Table of Contents
The Importance of Precision in Spreadsheet Data Management
In the contemporary landscape of data analysis, the ability to manipulate and refine text strings is a fundamental skill for any professional utilizing Google Sheets. Often, raw data imported from external sources—such as CRM systems, web scrapers, or financial reports—arrives in a concatenated format that is not immediately useful for granular reporting. For instance, a single cell might contain a full name, a date, and a specific identifier, all separated by unique delimiters. Mastering the art of isolating specific segments of this data is essential for maintaining a clean and functional database.
The process of extracting text before a specific character or string is a common requirement in data cleaning workflows. By automating this task, users can transform cluttered datasets into organized, structured information that is ready for pivoting, charting, or further statistical analysis. Traditional methods often involve manual editing, which is not only time-consuming but also prone to human error, especially when dealing with thousands of rows of information. Consequently, leveraging built-in functions to handle these transformations is the hallmark of an efficient spreadsheet user.
While basic functions like LEFT and FIND offer a rudimentary solution for simple extraction tasks, they often fall short when faced with complex patterns or variable string lengths. This is where more advanced tools come into play, providing the flexibility and power needed to handle diverse data structures. By understanding the underlying logic of these functions, users can create robust formulas that adapt to the nuances of their specific datasets, ensuring that the extracted information remains accurate and reliable across different use cases.
Furthermore, the ability to extract substrings is vital for metadata management and the creation of dynamic reports. When you can programmatically strip away unnecessary characters, you empower yourself to generate insights that would otherwise be buried within a messy cell. This guide focuses on the most sophisticated and adaptable method available in Google Sheets: the application of the REGEXEXTRACT function to isolate text preceding a specific marker.
Understanding the REGEXEXTRACT Function for Advanced Parsing
The REGEXEXTRACT function is perhaps the most versatile tool in the Google Sheets arsenal for text manipulation. Unlike simpler functions that rely on static character counts, this function utilizes regular expressions—a powerful sequence of characters that define a search pattern. Regular expressions (often abbreviated as regex) are a standard in computer science and programming, allowing for highly specific and complex searching, matching, and extraction operations within a body of text.
Using REGEXEXTRACT allows a user to specify exactly what part of a string they wish to retrieve by defining the context surrounding that text. The function follows a specific syntax: =REGEXEXTRACT(text, regular_expression). The first argument refers to the cell containing the data, while the second argument is the pattern you wish to match. This approach is significantly more powerful than the LEFT function because it does not require you to know the exact position of a character; instead, you only need to know the pattern or the character that follows your desired text.
One of the primary advantages of using regular expressions within Google Sheets is the ability to handle variability. For example, if you are extracting text before a colon, but the length of that text varies from row to row, a standard regex pattern will automatically adjust to capture everything until the colon is reached. This dynamic extraction is crucial for maintaining spreadsheet scalability, as the formula will continue to function correctly even as new data with different lengths is added to the sheet.
To successfully implement this function, one must understand the basic building blocks of regex. These include wildcards, anchors, and quantifiers. While the learning curve for regular expressions can be steep, the specific application of extracting text before a character is relatively straightforward and serves as an excellent introduction to this powerful technology. By mastering a few key patterns, users can solve a vast majority of their data parsing challenges without needing to write complex scripts or use external tools.
Deconstructing the Extraction Formula
To extract all text before a specific character or word in Google Sheets, you can utilize a specialized regex pattern within the REGEXEXTRACT function. The standard formula structure for this operation is as follows:
=REGEXEXTRACT(A2,"(.*)our.*")
This formula is designed to scan the content of cell A2 and identify the substring “our”. It then instructs the function to return everything that occurs before that specific string. Understanding the components of the regular expression string "(.*)our.*" is essential for customizing the formula to your needs. The parentheses () are known as a capturing group. In REGEXEXTRACT, the function only returns the text that matches the pattern within the parentheses. This is why we place the extraction logic inside them, while the delimiter remains outside or is handled by a secondary pattern.
