Table of Contents
Understanding how to effectively visualize quantitative data is paramount in statistical analysis and reporting. Among the various tools available to statisticians and researchers, the dot plot and the histogram stand out as foundational graphical representations, particularly useful for illustrating the shape and distribution of values within a dataset. While both charts serve the core purpose of visualizing frequency, they employ distinct methodologies and yield different levels of granular detail, making the choice between them dependent on the specific context and size of the data being analyzed.
The fundamental distinction lies in how the horizontal axis is utilized. A dot plot maps every single observation onto a number line, offering a direct visual count of the frequency of individual values. Conversely, a histogram aggregates observations into predefined intervals, known as bins or classes, and uses the height of rectangular bars to show the combined frequency of data points falling within those ranges. This difference in grouping mechanism impacts everything from the chart’s appearance to the specific insights that can be derived from it, especially when dealing with variables that are continuous or highly varied.
This article will delve into the specific characteristics, construction methods, and appropriate applications for both the dot plot and the histogram, providing a detailed comparison to help analysts select the most suitable visualization technique. We will begin by defining the structural components of each plot, followed by a practical example using a shared dataset to highlight their visual differences, ensuring clarity on when each method excels.
Two plots that are commonly used to visualize the distribution of values in a dataset are dot plots and histograms.
A dot plot displays individual data values along the x-axis and uses dots to represent the frequencies of each individual value.
A histogram displays data ranges along the x-axis and uses rectangular bars to represent the frequencies of values that fall into each range.
The following example shows how to create a dot plot and histogram for the same dataset.
Defining the Dot Plot: Individual Data Representation
The dot plot is perhaps the simplest yet most powerful graphical representation for visualizing small to moderately sized quantitative datasets. It functions primarily as a frequency counting mechanism where each observation is represented by a distinct circular marker, or dot. These dots are stacked vertically above a horizontal axis that represents the scale of the quantitative variable under examination. This stacking ensures that the height of the column of dots directly corresponds to the statistical frequency of that specific numerical value.
A key structural characteristic of the dot plot is its commitment to displaying every individual observation. Unlike other summary charts, the dot plot does not group values; if the value ‘5’ appears seven times in the dataset, there will be exactly seven dots stacked above the number 5 on the x-axis. This transparency is invaluable when the analyst requires absolute certainty regarding the occurrence count of specific measurements. Furthermore, because the data values are clearly marked on the axis, the analyst can easily identify the minimum and maximum values, clusterings of data (modes), and any unusual or outlier values that might warrant further investigation.
Dot plots are particularly effective when the dataset contains discrete or integer values, or when the sample size is small enough that grouping the data would obscure important patterns. They provide a clear visual indication of the shape of the distribution—whether it is symmetrical, skewed, or multimodal—without the need for complex aggregation or binning decisions. The visual simplicity makes them highly accessible for communicating basic statistical findings, often serving as a preliminary step before moving to more complex visualizations for continuous variables or significantly larger samples.
Defining the Histogram: Frequency Distribution through Bins
In contrast to the granular nature of the dot plot, the histogram is a robust visualization technique specifically designed for displaying the frequency distribution of continuous numerical data or when dealing with extremely large datasets. The histogram utilizes adjacent rectangular bars, where the area of the bar is proportional to the frequency of the observations falling within a specified numerical range. This range is known as a bin or class interval, and the definition of these bins is critical to how the resulting visualization appears.
The construction of a successful histogram hinges on the appropriate selection of bin width. If the bins are too wide, much of the detail regarding the shape of the distribution can be lost, potentially masking important peaks or gaps in the data. Conversely, if the bins are too narrow, the histogram might resemble a noisy, ragged landscape, making it difficult to discern the general pattern or underlying structure. Unlike a typical bar chart, the bars in a histogram must touch, symbolizing that the data is continuous and that the bins cover the entire range of values without gaps, except where no observations fall within a specific interval.
The primary advantage of the histogram is its ability to summarize massive amounts of data efficiently, providing a high-level view of the distribution’s central tendency, spread, and shape. It is indispensable in fields like quality control, population statistics, and environmental science where continuous measurements are common. While the histogram sacrifices the ability to identify the precise value of individual observations—as all data points within a bin are treated equally—it excels at revealing the overall statistical profile of the entire sample, making it easier to compare distributions across different groups or time periods.
