Table of Contents
Understanding Residuals and Their Significance
In the realm of statistical modeling, particularly linear regression, understanding the discrepancy between the actual data points and the values predicted by the model is paramount. This discrepancy is known as a residual. Formally, a residual is the difference between the observed value of the dependent variable and the value predicted by the regression line. Analyzing these residuals is crucial because they provide insight into how well the chosen model fits the underlying data structure.
While standard residuals are useful for general diagnostics, they lack standardization, making it difficult to compare their magnitudes across different data points or models, especially if the variance of the errors is not constant (a condition known as heteroscedasticity). Therefore, statisticians often turn to standardized or, even better, studentized versions of these metrics. By normalizing residuals, we can establish universal benchmarks for identifying problematic data points that might unduly influence the model’s parameters.
The calculation of residuals is an intrinsic part of fitting any statistical model in R. When a model is fitted, the software computes a residual for every single data point used in the training process. These raw residuals are simply the vertical distances from the data points to the fitted regression line. However, the interpretation of a raw residual is limited because it doesn’t account for the inherent variability of the estimates, particularly the leverage of the specific observation involved. This is where studentized metrics become essential tools for rigorous model diagnostics.
Defining the Studentized Residual
A studentized residual is a refined version of the standard residual, calculated by dividing the residual by its estimated standard deviation. Unlike standardized residuals, which use a single estimate for the standard deviation of all errors, studentized residuals are more robust as they use an estimate of the error variance based on a model fitted without the corresponding observation itself. This “leave-one-out” approach makes the studentized residual a more accurate measure of the extent to which a specific data point is an outlier relative to the rest of the dataset.
The primary advantage of using studentized residuals lies in their utility for identifying influential data points and outliers. Because these values are standardized and adjusted for varying error variances across the predictor space, they often follow a known distribution (a t-distribution with specific degrees of freedom), which facilitates hypothesis testing and establishing clear thresholds. The common practice in statistical analysis dictates that any observation yielding a studentized residual with an absolute value greater than 3 is typically flagged as a potential outlier requiring further investigation. This threshold serves as a powerful rule of thumb for initial data scrutiny.
Understanding the distinction between residual types is crucial for effective model critique. While raw residuals tell you the magnitude of the error, standardized residuals normalize this error using the overall error variance. Studentized residuals, conversely, incorporate the leverage of the point and calculate the error variance specifically excluding that point, providing the most robust measure of how unusual that observation is compared to the model built on the remaining data. Therefore, whenever searching for influential points or verifying assumptions like normality and homoscedasticity, the studentized residual is often the preferred metric.
The Role of the MASS Package in R
To efficiently calculate studentized residuals in R, we utilize the powerful capabilities provided by the Modern Applied Statistics with S (MASS) package. This package, co-authored by statistical giants W.N. Venables and B.D. Ripley, is fundamental to many advanced statistical procedures in R. It provides the specific function, studres(), designed to compute these diagnostics directly from a fitted regression model object.
The syntax for applying this function is remarkably straightforward, emphasizing R’s commitment to simplicity in complex analysis. The function requires only one argument: the fitted model object. The general syntax is: studres(model), where model is any object representing a fitted linear model (typically created using the lm() function). Once executed, the function returns a vector of studentized residual values, one corresponding to each observation used in the model fitting process.
Before using this crucial diagnostic function, users must ensure the MASS package is loaded into the current R session. If the package is not already installed, it must be acquired from CRAN (Comprehensive R Archive Network). The ease with which complex diagnostics like studentized residuals are obtained underscores why R remains the dominant environment for statistical computing, providing ready access to sophisticated tools necessary for comprehensive model validation.
Setting Up the Linear Regression Model in R
To provide a concrete example, we will employ the built-in R dataset mtcars, which contains data on 32 automobiles. Our goal is to model the relationship between a car’s fuel efficiency, measured in miles per gallon (mpg), and its engine displacement (disp). This foundational step requires fitting a simple linear regression model before we can proceed to calculate the diagnostics needed to check for potential outliers.
The code block below demonstrates the necessary R commands to define and fit this initial model. We use the standard lm() function, specifying mpg as the dependent variable and disp as the independent (predictor) variable, using the mtcars dataset. This creates the primary model object, which serves as the input for calculating the studentized residuals later on. This model fitting process estimates the parameters (intercept and slope) that define the line of best fit through the data points.