Inside the parentheses, we see .*. In the world of regex, the period . represents a wildcard that matches any single character (except line breaks), and the asterisk * is a quantifier that means “zero or more of the preceding element.” Together, .* matches every character in the cell. When followed by a specific string like “our”, the engine looks for the longest possible sequence of characters that is followed by the characters ‘o’, ‘u’, and ‘r’.
The final .* outside of the capturing group but within the quotes ensures that the entire string in the cell is accounted for in the match, though it is not returned in the result. This prevents the function from throwing an error if there is additional text after the “our” delimiter. By structuring the formula this way, you create a precise “cut point” for your data extraction. This method is highly deterministic and ensures that only the relevant portion of the string is pulled into your target cell.
Step-by-Step Practical Example: Extracting Text Before a String
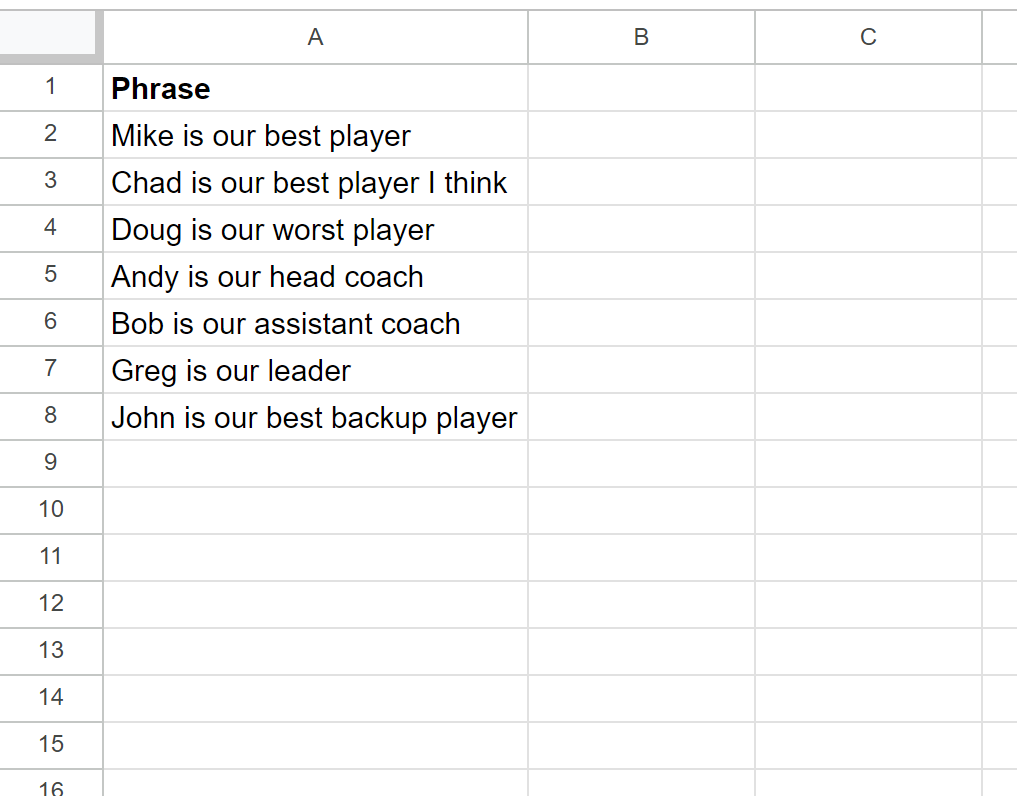
To demonstrate the practical application of this formula, let us consider a dataset consisting of various descriptive phrases. Our objective is to isolate the beginning of each phrase, specifically everything that appears before the word “our” is encountered. This type of task is common when dealing with natural language data or logs where a specific keyword acts as a separator between a prefix and the rest of the information.
Imagine your spreadsheet contains the following data in Column A:

To perform the extraction, you would initiate the process by selecting the adjacent cell, B2, and entering the REGEXEXTRACT formula. This formula targets the source text in A2 and applies the pattern discussed in the previous section. The Google Sheets engine evaluates the string and identifies the first instance of “our,” then captures every character preceding it.
