison of means, the Kruskal-Wallis test evaluates the medians of the groups. This makes it an incredibly robust tool for researchers who are dealing with data that does not follow a normal distribution or contains significant outliers that might skew the results of a parametric test.
In the realm of inferential statistics, choosing the correct test is paramount to the integrity of your findings. The Kruskal-Wallis test is particularly useful when the assumptions of normality are violated, or when the data is measured on an ordinal scale where the intervals between values are not necessarily equal. By transforming raw data into ranks, the test minimizes the influence of extreme values, providing a more accurate reflection of the central tendency within skewed datasets. This approach ensures that the statistical power remains high even when the strict requirements of parametric modeling cannot be met.
Performing a Kruskal-Wallis test in Microsoft Excel is a straightforward process that leverages the software’s built-in mathematical functions to handle complex calculations. While Excel is often viewed primarily as a spreadsheet tool, its capabilities for data analysis are extensive, allowing users to conduct sophisticated hypothesis testing without the need for specialized statistical software. This guide will walk you through the entire process, from initial data organization to the final interpretation of the p-value, ensuring you can make informed, data-driven decisions with confidence.
When to Choose Kruskal-Wallis Over One-Way ANOVA
The decision to use the Kruskal-Wallis test instead of a One-Way ANOVA usually hinges on the nature of your data and the fulfillment of specific statistical assumptions. The One-Way ANOVA is a parametric test that assumes your data follows a normal distribution and that the variances across groups are equal, a condition known as homoscedasticity. When these conditions are met, the ANOVA is the more powerful test; however, in many real-world scenarios—such as biological research or social science surveys—data is frequently non-normal or contains heteroscedastic variances.
If your exploratory data analysis reveals that your residuals are not normally distributed, or if you are working with small sample sizes where the Central Limit Theorem cannot be reliably invoked, the Kruskal-Wallis test becomes the preferred alternative. It is also the standard choice when your dependent variable is ranked or ordinal, such as Likert scale responses (e.g., “strongly disagree” to “strongly agree”). Because the Kruskal-Wallis test does not assume a specific distribution, it is considered a distribution-free test, offering a layer of protection against Type I errors that might occur if a parametric test were forced upon unsuitable data.
Furthermore, the Kruskal-Wallis test is highly resistant to the impact of outliers. In a mean-based test like the ANOVA, a single extreme value can significantly shift the group average and increase the variance, potentially masking a true effect or creating a false one. By contrast, the non-parametric nature of the Kruskal-Wallis test replaces those extreme values with their relative ranks. This ensures that an outlier is treated simply as the “highest” or “lowest” value, rather than a value that is mathematically ten times larger than the rest, preserving the statistical significance of the overall group comparison.
Core Assumptions of the Kruskal-Wallis Test
While the Kruskal-Wallis test is more flexible than its parametric counterparts, it still requires several fundamental assumptions to be met for the results to be valid and interpretable. First and foremost, the dependent variable should be measured at the ordinal or continuous level. This includes interval or ratio data that has been downgraded to ranks. The test is specifically designed to compare the distributions of these values across different categories, making it essential that the data can be logically ordered from lowest to highest.
The second major assumption is that the independent variable should consist of three or more categorical, independent groups. This means that there should be no relationship between the participants or observations in each group. For instance, a plant growth study where different plants receive different fertilizers fits this criterion perfectly. If the groups were related—such as measuring the same plant at three different time intervals—you would instead need to use a Friedman test, which is the non-parametric version of a repeated measures ANOVA.
Lastly, for the test to specifically compare medians, the distributions in each group must have a similar shape. If the groups have differently shaped distributions (e.g., one is skewed left while another is skewed right), the Kruskal-Wallis test technically compares the mean ranks rather than the medians. While this is still a valid test for determining if the samples come from the same distribution, researchers must be careful in how they phrase their conclusions. Ensuring independence of observations is also vital, as any correlation between data points can lead to an inflation of the test statistic and inaccurate results.
