Table of Contents
Introduction to Linear Regression and Residual Analysis
In the realm of statistical modeling, particularly when employing linear regression, the primary goal is to establish a mathematical relationship between a dependent variable and one or more independent variables. While fitting a line to a dataset is a relatively straightforward computational task, ensuring that the model accurately represents the underlying data distribution requires a deeper investigation. This investigation is often conducted through the analysis of residuals, which represent the difference between the observed data points and the values predicted by the model. By examining these discrepancies, researchers can verify if the assumptions of the regression model are met or if the model requires further refinement.
The process of generating a residual plot in R provides a visual diagnostic tool that is far more intuitive than raw numerical output. When we use the “plot” function or specialized diagnostic functions, we are essentially looking for patterns in the “noise” that the model failed to capture. If a model is well-specified, the residuals should appear as random white noise, indicating that the model has successfully extracted all the systematic information from the data. Conversely, discernible patterns in a residual plot suggest that the model may be missing interaction terms, non-linear relationships, or that it suffers from other statistical deficiencies.
Furthermore, the R programming language offers a robust suite of built-in functions specifically designed to simplify this diagnostic workflow. Whether you are a data scientist working on complex machine learning algorithms or a student performing basic academic research, understanding how to construct and interpret these plots is essential. This tutorial will guide you through the technical steps of fitting a model, extracting residual values, and generating three distinct types of plots to assess normality and homoscedasticity with precision and clarity.
The Critical Role of Residual Plots in Statistics
The validity of a regression analysis hinges upon several key assumptions, most notably the requirement that the residuals follow a normal distribution and maintain a constant variance. This constant variance, known as homoscedasticity, ensures that the model’s predictive power remains consistent across all levels of the independent variables. If the variance changes—a condition known as heteroscedasticity—the standard errors of the regression coefficients may be biased, leading to unreliable p-values and misleading confidence intervals.
Visualizing residuals allows a researcher to identify outliers and influential data points that might disproportionately affect the slope of the regression line. While numerical tests like the Breusch-Pagan test or the Shapiro-Wilk test provide formal confirmation, they do not offer the same level of insight into the nature of the violation as a plot does. A plot can reveal if the relationship is actually curved, suggesting that a polynomial regression might be more appropriate than a simple linear one.
By integrating these visual checks into your data analysis pipeline, you transition from simply “running a model” to truly “understanding the data.” This proactive approach to model validation is a hallmark of rigorous science. In R, the ease with which these plots can be generated makes it inexcusable to overlook this step in any serious analytical project. The following sections will demonstrate how to perform these checks using the legendary mtcars dataset as a practical example.
Preparation: Data Selection and Environment Setup
Before we can generate any diagnostic plots, we must first establish a dataset and fit a statistical model. For this demonstration, we utilize the mtcars dataset, which is a classic resource available within the base R environment. This dataset contains technical specifications and performance metrics for 32 automobiles from the 1973–74 Motor Trend magazine, making it an excellent candidate for exploring the relationships between fuel efficiency and engine characteristics.
To begin, we load the data and inspect its structure to ensure we understand the variables at play. In this specific scenario, we are interested in how the variables “displacement” and “horsepower” contribute to a vehicle’s “miles per gallon” (MPG). These variables often exhibit complex relationships, which makes them ideal for testing the assumptions of linear regression. Setting up the environment is a simple matter of calling the data and preparing the workspace for model construction.
The first technical step involves fitting the linear model using the lm() function. This function uses the method of Ordinary Least Squares (OLS) to minimize the sum of the squared differences between the observed and predicted values. Once the model is fitted, we can programmatically extract the residuals for further inspection, as shown in the code block below.