Key Structural Differences: Granularity, Axes, and Interpretation
The fundamental operational differences between the dot plot and the histogram stem from their approach to data representation along the horizontal axis. In a dot plot, the x-axis is an unbroken number line where every integer or specific measured value is individually represented. This preserves the original numerical structure of the dataset entirely, allowing analysts to count points corresponding to specific values such as 4, 5, or 6. The y-axis implicitly represents the count or frequency, indicated by the vertical stacking of the dots.
The histogram, conversely, segments the continuous range of data into discrete buckets or bins on the x-axis. For example, instead of showing the count of ‘4’ and the count of ‘5’ separately, a histogram might show the count for the range ‘4 to 6’. This aggregation is necessary for larger, continuous datasets where hundreds or thousands of unique values might exist, making a dot plot impractical. The y-axis in a histogram is explicitly labeled and calibrated to show the frequency (or relative frequency) associated with each bar, providing a clear magnitude scale for the bin counts.
This structural divergence has significant consequences for interpretation. The dot plot maintains data integrity, allowing for precise measurement of central tendencies and exact frequency counts for individual scores. However, the histogram, by aggregating values, smooths out the distribution, which is advantageous for visualizing the shape of a large, continuous population distribution. While the histogram is superior for visualizing shape and spread in high-volume scenarios, the dot plot is the superior choice for small-scale analysis where preserving the identity and count of every single score is a priority.
Practical Example: Creating a Dot Plot & Histogram for the Same Dataset
To fully appreciate the conceptual and visual differences between these two statistical charts, let us apply both the dot plot and the histogram to an identical, small dataset. Suppose a researcher has collected the following eighteen numerical values representing scores on a short quiz or response times in an experiment. Analyzing these values using two different visualization techniques will clearly demonstrate the impact of binning versus individual value representation.
We begin with the raw observations collected in our study. This dataset contains 18 values, ranging from 1 to 10:
Data: 1, 1, 1, 1, 2, 2, 2, 3, 4, 5, 5, 6, 6, 6, 6, 7, 8, 10
First, we will examine how this data is rendered using the dot plot method, which requires plotting each of the 18 instances directly above its corresponding value on the numerical scale. Subsequently, we will generate the histogram, which necessitates grouping these 18 values into defined ranges, thereby altering the visual representation of their underlying distribution.
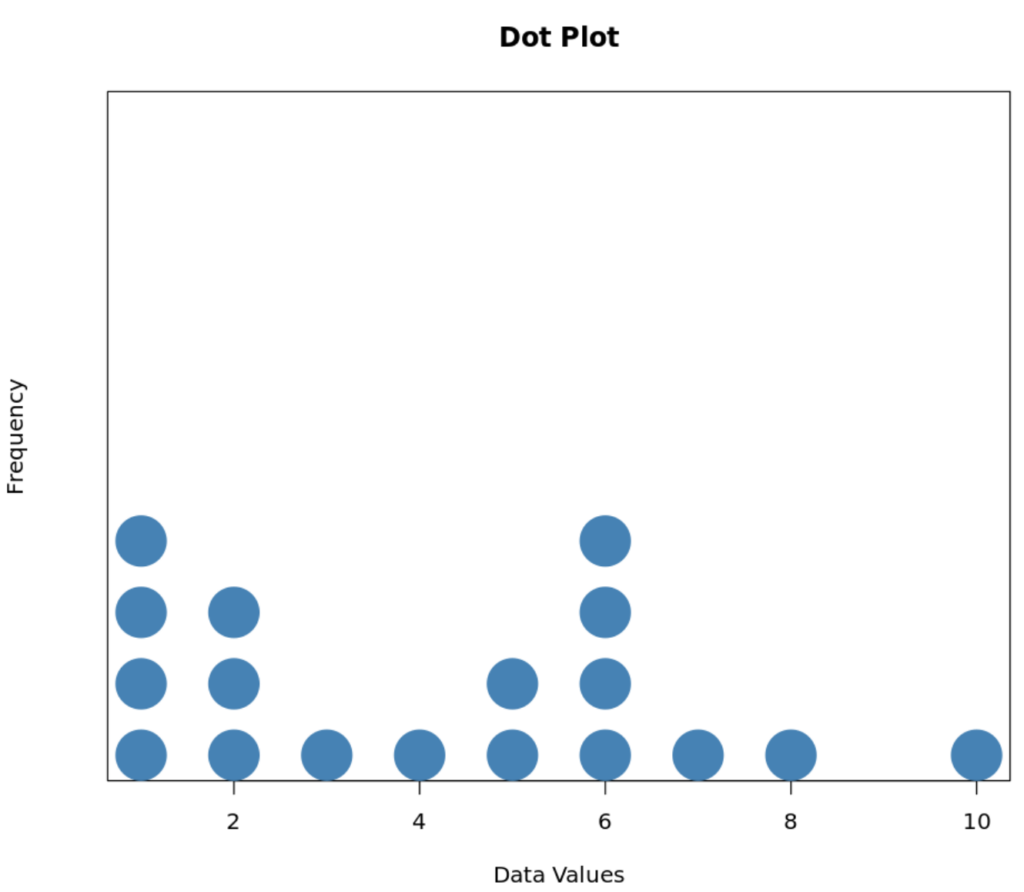
Analyzing the Dot Plot Visualization
When the provided dataset is translated into a dot plot, the resulting graphic offers an immediate, precise view of the frequency of every unique score. Below is the visual output of the dot plot, which clearly maps the 18 data points along the horizontal axis, labeled “Data Values,” while the vertical stacking implicitly shows the frequency count.