#build simple linear regression model
model <- lm(mpg ~ disp, data=mtcars)
It is crucial to verify that the model has been correctly specified and fitted before moving on to residual analysis. While this simple example is straightforward, in real-world scenarios involving multiple predictors or complex data structures, ensuring model validity through initial checks is a necessary precursor to advanced diagnostic analysis. Once the model object is successfully generated, it contains all the information—including the raw residuals—needed by the studres() function to derive the studentized values.
Executing the Studentized Residual Calculation
With the linear model successfully fitted, the next logical step is to calculate the studentized residuals for every observation. This is achieved by first loading the necessary library and then invoking the studres() function on our fitted model object. This process immediately transforms the raw prediction errors into standardized, leverage-adjusted metrics, making them directly comparable across the dataset.
The R code snippet below illustrates this process. We first use the library(MASS) command to load the MASS package, granting access to the required function. We then assign the resulting vector of studentized residuals to a new variable, stud_resids. Viewing the head of this new vector confirms the calculation has been executed, providing the first few studentized residual values associated with the initial vehicles in the mtcars dataset.
library(MASS) #calculate studentized residuals stud_resids <- studres(model) #view first three studentized residuals head(stud_resids, 3) Mazda RX4 Mazda RX4 Wag Datsun 710 -0.6236250 -0.6236250 -0.7405315
The output shows the individual studentized residual values for the first three observations. These numerical values themselves indicate the degree of deviation, standardized by the error variance adjusted for the observation’s leverage. Values close to zero suggest the model predicts the outcome well for that specific point, while magnitudes approaching or exceeding the absolute value of 3 signal potential outliers that warrant careful attention during the diagnostic phase of the statistical analysis.
Visualizing Studentized Residuals for Outlier Detection
While numerical inspection is helpful, visualizing the relationship between the predictor variable and the studentized residuals provides a far more intuitive and effective way to identify patterns, check for model assumptions, and quickly spot potential outliers. A standard residual plot graphs the studentized residuals against the fitted values or, in the case of a simple regression, against the predictor variable itself.
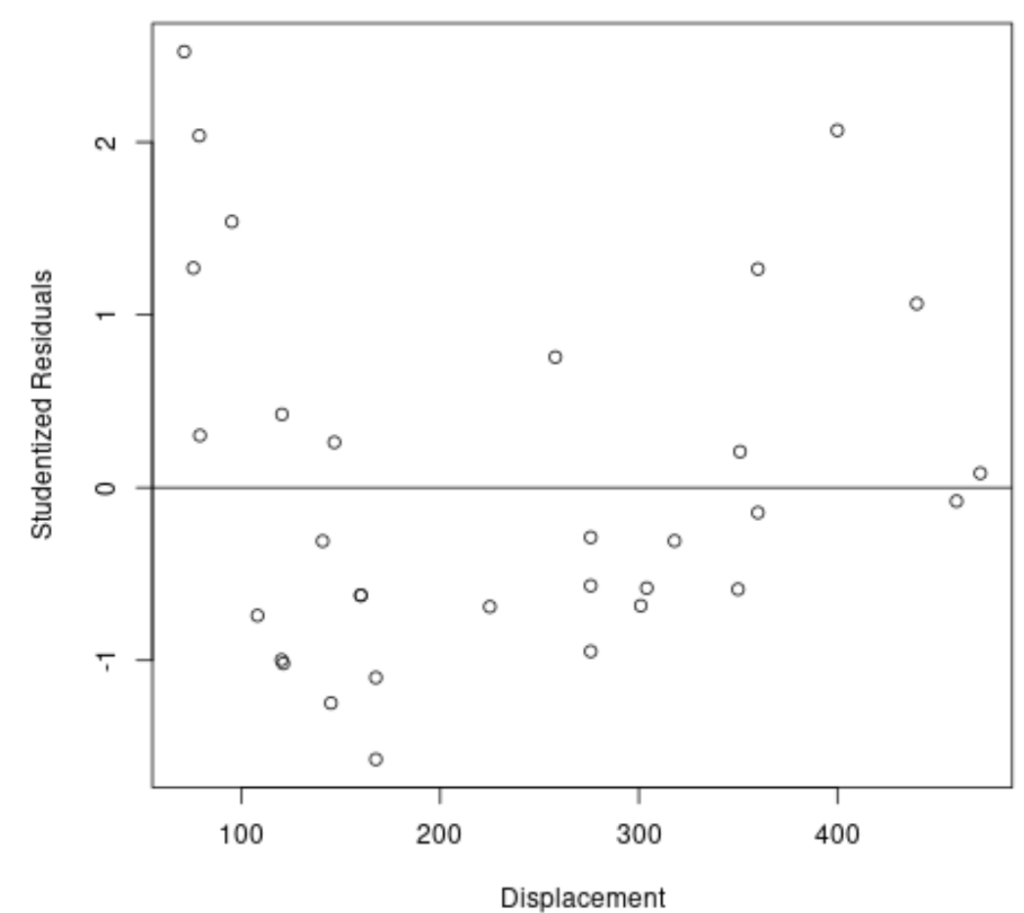
The following code block generates a scatter plot using the disp (displacement) values on the x-axis and the newly calculated stud_resids on the y-axis. By adding a horizontal line at y=0 using abline(0, 0), we establish a clear baseline. Points lying far from this zero line represent observations where the actual value deviates significantly from the model’s prediction.
#plot predictor variable vs. studentized residuals plot(mtcars$disp, stud_resids, ylab='Studentized Residuals', xlab='Displacement') #add horizontal line at 0 abline(0, 0)