=REGEXEXTRACT(A2,"(.*)our.*")
Once the formula is entered into cell B2, the extracted text will appear instantly. To apply this logic to the rest of your dataset, you can use the fill handle (the small square at the bottom-right corner of the selected cell) to click and drag the formula down through column B. This action utilizes relative cell referencing, meaning the formula automatically updates to reference A3, A4, and so on, as it is moved down the column.

As shown in the resulting image, Column B now contains only the text that appeared before the word “our.” This method is incredibly efficient for cleaning up unstructured data. It provides a level of precision that ensures no trailing spaces or extra characters are included, provided your regex pattern is correctly defined to handle them.
Customizing the Formula for Different Characters and Delimiters
The true strength of the REGEXEXTRACT method lies in its adaptability. You are not limited to extracting text before the word “our”; the formula can be modified to trigger based on any character, word, or symbol. This is particularly useful when dealing with CSV (Comma Separated Values) data, email addresses, or URLs where specific symbols like commas, “at” symbols (@), or slashes (/) serve as the primary separators.
For instance, if your goal is to extract all text before the word “is” (including a trailing space), you would simply adjust the pattern within the quotes. The formula would be updated as follows:
=REGEXEXTRACT(A2,"(.*)is .*")
In this variation, the inclusion of the space after “is” ensures that the function looks for the word “is” as a distinct unit, rather than just the characters ‘i’ and ‘s’ appearing within another word (like “this” or “island”). This level of granularity is what makes regex superior to basic text functions. It allows the user to define the context of the delimiter with extreme accuracy, reducing the risk of false matches.

When you apply this revised formula, Column B will update to reflect the new extraction logic. This flexibility is essential when working with multifaceted datasets where different rows might require different extraction rules. By simply altering the string within the capturing group context, you can pivot your entire data processing strategy in seconds.
It is important to note that certain characters in regex are considered “special characters” or “metacharacters” (such as . * + ? ^ $ [ ] ( ) { } | ). If you wish to extract text before one of these specific symbols, you must “escape” the character by preceding it with a backslash (). For example, to extract text before a question mark, you would use (.*)?.* as your pattern. This ensures that Google Sheets treats the symbol as a literal character rather than a functional piece of regex code.
Best Practices for Regular Expressions in Google Sheets
While REGEXEXTRACT is exceptionally powerful, using it effectively requires adherence to certain best practices to ensure data integrity and spreadsheet performance. One of the most important considerations is case sensitivity. By default, regex in Google Sheets is case-sensitive. This means that a pattern looking for “our” will not match “OUR” or “Our”. To make your formula case-insensitive, you can wrap your pattern in the (?i) flag, such as "(?i)(.*)our.*", which instructs the engine to ignore capitalization.
Another best practice involves the use of ArrayFormula. If you are working with a very large dataset, dragging a formula down thousands of rows can occasionally lead to performance lag. Instead, you can combine REGEXEXTRACT with ARRAYFORMULA to process an entire column with a single entry in the top cell. This simplifies spreadsheet maintenance and ensures that any new rows added to the sheet are automatically processed without further manual intervention.
Data validation is also a critical step when using regex. Because REGEXEXTRACT will return an #N/A error if the pattern is not found in the source text, it is often wise to wrap your formula in an IFERROR function. For example, =IFERROR(REGEXEXTRACT(A2, "(.*)our.*"), A2) would return the original text if the delimiter “our” is missing, rather than displaying an ugly error code. This keeps your data visualization clean and professional.
Finally, always keep a “cheat sheet” or reference guide for regular expression syntax. Since the rules for regex are standardized across many programming languages, any high-quality resource on the subject will be applicable to Google Sheets. Testing your patterns in a dedicated regex tester before implementing them in your spreadsheet can also save significant time and prevent logical errors in your data analysis.