Data Preparation and Organization in Excel
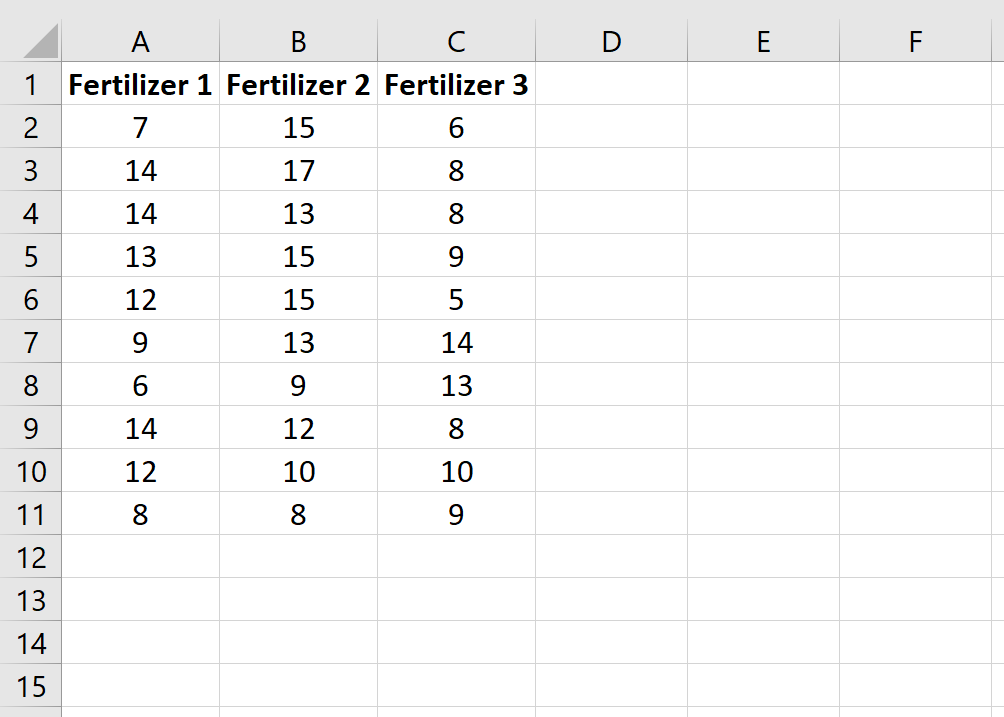
Before you can perform any calculations, your data must be meticulously organized within your Excel worksheet. A common and effective method is to arrange your data in a columnar format, where each column represents a different level of your independent variable. For example, if you are testing the efficacy of three different fertilizers, you would label columns A, B, and C as “Fertilizer 1,” “Fertilizer 2,” and “Fertilizer 3,” respectively. Each row under these headers would then contain the individual growth measurements for the plants assigned to that specific treatment.
Ensure that there are no empty cells or non-numeric characters within your data range, as these can cause errors in the ranking functions. It is also helpful to keep your sample sizes clearly visible. While the Kruskal-Wallis test does not require equal sample sizes across groups—making it an excellent choice for unbalanced designs—knowing the exact “n” for each group is necessary for the final formula calculation. Clear labeling at this stage will prevent confusion when you begin applying complex formulas like RANK.AVG later in the process.
The following image illustrates the ideal layout for raw data. Note how each group is isolated into its own column, making it easy to reference specific ranges for calculations. This structured approach is the foundation of accurate data analysis and allows for easier troubleshooting if your final H-statistic appears incorrect.

Step 1: Ranking Your Data Using the RANK.AVG Function
The primary mechanism of the Kruskal-Wallis test is the conversion of raw scores into ranks. Instead of looking at the actual inches of growth, the test looks at which plant grew the most relative to all 30 plants in the study. To do this in Excel, we use the RANK.AVG function. This specific function is crucial because it handles tied ranks by assigning the average rank to all tied values. For example, if two plants both grew exactly 12 inches and they would have occupied the 4th and 5th positions, RANK.AVG assigns both a rank of 4.5.
To rank your data, you must compare each individual value against the entire dataset combined, not just the values within its own group. The formula typically follows the structure =RANK.AVG(Cell, Total_Range, 1), where the “1” specifies that we are ranking in ascending order (the smallest value gets rank 1). By using absolute cell references (indicated by dollar signs, e.g., $A$2:$C$11) for the total range, you can easily drag the formula across your worksheet to generate ranks for every observation across all three groups.
This process transforms your data from a ratio scale to an ordinal scale, effectively neutralizing the impact of any extreme values or non-normal distribution patterns. The image below demonstrates the application of this formula for the first data point in the first group. Understanding this step is vital, as the entire statistical power of the Kruskal-Wallis test depends on the accuracy of these assigned ranks.

Step 2: Calculating Group Rank Sums and Sample Sizes
Once every data point has been assigned a rank, the next step is to aggregate these ranks within their respective groups. You will need to calculate three specific values for each group: the count of observations (n), the sum of the ranks (R), and the squared sum of ranks divided by n (R²/n). These components are the building blocks of the test statistic H. Excel’s SUM() and COUNT() functions make this part of the analysis very efficient.
First, calculate the sum of the ranks for each column. This tells us the total “ranking weight” held by each fertilizer group. Next, determine the sample size for each group; in our example, each group has 10 plants. Finally, square the sum of the ranks for each group and divide that number by the group’s sample size. This weighting process is essential because it accounts for potential differences in group sizes, ensuring that larger groups do not disproportionately influence the final result simply because they have more data points.
The screenshot below shows how to organize these intermediate calculations. By setting up a table with these values, you simplify the final Kruskal-Wallis formula. Keeping your work organized in this manner reduces the risk of manual calculation errors and provides a clear audit trail for your statistical analysis, which is a hallmark of professional data management.


Step 3: Computing the Kruskal-Wallis H Statistic
With the rank sums and sample sizes in hand, you are ready to calculate the H statistic. The Kruskal-Wallis formula might look intimidating at first glance, but it is actually a series of simple arithmetic operations. The formula is expressed as:
H = [12 / (n(n+1))] * [Σ(Rj² / nj)] – 3(n+1)
In this equation, n represents the total sample size across all groups (in our case, 30), and Rj is the sum of ranks for each individual group. The constant “12” and “3” are derived from the properties of the distribution of ranks. The H-statistic essentially measures the variance of the rank sums across the groups. If the groups are very similar, H will be small; if the groups are very different (i.e., one group has mostly high ranks and another has mostly low ranks), H will be large.
