Table of Contents
Creating a crosstab, short for cross-tabulation, is a fundamental analytical technique employed in statistical software environments. In SPSS (Statistical Package for the Social Sciences), this process is initiated through the Analyze tab, followed by selecting the Crosstabs option. This function is absolutely essential for researchers aiming to quantify and visualize the relationship and distribution between two or more variables within a structured dataset.
The core utility of the crosstab feature lies in its ability to synthesize large amounts of data into an easily digestible format, displaying the joint frequencies of different variable values. Upon selecting the desired variables for analysis, SPSS rapidly generates a clear, concise contingency table that elegantly displays the observed relationship. Furthermore, users are granted significant control over the output customization, including the capability to add supplementary inferential statistics (such as Chi-square or cell percentages), rearrange the configuration of rows and columns for optimal visual interpretation, and apply specific filters to narrow the analytical focus.
This powerful feature is predominantly used for rigorous statistical analysis involving two or more categorical variables. For example, a researcher might use a crosstab to analyze the dependency between employee job satisfaction (a categorical variable) and work location (another categorical variable). Understanding how to efficiently generate, interpret, and customize these tables is an indispensable skill for generating precise, meaningful insights from complex quantitative research data.
Understanding and Generating Crosstabs in SPSS
Defining Cross-Tabulation in Statistical Analysis
A crosstab, often referred to as a contingency table, functions as a highly specialized summary table in statistical methodology. Its primary purpose is to summarize and analyze the relationship between two discrete variables, which are typically measured at the nominal or ordinal level of measurement. This analytical technique is invaluable for identifying underlying patterns, dependencies, and connections within your compiled research data, forming the basis for exploratory data analysis.
In the SPSS statistical environment, the straightforward procedure for generating this table involves navigating through the main menu structure: select Analyze, then proceed to Descriptive Statistics, and finally click on Crosstabs. Following this structured pathway ensures that the resulting output is correctly formatted and aligned with expected standards for robust statistical interpretation.
To provide clarity and demonstrate the practical application of this functionality, the following detailed sections will walk through a precise, step-by-step example. This approach moves from data visualization to procedure execution and, finally, to output interpretation, covering every stage necessary for successful cross-tabulation.
Example: Setting Up the Analysis for Player Data
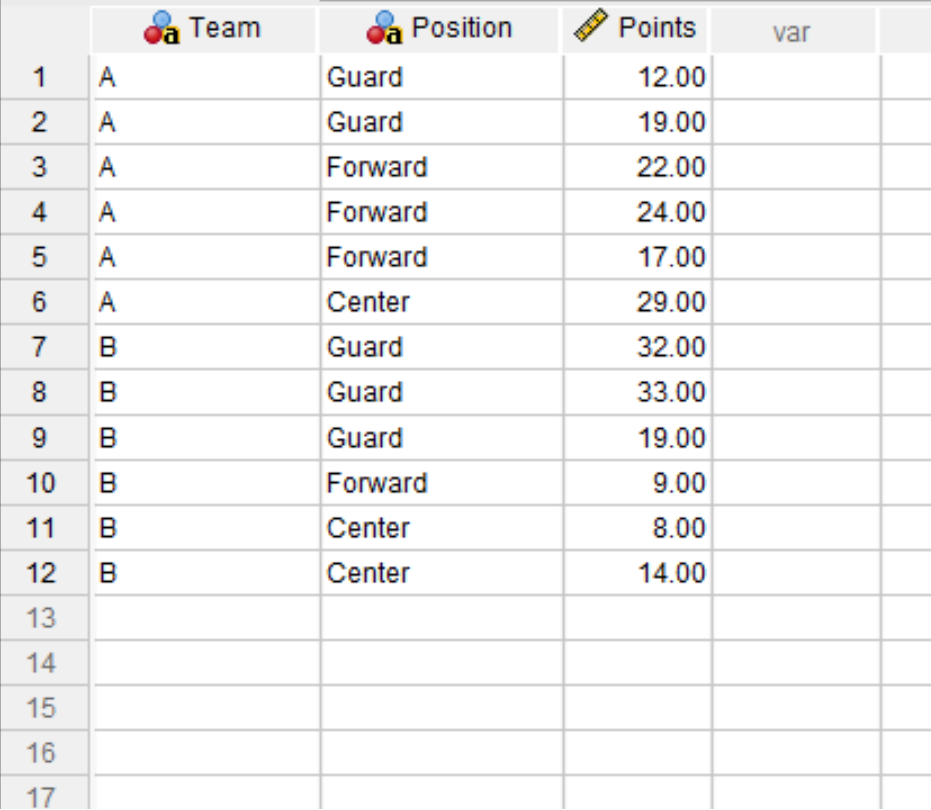
For this demonstration, let us assume we are analyzing a comprehensive dataset residing in SPSS that contains pertinent information regarding various professional basketball players. Crucially, this dataset includes two key categorical variables: the player’s assigned Team (A or B) and their specific court Position (Center, Forward, or Guard).
The input data, which serves as the foundation for our impending cross-tabulation analysis, is presented visually below. We aim to use the ‘Team’ and ‘Position’ variables to systematically explore the joint frequency distribution of these two characteristics.