Troubleshooting and Common Challenges
Even for experienced users, regex can occasionally behave in unexpected ways. One common issue is greedy matching. By default, the .* pattern is “greedy,” meaning it will match as much text as possible. If your cell contains the delimiter “our” multiple times, a greedy match might capture everything up until the last instance of the word. If you need to extract text before the first instance, you must use a “lazy” quantifier by adding a question mark: (.*?)our.*. This tells the engine to stop at the first possible match.
Another frequent challenge arises from hidden characters, such as non-breaking spaces or line breaks, which may exist in imported data. These characters can prevent a regex pattern from finding a match even if the text looks correct to the naked eye. In such cases, using the TRIM or CLEAN functions on your source data before applying REGEXEXTRACT can resolve the issue by removing non-printable characters and excess whitespace.
Errors can also occur if the syntax of the regular expression is slightly off. Common mistakes include mismatched parentheses, unescaped special characters, or incorrect placement of the wildcards. If your formula is returning an error, double-check that every opening parenthesis has a corresponding closing one and that your strings are properly enclosed in quotation marks. Google Sheets provides helpful hover-over tooltips that can often point you toward the specific part of the formula that is causing the breakdown.
Lastly, consider the computational overhead. While Google Sheets is robust, extremely complex regex patterns applied to tens of thousands of rows can slow down the recalculation speed of your workbook. If you notice a significant lag, consider “freezing” your data by copying the results of your formulas and using Paste Special > Values only. This replaces the dynamic formulas with static text, which is much easier for the spreadsheet engine to handle once the initial data cleaning is complete.
Enhancing Your Workflow with Related Techniques
The ability to extract text before a character is just one component of a comprehensive data management strategy. To become truly proficient in Google Sheets, it is beneficial to explore related functions and tutorials that expand on these concepts. Often, the most effective solution involves a combination of different techniques tailored to the specific structure of your dataset.
For those who find regex a bit too complex for simpler tasks, exploring the LEFT, RIGHT, MID, FIND, and SEARCH functions is a logical next step. These functions are easier to read and maintain for basic extractions where the delimiter is a single, consistent character. However, as your data becomes more “noisy” and unpredictable, you will likely find yourself returning to the power and flexibility of REGEXEXTRACT.
To further your skills, consider studying the following areas of spreadsheet automation:
- Advanced Pattern Matching: Learning how to extract numbers, dates, or specific formatted codes (like SKUs) using regex character classes like
dfor digits orwfor word characters. - Data Splitting: Using the SPLIT function to break a cell into multiple columns based on a delimiter, which can sometimes be faster than individual extractions.
- Text Joining: Mastering TEXTJOIN and CONCATENATE to reassemble your extracted data into new, more useful formats.
- Scripting: Exploring Google Apps Script for custom functions that can perform text manipulations beyond what is possible with standard formulas.
By building a diverse toolkit of text manipulation techniques, you ensure that you can handle any data challenge that comes your way. Whether you are a data scientist, a marketer, or a project manager, these skills will significantly increase your efficiency and the quality of your insights. For more detailed guides on similar topics, you may find the following tutorial helpful:
Cite this article
stats writer (2026). How to Extract Text Before a Character in Google Sheets Using LEFT. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-i-extract-text-before-a-specific-character-in-google-sheets/
stats writer. "How to Extract Text Before a Character in Google Sheets Using LEFT." PSYCHOLOGICAL SCALES, 18 Feb. 2026, https://scales.arabpsychology.com/stats/how-do-i-extract-text-before-a-specific-character-in-google-sheets/.
stats writer. "How to Extract Text Before a Character in Google Sheets Using LEFT." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-do-i-extract-text-before-a-specific-character-in-google-sheets/.
stats writer (2026) 'How to Extract Text Before a Character in Google Sheets Using LEFT', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-i-extract-text-before-a-specific-character-in-google-sheets/.
[1] stats writer, "How to Extract Text Before a Character in Google Sheets Using LEFT," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Extract Text Before a Character in Google Sheets Using LEFT. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.