The resulting plot, as seen below, allows for immediate visual assessment of the residual distribution. When examining this plot, we are specifically looking for any points that fall outside the critical zone defined by the absolute value of 3. If any point were found above +3 or below -3 on the y-axis, it would strongly suggest that the corresponding data point is an outlier that might be biasing the estimates of our linear model. In this specific example, the visual inspection confirms that all points lie comfortably within the acceptable range, indicating no clear outliers are present based on this metric.

Integrating Results: Adding Residuals to the Dataset
For ongoing data analysis, it is often practical and necessary to merge the calculated diagnostic metrics, such as the studentized residual values, back into the original dataset. This integration allows analysts to directly inspect the characteristics of the individual data points that exhibit the highest or lowest residual values, facilitating deeper investigation into specific observations.
The process of merging is straightforward in R using the cbind() function, which binds columns together. We create a new dataframe, final_data, containing the key variables from the original mtcars dataset (mpg and disp) alongside the calculated stud_resids vector. Because the residuals vector retains the observation names (the row names of the mtcars dataset), the merging operation is seamless and preserves the integrity of the data structure.
#add studentized residuals to orignal dataset final_data <- cbind(mtcars[c('mpg', 'disp')], stud_resids) #view final dataset head(final_data) mpg disp stud_resids Mazda RX4 21.0 160 -0.6236250 Mazda RX4 Wag 21.0 160 -0.6236250 Datsun 710 22.8 108 -0.7405315 Hornet 4 Drive 21.4 258 0.7556078 Hornet Sportabout 18.7 360 1.2658336 Valiant 18.1 225 -0.6896297
By viewing the output of the head(final_data) command, we confirm that each vehicle now has its corresponding fuel efficiency, engine displacement, and the diagnostic studentized residual neatly aligned. This integrated dataframe is the foundational material for the next step: systematically identifying the observations that are statistically most extreme and therefore most deserving of detailed scrutiny.
Identifying Potential Influential Observations
Even if no clear outliers (values > |3|) are identified through plotting, it is highly informative to identify which observations are closest to this threshold. These observations, while not strictly classified as outliers, exert the most leverage or represent the largest standardized deviations, thus indicating points where the model performs the poorest relative to the general trend.
To pinpoint these potentially influential data points, we can sort the complete dataset based on the magnitude of the studentized residual in descending order. This brings the observations with the largest positive residuals (the most underpredicted points) to the top of the list, followed by the largest negative residuals (the most overpredicted points) towards the bottom.
The use of the R function order(-stud_resids) achieves this descending sort efficiently. By examining the sorted list, analysts can quickly identify the specific vehicle models that deviate most significantly from the relationship established by the regression equation, enabling targeted qualitative analysis of these particular data points to determine if they represent measurement errors, unique characteristics, or simply natural statistical variation.