Our primary analytical objective is to successfully generate a crosstab that succinctly summarizes the frequency of each unique combination of Team membership and Position role. Achieving this allows us to rapidly quantify the internal composition of each team in relation to the roles filled by their players.
Step 1: Initiating the Crosstabs Procedure in SPSS
The first technical step requires accessing the specific statistical procedure within the SPSS environment. Locate and click the Analyze tab, which is strategically positioned in the main menu bar. This tab acts as the gateway to virtually all primary statistical and analytical tools available in the software.
From the resulting drop-down menu, position the cursor over the Descriptive Statistics submenu, and then execute the command by clicking on the Crosstabs option. This action immediately launches the main dialog box, which is used for assigning variables to the row and column structure of the prospective table.
To ensure accuracy in navigation, the required sequence of menu selections is visually confirmed in the following illustrative image:

Step 2: Assigning Variables to the Table Structure
Upon the appearance of the Crosstabs dialog window, the user must precisely define which selected variables will define the table’s rows and which will define its columns. This assignment choice directly influences how the resulting table is viewed and, critically, how it is subsequently interpreted by the analyst.
In adherence to our stated objective, we must drag the Team variable and place it into the designated Rows panel. Following this, we drag the Position variable and assign it to the Columns panel. This specific configuration establishes that the categories defined by the ‘Team’ variable will form the major horizontal axis, while the ‘Position’ categories will constitute the vertical axis.
Verifying that the variables are correctly positioned within the Crosstabs dialog box is an essential procedural check before moving forward to generate the analytical output:

Step 3: Executing the Command and Reviewing Initial Output
After all variables have been correctly assigned to their respective roles (Rows and Columns), clicking the OK button executes the statistical procedure. SPSS immediately generates the results, which are presented in the Output Viewer window. This output typically consists of a minimum of two tables providing different analytical perspectives.
The structure of the generated cross-tabulation, which forms the primary result of the procedure, is shown here:

The first table produced is the Case Processing Summary. This summary provides vital metadata regarding the sample size and data integrity used in the calculation. It clearly details the total count of valid observations (cases included in the analysis) and the count of missing observations (cases that were excluded due to incomplete data for either the Team or Position variable).
For our specific player analysis, the summary confirms the presence of 12 total valid observations and exactly 0 missing observations (or “cases”). The absence of missing data confirms that every data point in the initial dataset was successfully incorporated into the frequency calculation, which assures maximum reliability for the subsequent table.
Interpreting the Core Crosstabulation Table
The second and most crucial output table, titled Team * Position Crosstabulation, displays the joint frequency distribution of our two key variables: Team (as rows) and Position (as columns). A complete interpretation requires a careful examination of the marginal frequencies, which include the row totals and column totals, in addition to the individual cell frequencies.
By focusing initially on the marginal frequencies corresponding to the rows, we can draw specific conclusions about the overall player distribution across the teams:
- The row total for Team A confirms that a total of 6 players are active members of team A.
- The row total for Team B confirms that a total of 6 players are active members of team B.
- The bottom right grand total confirms the overall sample size of 12 valid cases utilized in the crosstab.
Analyzing Marginal and Joint Frequencies
Moving beyond the row totals, analyzing the column totals provides essential insight into the overall distribution of player positions across the entire pool of athletes, irrespective of their specific team assignment. This offers a valuable macro-level overview of the professional roles represented in the dataset.
Overall Position Distribution (Column Totals):
- A collective total of 3 players occupy the specific position of Center when both teams are aggregated.
- A collective total of 4 players are designated as Forwards across the entire dataset.
- A collective total of 5 players are designated as Guards across the entire dataset.
The most detailed level of insight is derived from examining the individual cell frequencies. Each cell represents the precise intersection of one row category (Team) and one column category (Position). These frequencies reveal the exact count of players of a certain position who belong to a specific team, thereby providing the strongest empirical evidence of the relationship between the two categorical variables.
Detailed Joint Frequencies (Individual Cells):
- Specifically, 1 player who is a Center is affiliated with team A.
- 3 players who are Forwards are affiliated with team A.
- 2 players who are Guards are affiliated with team A.
- 2 players who are Centers are affiliated with team B.
- 1 player who is a Forward is affiliated with team B.
- 3 players who are Guards are affiliated with team B.
Conclusion and Advanced Analytical Applications
By successfully creating and systematically interpreting this single cross-tabulation table, researchers gain a profound and quantifiable understanding of the frequency distribution for every combination of Team and Position within the basketball player dataset. This simple yet powerful descriptive procedure serves as the fundamental building block for significantly more advanced statistical investigations, such as calculating expected frequencies, computing various measures of association (e.g., Cramer’s V), or performing chi-square tests to formally assess independence between the variables.
The proficient ability to perform and interpret cross-tabulation in SPSS is an absolutely essential competency for anyone engaged in serious quantitative research involving the relationship between categorical variables.
Related SPSS Tutorials for Enhanced Proficiency
To further refine and enhance your operational proficiency in statistical analysis using the SPSS software, the following supplementary resources explain how to execute other common and necessary analytical tasks:
Cite this article
stats writer (2026). How to Create a Crosstab Table in SPSS: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-you-create-a-crosstab-in-spss/
stats writer. "How to Create a Crosstab Table in SPSS: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 23 Jan. 2026, https://scales.arabpsychology.com/stats/how-do-you-create-a-crosstab-in-spss/.
stats writer. "How to Create a Crosstab Table in SPSS: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-do-you-create-a-crosstab-in-spss/.
stats writer (2026) 'How to Create a Crosstab Table in SPSS: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-you-create-a-crosstab-in-spss/.
[1] stats writer, "How to Create a Crosstab Table in SPSS: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, January, 2026.
stats writer. How to Create a Crosstab Table in SPSS: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.