In Excel, you can input this formula using cell references to your previous calculations. It is important to remember that under the null hypothesis, the H statistic follows a Chi-square distribution. This relationship allows us to determine the likelihood of obtaining our observed H value by chance. The degrees of freedom for this test are calculated as k – 1, where k is the number of independent groups. In our example with three fertilizers, the degrees of freedom would be 2.
The following screenshot provides a visual guide to the Excel formulas used to compute both the H statistic and the resulting p-value. Accuracy is paramount here, as a single misplaced parenthesis can lead to an incorrect statistical conclusion.

Step 4: Determining the P-Value and Significance
The final numerical step in our hypothesis test is to find the p-value. The p-value tells us the probability of observing a test statistic as extreme as ours, assuming that the null hypothesis (that all group medians are equal) is true. To calculate this in Excel, we use the CHISQ.DIST.RT() function, which returns the right-tailed probability of the chi-squared distribution. The syntax is =CHISQ.DIST.RT(H_value, Deg_Freedom).
In our plant growth example, the calculated H statistic is 6.204. When we plug this into the chi-square distribution function with 2 degrees of freedom, we obtain a p-value of 0.045. In most scientific research, the standard threshold for statistical significance is an alpha level of 0.05. Since 0.045 is less than 0.05, we have sufficient evidence to reject the null hypothesis. This indicates that the type of fertilizer used does indeed have a significant impact on plant growth.
It is important to note that a significant Kruskal-Wallis test does not tell you which specific groups are different from one another—only that at least one pair is different. If you find a significant result, you would typically follow up with a post-hoc analysis, such as Dunn’s Test, to perform pairwise comparisons between the groups. This secondary step allows you to pinpoint exactly where the differences lie, providing a more granular understanding of your data.
Interpreting Your Results and Drawing Conclusions
The interpretation of a Kruskal-Wallis test should always be contextualized within the original research question. In our scenario, the goal was to determine if different fertilizers resulted in different growth levels. Because our p-value fell below the 0.05 threshold, we conclude that the fertilizers are not equally effective. This finding is statistically significant, meaning it is unlikely to have occurred due to random chance alone.
When discussing these results, focus on the median ranks. While the raw means might show differences, the Kruskal-Wallis test confirms that the overall distribution of ranks is shifted significantly for at least one fertilizer. This is a powerful conclusion because it suggests that the effect of the fertilizer is consistent enough to survive a non-parametric ranking process. If the p-value had been greater than 0.05, we would have failed to reject the null hypothesis, suggesting that any observed differences in growth were likely due to sampling error.
Always consider the effect size in addition to the p-value. While the Kruskal-Wallis test identifies significance, it doesn’t describe the magnitude of the difference. Researchers often use epsilon-squared or other metrics to quantify how much of the variance in the dependent variable is explained by the independent variable. This adds depth to your analysis and helps stakeholders understand the practical importance of your findings beyond just the “significant” or “not significant” binary.
Best Practices for Reporting Statistical Findings
The final phase of any data analysis project is reporting the results in a clear, professional manner that adheres to academic or industry standards. A standard report of a Kruskal-Wallis test should include the name of the test, the degrees of freedom, the H statistic (sometimes denoted as χ²), and the p-value. It is also standard practice to include the sample sizes for each group and a description of the central tendency (usually medians) observed.
An example of a formal summary would be: “A Kruskal-Wallis H test was conducted to determine if there were differences in plant growth among three types of fertilizers (n=30). The test revealed a statistically significant difference in plant growth levels between the fertilizers (H(2) = 6.204, p = .045).” This concise statement provides all the necessary technical details while clearly conveying the primary takeaway of the research.
By following this structured approach in Excel, you ensure that your non-parametric data analysis is both rigorous and reproducible. Whether you are a student, a researcher, or a business analyst, mastering the Kruskal-Wallis test allows you to extract meaningful insights from complex, non-normal datasets. Excel provides all the tools necessary to perform this analysis accurately, making high-level inferential statistics accessible to anyone with a basic understanding of spreadsheet functions and statistical logic.
Cite this article
stats writer (2026). How to Perform a Kruskal-Wallis Test in Excel: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-perform-a-kruskal-wallis-test-in-excel/
stats writer. "How to Perform a Kruskal-Wallis Test in Excel: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 10 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-i-perform-a-kruskal-wallis-test-in-excel/.
stats writer. "How to Perform a Kruskal-Wallis Test in Excel: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-perform-a-kruskal-wallis-test-in-excel/.
stats writer (2026) 'How to Perform a Kruskal-Wallis Test in Excel: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-perform-a-kruskal-wallis-test-in-excel/.
[1] stats writer, "How to Perform a Kruskal-Wallis Test in Excel: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Perform a Kruskal-Wallis Test in Excel: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.