Upon careful inspection of this visualization, several key insights become instantly clear. The x-axis shows the individual data values and the y-axis shows the frequency of each value. For instance, we can unequivocally state that the value of “1” occurred four times because there are four stacked dots above it. Similarly, the value “2” appears three times, while the value “3” occurs just once, indicating a specific measurement frequency for each integer score within the sample.
The dot plot immediately reveals the density and clustering of the data. We observe significant concentration around the lower end of the scale (values 1 and 2), with another cluster around value 6. The plot also clearly identifies specific gaps where no data was recorded (e.g., value 9) and highlights the single observation at value 10. This level of granularity in frequency counting is the defining strength of the dot plot, allowing analysts to perform quick, exact counts for any specific score without needing to estimate or rely on interval summaries.
Analyzing the Histogram Visualization
Now, let us examine how the same set of 18 values is interpreted and displayed when visualized as a histogram. For this histogram, the data has been aggregated into five distinct bins, or class intervals: 0-2, 2-4, 4-6, 6-8, and 8-10. Note that in standard histogram construction, the bar usually includes the starting value but excludes the endpoint, although presentation methods can vary slightly depending on the software used.

The visualization above clearly demonstrates the principle of binning. The x-axis shows ranges of values (0-2, 2-4, 4-6, 6-8 , 8-10) and the y-axis uses rectangular bars to represent the frequency of individual values in the dataset that fall into each range. For example, we can see that seven values fell in the range of 0 to 2, two values are between 2 and 4, and so on. This means seven of the data points were grouped together in this initial class interval.
While the histogram efficiently communicates that the majority of the data falls within the 0–2 range and that the overall distribution is somewhat skewed towards the lower values, it fundamentally conceals the granular information we gained from the dot plot. Based solely on the histogram, we know seven values are between 0 and 2. However, we cannot determine precisely how many of those seven values were 1s and how many were 2s. This trade-off—sacrificing individual data point visibility for a clearer overview of the aggregate distribution shape—is the central operational characteristic of the histogram.
Generating Visualizations Using R Programming
For readers interested in the technical implementation of these charts, we provide the specific programming commands used to generate the dot plot and histogram examples displayed above. These visualizations were created using R code, a widely used open-source programming language favored by statisticians and data scientists for statistical computing and graphics. The following script defines the dataset and then utilizes standard R functions to produce the required plots.
The code segment below first initializes the dataset variable and then calls upon the stripchart function for the dot plot—specifying parameters like the stacking method and aesthetic choices—and the hist function for the histogram, demonstrating the simplicity of creating these foundational visualizations within the R environment.
#define dataset data <- c(1, 1, 1, 1, 2, 2, 2, 3, 4, 5, 5, 6, 6, 6, 6, 7, 8, 10) #create dot plot stripchart(data, method = "stack", offset = .5, at = 0, pch = 19, cex=5, col = "steelblue", main = "Dot Plot", xlab = "Data Values", ylab="Frequency") #create histogram hist(data, col='steelblue', main='Histogram', xlab='Data Values')
This code illustrates how statistical software standardizes the visualization process. While the histogram function automatically determines optimal bin sizes unless specified otherwise, the dot plot function focuses on accurately representing the frequency of unique observations, confirming their fundamental differences even at the programmatic level.
