Table of Contents
The process of calculating the P-value of an F-statistic within Excel is a fundamental skill for data analysts and researchers. This procedure typically involves leveraging specialized built-in functions such as FDIST or F.DIST.RT to determine the cumulative probability associated with a specific test result. By inputting the calculated F-statistic along with the appropriate degrees of freedom for both the numerator and the denominator, users can derive a precise probability value. This resulting P-value serves as the primary metric for evaluating the statistical significance of an observed effect, allowing practitioners to make informed decisions regarding the null hypothesis. Utilizing these computational tools ensures that complex statistical derivations are handled with both speed and accuracy, which is essential for rigorous data interpretation.
Foundations of the F-Test and Statistical Significance
In the realm of quantitative analysis, an F-test is a statistical procedure used to compare the variances of two different populations or to assess the overall fit of a regression model. The test generates an F-statistic, which represents the ratio of explained variance to unexplained variance. To ascertain the probability that such a result could have occurred under the null hypothesis, analysts must find the corresponding P-value. In Excel, this calculation is streamlined through the use of specific formulas designed to query the F-distribution curve.
The primary command utilized for modern statistical analysis in Excel is the right-tailed distribution function. This is particularly useful because the F-test is almost exclusively a right-tailed test, focusing on whether the ratio of variances is significantly greater than what would be expected by random chance. By applying this function, users can transform a raw F-statistic into a meaningful probability that informs whether the observed data deviates significantly from the expected values defined by the null hypothesis.
To identify the P-value associated with an F-statistic within the Excel environment, the following syntax is required: =F.DIST.RT(x, degree_freedom1, degree_freedom2). This function acts as a bridge between theoretical F-distributions and practical data application. It requires three specific arguments to provide an accurate result: the test statistic itself and the two distinct parameters of degrees of freedom that characterize the specific distribution being analyzed.
Deconstructing the Arguments of the F.DIST.RT Function
Understanding the components of the F.DIST.RT function is crucial for ensuring the accuracy of your statistical significance tests. The first argument, x, represents the calculated F-statistic. This value is derived from your data, often from an ANOVA table or a regression model output. It is essentially the ratio that the function will evaluate against the F-distribution to determine how far into the “tail” of the distribution the result falls.
The second and third arguments, degree_freedom1 and degree_freedom2, are the degrees of freedom for the numerator and denominator, respectively. In the context of a regression model, the numerator degrees of freedom typically correspond to the number of independent variables being tested. The denominator degrees of freedom are generally related to the sample size minus the number of parameters being estimated. Correctly identifying these values is vital, as the shape of the F-distribution changes significantly based on these parameters.
- x: This is the numerical value of the F-statistic that you have calculated from your dataset.
- degree_freedom1: This refers to the numerator degrees of freedom, representing the constraints related to the groups or variables being compared.
- degree_freedom2: This refers to the denominator degrees of freedom, representing the error or residual constraints in the analysis.
Practical Application: A Calculation Demonstration
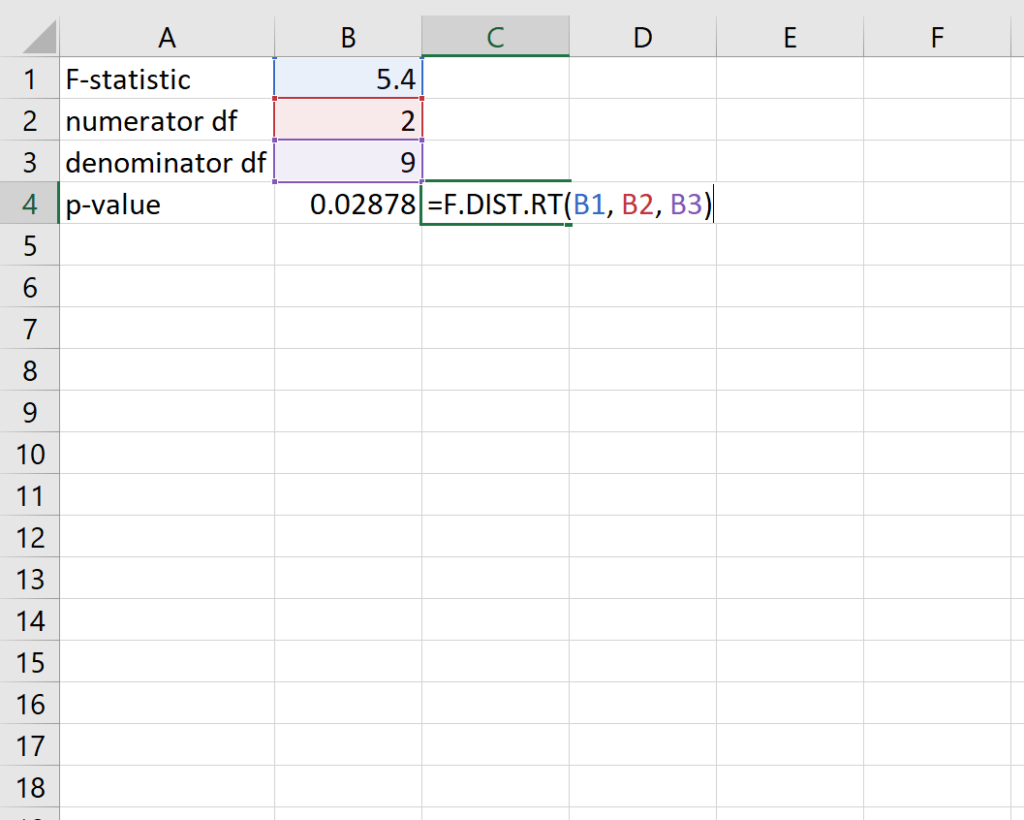
To illustrate the application of these concepts, consider a scenario where a researcher has calculated an F-statistic of 5.4. In this specific study, the experimental design results in a numerator degrees of freedom value of 2 and a denominator degrees of freedom value of 9. By inputting these parameters into the Excel function, the user can instantly obtain the probability of observing such a result if the null hypothesis were true.