#sort studentized residuals descending final_data[order(-stud_resids),] mpg disp stud_resids Toyota Corolla 33.9 71.1 2.52397102 Pontiac Firebird 19.2 400.0 2.06825391 Fiat 128 32.4 78.7 2.03684699 Lotus Europa 30.4 95.1 1.53905536 Honda Civic 30.4 75.7 1.27099586 Hornet Sportabout 18.7 360.0 1.26583364 Chrysler Imperial 14.7 440.0 1.06486066 Hornet 4 Drive 21.4 258.0 0.75560776 Porsche 914-2 26.0 120.3 0.42424678 Fiat X1-9 27.3 79.0 0.30183728 Merc 240D 24.4 146.7 0.26235893 Ford Pantera L 15.8 351.0 0.20825609 Cadillac Fleetwood 10.4 472.0 0.08338531 Lincoln Continental 10.4 460.0 -0.07863385 Duster 360 14.3 360.0 -0.14476167 Merc 450SL 17.3 275.8 -0.28759769 Dodge Challenger 15.5 318.0 -0.30826585 Merc 230 22.8 140.8 -0.30945955 Merc 450SE 16.4 275.8 -0.56742476 AMC Javelin 15.2 304.0 -0.58138205 Camaro Z28 13.3 350.0 -0.58848471 Mazda RX4 Wag 21.0 160.0 -0.62362497 Mazda RX4 21.0 160.0 -0.62362497 Maserati Bora 15.0 301.0 -0.68315010 Valiant 18.1 225.0 -0.68962974 Datsun 710 22.8 108.0 -0.74053152 Merc 450SLC 15.2 275.8 -0.94814699 Toyota Corona 21.5 120.1 -0.99751166 Volvo 142E 21.4 121.0 -1.01790487 Merc 280 19.2 167.6 -1.09979261 Ferrari Dino 19.7 145.0 -1.24732999 Merc 280C 17.8 167.6 -1.57258064
From the sorted output, we clearly see that the “Toyota Corolla” has the highest studentized residual (2.52), indicating it is the most underpredicted observation in the dataset relative to the fitted model. While this value is below the critical threshold of 3, its proximity suggests it is the most extreme data point in terms of model fit, perhaps due to its unusually high fuel efficiency relative to its small displacement.
Conclusion and Further Reading
The process of calculating and interpreting studentized residuals is an indispensable component of rigorous regression diagnostics. By leveraging the MASS package in R, we can quickly transform raw prediction errors into robust, standardized metrics that accurately reflect the extremity of each observation relative to the overall model structure. This standardization is critical for detecting influential data points or outliers that could otherwise distort the interpretation of regression coefficients and compromise the validity of statistical inferences.
The ability to integrate these residuals back into the original dataset and sort the resulting values provides a powerful, systematic method for pinpointing observations that require qualitative scrutiny. Whether confirming the absence of severe outliers or identifying specific cases for further investigation, the use of studentized residuals ensures that the statistical model is robust and that any conclusions drawn are based on a sound understanding of the data’s relationship to the fitted regression line.
Mastering these diagnostic techniques is foundational for anyone performing advanced statistical analysis in R. For those interested in expanding their knowledge of regression analysis and other critical diagnostic tools, the following related resources provide excellent pathways for continued learning:
How to Perform Simple Linear Regression in R
How to Perform Multiple Linear Regression in R
How to Create a Residual Plot in R
Cite this article
stats writer (2025). How can I calculate Studentized Residuals in R?. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-calculate-studentized-residuals-in-r/
stats writer. "How can I calculate Studentized Residuals in R?." PSYCHOLOGICAL SCALES, 17 Dec. 2025, https://scales.arabpsychology.com/stats/how-can-i-calculate-studentized-residuals-in-r/.
stats writer. "How can I calculate Studentized Residuals in R?." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-can-i-calculate-studentized-residuals-in-r/.
stats writer (2025) 'How can I calculate Studentized Residuals in R?', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-calculate-studentized-residuals-in-r/.
[1] stats writer, "How can I calculate Studentized Residuals in R?," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How can I calculate Studentized Residuals in R?. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.