Dot Plot vs. Histogram: Selecting the Appropriate Visualization Technique
The decision of whether to employ a dot plot or a histogram is not arbitrary; it depends heavily on the size of the sample and the specific analytical objective. As a reliable rule of thumb for effective data communication, analysts typically favor the dot plot when our dataset is small or moderate in size. This preference is driven by the dot plot’s capacity to show the exact frequency of every single value, allowing us to see exactly how many times each individual value occurs. When a dataset is small—perhaps fewer than 50 or 60 observations—the clarity gained from seeing individual counts outweighs any complexity, offering a powerful, unfiltered view of the data’s composition.
Conversely, the histogram becomes the necessary and pragmatic choice when the dataset is large because it’s cumbersome to create a dot to represent every single individual value. This is especially true when the data is continuous and highly varied (i.e., having many unique decimal places). Attempting to create a dot plot for a large dataset would result in an overly dense and complex chart, where columns of dots might stretch impossibly high or where the sheer number of unique values would render the individual counts meaningless. In these large-scale scenarios, aggregation via binning streamlines the visualization, making the underlying shape and general spread of the population distribution readily apparent.
Therefore, the selection criteria boil down to balancing granularity against scalability. If the goal is precision—knowing exactly how many individuals scored a 7 or an 8—the dot plot is unmatched. If the goal is pattern recognition—understanding the overall skewness, modality, and spread of a vast collection of measurements—the histogram is the superior tool, providing a concise summary of the distribution that avoids sensory overload associated with thousands of individual markers.
Limitations and Insights: What Each Plot Conceals
While both visualizations are powerful, they each carry inherent limitations that analysts must recognize when drawing conclusions. Keep in mind that the one drawback of using a histogram is that we can’t tell exactly how many times each individual value occurs. For example, in the histogram from earlier we saw that seven values fell in the range of 0 to 2, but we don’t know exactly how many values were equal to 1 and how many values were equal to 2. Once values are placed into a bin, their precise location within that range is unknown. This ambiguity is the trade-off required for summarizing large datasets.
This lack of individual data specificity in a histogram also restricts the precise calculation of common statistical measures directly from the plot. Also keep in mind that we can’t calculate the exact median or average by just looking at a histogram because we don’t know the individual values. An analyst might be able to estimate the central tendency or the approximate location of the median (the center of the distribution), but for precise calculations, the raw data or the frequencies of specific values are required.
If we’re just interested in understanding the general “shape” of a distribution, then it usually isn’t a big deal that we don’t know the individual values in a dataset. Despite the limitations regarding precise calculation, the histogram remains an indispensable tool for understanding the general shape of a distribution. For most exploratory data analysis where the sheer volume of data makes granular inspection impractical, prioritizing the visual shape of the distribution over the exact count of every single value is generally the accepted and most efficient practice.
Further Exploration of Visualization Techniques
In summary, the choice between a dot plot and a histogram reflects a fundamental decision in data visualization: the trade-off between preserving individual data integrity and providing a scalable, generalized view of the distribution shape. The dot plot is ideal for small, discrete data where exact frequency counts are paramount, while the histogram excels at summarizing large, continuous datasets, providing critical insight into the overall distribution pattern via binning.
Mastering these two techniques forms the bedrock of introductory statistical graphics. For those seeking to deepen their understanding of data visualization, particularly in how frequency distributions are represented, exploring related advanced topics is highly recommended.
The following tutorials offer additional information on histograms:
The following tutorials offer additional information on dot plots:
Cite this article
stats writer (2025). How to Easily Choose Between Dot Plots and Histograms. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/whats-the-difference-between-a-dot-plot-and-histogram/
stats writer. "How to Easily Choose Between Dot Plots and Histograms." PSYCHOLOGICAL SCALES, 3 Dec. 2025, https://scales.arabpsychology.com/stats/whats-the-difference-between-a-dot-plot-and-histogram/.
stats writer. "How to Easily Choose Between Dot Plots and Histograms." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/whats-the-difference-between-a-dot-plot-and-histogram/.
stats writer (2025) 'How to Easily Choose Between Dot Plots and Histograms', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/whats-the-difference-between-a-dot-plot-and-histogram/.
[1] stats writer, "How to Easily Choose Between Dot Plots and Histograms," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Choose Between Dot Plots and Histograms. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.