#load the dataset data(mtcars) #fit a regression model model <- lm(mpg~disp+hp, data=mtcars) #get list of residuals res <- resid(model)
Evaluating Variance with the Residual vs. Fitted Plot
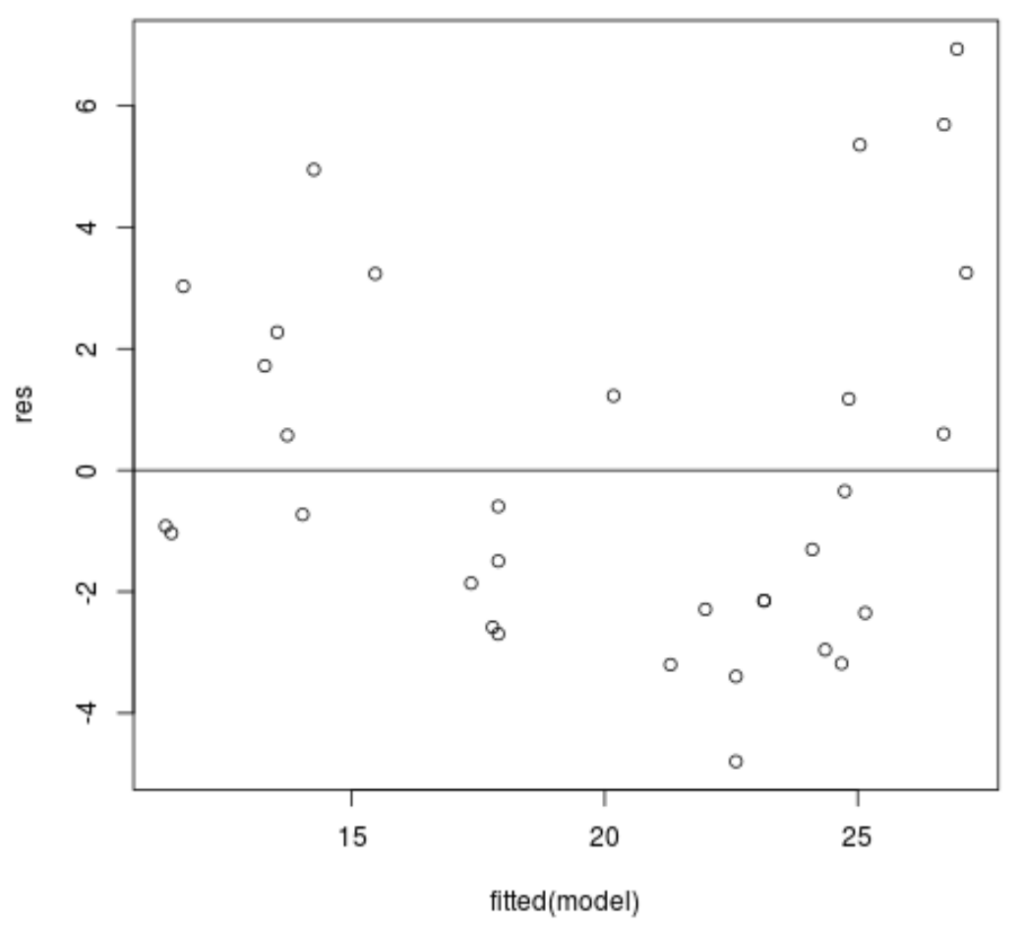
Once the model is established, the next priority is to examine the residuals relative to the fitted values. A Residual vs. Fitted plot is a fundamental diagnostic tool used to detect heteroscedasticity. In a perfect model, the residuals should be scattered randomly around the horizontal axis at zero, showing no discernible shape or trend. This indicates that the variance of the error terms is constant, satisfying one of the core Gauss-Markov assumptions.
To create this plot in R, we use the plot() function with the model’s fitted values on the x-axis and the calculated residuals on the y-axis. Adding a horizontal line at zero using the abline() function is a crucial step, as it provides a baseline for evaluating the symmetry of the residual distribution. If the points “fan out” or form a “funnel” shape as the fitted values increase, it is a clear indication that the model’s error variance is not constant.
In our mtcars example, we generate this plot to see if the engine displacement and horsepower variables result in consistent errors across different levels of fuel efficiency. Below is the code required to generate this visualization and the resulting graphical output.
#produce residual vs. fitted plot plot(fitted(model), res) #add a horizontal line at 0 abline(0,0)

Upon reviewing the plot, the x-axis represents the predicted values for MPG, while the y-axis shows the deviation of the actual data from those predictions. While there is a slight increase in the spread of residuals at higher fitted values, the deviation is generally considered minor. In a professional data science context, this suggests that the linear model is a reasonably good fit, though a researcher might remain cautious about predictions at the higher end of the scale.
Testing for Normality using Quantile-Quantile Plots
Another essential check in regression diagnostics is determining whether the residuals follow a normal distribution. This is vital because the validity of statistical significance tests (like the t-test and F-test) relies on the assumption of normally distributed errors. A Q-Q plot (Quantile-Quantile plot) facilitates this by plotting the quantiles of our residual distribution against the quantiles of a theoretical normal distribution.
In R, the qqnorm() function generates the plot, and qqline() adds a reference line passing through the first and third quartiles. If the residuals are perfectly normal, the points will fall exactly on this diagonal line. Deviations from the line, particularly at the ends (the “tails”), indicate skewness or kurtosis, suggesting that the errors may have “heavy tails” or are otherwise non-normal.