Upon executing the formula in a spreadsheet cell, Excel returns a P-value of 0.02878. This number is the key to the entire statistical investigation. Because this value is less than the common significance level threshold of 0.05, the researcher would typically conclude that the results are statistically significant. This objective measure removes the guesswork from data analysis, providing a mathematical basis for scientific or business conclusions.
In various professional fields, from pharmacology to economics, the F-test is frequently employed during ANOVA procedures. In the following sections, we will explore how this process applies to a more complex regression model, which is perhaps the most common use case for the F-statistic in modern data science and predictive analytics.
Example: Calculating P-Value from Regression F-Statistics
Imagine we are analyzing a dataset designed to predict academic performance. The dataset includes observations for 12 different students, tracking the total number of hours they studied, the number of preparatory exams they completed, and the final scores they achieved on their exams. This multi-variable approach requires a linear regression model to understand the relationship between study habits and outcomes.

By fitting a linear regression model to this data, we designate “study_hours” and “prep_exams” as our explanatory variables, while the “score” serves as our response variable. The goal of the F-test in this context is to determine if the group of explanatory variables, taken together, has a statistically significant relationship with the response variable. If the P-value is low, we can state with confidence that our model provides a better fit than a model with no independent variables.
After running the regression analysis tool in Excel, the software generates a summary output table. This table includes the F-statistic for the overall model, which helps us judge the validity of the entire predictive framework rather than looking at individual coefficients in isolation.

In this specific regression output, the calculated F-statistic for the overall model is 5.0905. To understand the significance of this number, we look at the associated degrees of freedom. In this case, there are 2 degrees of freedom for the numerator (representing our two predictors: hours and exams) and 9 degrees of freedom for the denominator (representing the residual errors from our 12 observations).
Interpreting the Regression P-Value Output
Once the F-statistic is established, Excel automatically computes the P-value for the entire model. For our student dataset, the software identifies that the P-value for this F-statistic is 0.0332. This value is critical because it tells us whether the correlation we are seeing in the sample is likely to exist in the broader population.

A P-value of 0.0332 suggests that there is only a 3.32% chance that we would see such a strong relationship between study habits and exam scores if there were actually no relationship at all. Since this is below the standard 5% threshold, we reject the null hypothesis and conclude that the regression model is statistically significant.
While Excel provides this value automatically in its regression summary, it is often useful to perform the calculation manually to verify results or to build custom dashboards. Using the F.DIST.RT function manually allows for greater flexibility in how the data is presented and manipulated within a larger spreadsheet project.

As demonstrated in the image above, applying the formula manually yields the exact same P-value as the automated regression output. This consistency confirms that the underlying mathematical logic used by Excel remains uniform regardless of whether you are using the Data Analysis Toolpak or writing your own formulas.
Advanced Considerations for F-Distribution Analysis
When working with F-distributions, it is important to distinguish between the various versions of the F-test function available in Excel. While F.DIST.RT provides the right-tailed probability, the standard F.DIST function can provide the cumulative probability from the left. Choosing the correct function is essential for aligning your spreadsheet calculations with the specific statistical hypothesis you are testing.
Furthermore, analysts should always be mindful of the assumptions underlying the F-test. These include the assumption that the data is normally distributed and that the samples being compared have independent observations. If these assumptions are violated, the P-value generated by Excel may lead to incorrect conclusions, highlighting the importance of thorough exploratory data analysis before proceeding to formal testing.
In conclusion, calculating the P-value of an F-statistic is a straightforward process in Excel once the user understands the relationship between the test statistic and the degrees of freedom. Whether you are conducting a simple variance comparison or a complex multivariate regression analysis, these tools provide the quantitative rigor necessary for high-level data interpretation and decision-making.
Cite this article
stats writer (2026). How to Find the P-value of an F-Statistic in Excel. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-i-calculate-the-p-value-of-an-f-statistic-in-excel/
stats writer. "How to Find the P-value of an F-Statistic in Excel." PSYCHOLOGICAL SCALES, 12 Mar. 2026, https://scales.arabpsychology.com/stats/how-do-i-calculate-the-p-value-of-an-f-statistic-in-excel/.
stats writer. "How to Find the P-value of an F-Statistic in Excel." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-do-i-calculate-the-p-value-of-an-f-statistic-in-excel/.
stats writer (2026) 'How to Find the P-value of an F-Statistic in Excel', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-i-calculate-the-p-value-of-an-f-statistic-in-excel/.
[1] stats writer, "How to Find the P-value of an F-Statistic in Excel," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Find the P-value of an F-Statistic in Excel. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.