By applying this to our linear model, we can observe the behavior of the residuals in the extreme ranges. The code and visual output below demonstrate how to implement this essential diagnostic step.
#create Q-Q plot for residuals qqnorm(res) #add a straight diagonal line to the plot qqline(res)

The resulting Q-Q plot shows that while the middle portion of the residuals aligns well with the theoretical line, the points at both ends tend to curve away. This “tailing off” suggests that the distribution of residuals might have more extreme values than would be expected under a perfect normal distribution. Such a finding might prompt a researcher to investigate data transformations, such as taking the log of the dependent variable, to achieve better normality.
Analyzing Frequency Distributions with Density Plots
To complement the Q-Q plot, a density plot offers a direct visual representation of the residual distribution’s shape. While the Q-Q plot is excellent for identifying tail behavior, the density plot allows us to see the “peak” and general symmetry of the errors. We are looking for a classic, symmetrical “bell-shaped curve” centered around zero. Any significant skewness—where the curve leans to one side—can indicate that the model is consistently overestimating or underestimating certain values.
The density() function in R computes kernel density estimates, which are then visualized using the standard plot() function. This provides a smoothed version of a histogram, making it easier to identify the underlying distribution without the noise associated with bin sizes. It is a powerful way to verify the normality assumption through a different lens.
Executing this in our workflow provides the final piece of the diagnostic puzzle for our mtcars model. The code snippet below illustrates how to generate this density visualization efficiently.
#Create density plot of residuals plot(density(res))

Our density plot reveals a shape that is approximately bell-shaped, confirming that the residuals are somewhat normally distributed. However, there is a visible right-hand skew, meaning there are a few cars in the dataset where the model predicts much lower MPG than they actually achieve. Depending on the goals of the study, this might be acceptable, or it might lead a statistician to consider a Box-Cox transformation to stabilize the variance and improve the distribution.
Interpreting Results and Model Improvements
Interpreting residual plots is as much an art as it is a science. After generating these visualizations in R, the next logical step is to decide on a course of action. If your plots show significant heteroscedasticity or non-normality, you cannot simply ignore these findings, as they undermine the statistical significance of your entire regression model. Instead, you must look for ways to improve the model’s fit.
Common strategies for addressing issues identified in residual plots include adding interaction terms between existing variables or including non-linear terms (like squared or cubed variables) to capture curvature. In many cases, the issue lies with the scale of the dependent variable. Applying a logarithmic or square root transformation can often pull in outliers and produce residuals that are much closer to a normal distribution.
Ultimately, the goal of creating a residual plot in R is to gain confidence in your results. A clean set of diagnostic plots serves as a “green light,” indicating that your linear regression model is robust and that the conclusions you draw from it are based on sound statistical foundations. By following the steps outlined in this tutorial, you ensure that your data analysis is both accurate and professional.
Summary of Best Practices for Residual Analysis
To ensure the highest quality in your statistical modeling, it is helpful to follow a consistent set of best practices when performing residual analysis. Always start with a visual inspection before moving to formal tests. While numerical values are objective, they can sometimes be misleading in small datasets or datasets with extreme outliers. The residual plot provides the necessary context to understand why a test might be failing.
- Always plot residuals against fitted values to check for homoscedasticity.
- Utilize Q-Q plots to verify the assumption of normality for your error terms.
- Consider using density plots as a secondary check for distribution symmetry and skewness.
- Investigate any point that sits far away from the others, as these outliers can have a disproportionate impact on your model.
- Remember that no model is perfect; the goal is to create a model that is “useful” and fits the data well enough to provide reliable insights.
By mastering these techniques in R, you elevate your analytical capabilities. The ability to diagnose and correct model deficiencies is what separates a novice from an expert researcher. Whether you are analyzing automotive data like the mtcars set or complex economic indicators, these principles of residual analysis remain the gold standard for model validation.
Cite this article
stats writer (2026). How to Create Residual Plots in R for Model Diagnostics. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-create-a-residual-plot-in-r/
stats writer. "How to Create Residual Plots in R for Model Diagnostics." PSYCHOLOGICAL SCALES, 11 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-i-create-a-residual-plot-in-r/.
stats writer. "How to Create Residual Plots in R for Model Diagnostics." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-create-a-residual-plot-in-r/.
stats writer (2026) 'How to Create Residual Plots in R for Model Diagnostics', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-create-a-residual-plot-in-r/.
[1] stats writer, "How to Create Residual Plots in R for Model Diagnostics," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Create Residual Plots in R for Model Diagnostics. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.