Table of Contents
An In-Depth Introduction to Heteroscedasticity in Statistical Modeling
In the expansive field of regression analysis, researchers and data scientists frequently encounter a phenomenon known as heteroscedasticity. This term, derived from the Greek words “hetero” (different) and “skedasis” (dispersion), refers to a situation where the variance of the residuals or error terms in a model is not constant across all levels of an independent variable. Understanding this concept is vital because it strikes at the heart of the reliability and interpretability of predictive models, influencing how we perceive the relationship between different datasets.
To grasp the essence of heteroscedasticity, one must first understand the ideal state of homoscedasticity, where the error terms exhibit uniform scatter regardless of the value of the predictor variables. When heteroscedasticity is present, the spread of data points changes systematically, often appearing as a “fan” or “cone” shape when visualized on a scatter plot. This systematic change indicates that the model’s predictive accuracy is varying across the range of the data, which can complicate the process of drawing definitive conclusions from a statistical study.
The presence of non-constant variance often arises from the inherent nature of the data itself or from a failure to account for specific variables within the model. It is not merely a mathematical nuisance but a signal that the underlying assumptions of the most common regression techniques may be compromised. Consequently, identifying, analyzing, and correcting for heteroscedasticity is a fundamental step in ensuring that the insights derived from a regression analysis are both scientifically valid and practically useful for decision-making purposes.
The Mathematical Foundations of Variance in Regression
At its core, regression analysis seeks to minimize the sum of the squared differences between observed values and the values predicted by the model. These differences are known as residuals. In a mathematically sound model, these residuals should behave like random noise, showing no discernible pattern or relationship with the input variables. However, when heteroscedasticity occurs, the variance of these error terms becomes a function of one or more of the independent variables, disrupting the expected randomness.
The implications of this non-constant variance are significant for the estimation process. While the regression coefficients—the slopes and intercepts—may remain unbiased, they are no longer the most efficient estimates possible. This means that while they might point in the right direction, they are not as precise as they could be if the variance were uniform. In statistical terms, the model loses its property of being the “Best Linear Unbiased Estimator” (BLUE), a cornerstone of classical statistical theory.
Furthermore, the mathematical structure of heteroscedasticity often suggests that the model is missing important complexity. It might indicate that the relationship between variables is non-linear, or that there is an interaction effect that has not been properly specified. By examining the variance of the residuals, statisticians can gain deeper insights into the structural integrity of their mathematical models and determine whether the chosen functional form is appropriate for the data at hand.
Why Homoscedasticity is a Critical OLS Assumption
Ordinary Least Squares (OLS) is the most widely used method for estimating the parameters of a linear regression model. For OLS to provide reliable results, it relies on several key assumptions, one of the most critical being homoscedasticity. This assumption posits that the variance of the error term is the same for all observations. When this condition is met, OLS provides the most precise estimates of the relationship between variables, allowing for clear and confident interpretation of the data.
When the assumption of homoscedasticity is violated, the standard OLS formulas for calculating standard errors become inaccurate. Because standard errors are used to calculate t-statistics and p-values, any error in their estimation ripples through the entire hypothesis-testing process. This can lead to a situation where a researcher incorrectly assumes that their results are robust, when in fact the underlying variability of the data is distorting the perceived precision of the model.
In practice, the OLS estimator treats all observations as equally informative. However, in the presence of heteroscedasticity, some observations actually have higher variance and are therefore less “reliable” for determining the position of the regression line than others. By ignoring these differences in reliability, Ordinary Least Squares fails to leverage the full information contained within the dataset, potentially leading to inefficient models that do not perform well when applied to new, unseen data.
The Impact of Heteroscedasticity on Model Accuracy and Inference
The most dangerous consequence of heteroscedasticity is its impact on statistical inference. Because the standard errors are biased, the confidence intervals calculated around the regression coefficients will be either too wide or too narrow. If the standard errors are underestimated, the confidence intervals will be too tight, leading researchers to believe their estimates are more precise than they actually are. This often results in a Type I error, where a variable is deemed to have statistical significance when it actually does not.
Moreover, the inaccuracy of the standard errors invalidates traditional significance tests. When the model fails to account for the increasing or decreasing spread of residuals, the resulting p-values cannot be trusted. In a professional or academic setting, this can lead to the publication of misleading results or the implementation of business strategies based on false premises. The model may appear to have high predictive power on the training data, but its failure to handle variance correctly means it will likely fail in real-world applications.
Beyond hypothesis testing, heteroscedasticity also affects the accuracy of prediction intervals. When using a regression model to forecast future values, the uncertainty surrounding those forecasts should reflect the inherent variability of the data. If the model assumes constant variance, it will provide the same prediction interval width for all inputs. However, if the data is heteroscedastic, the true uncertainty for larger values might be much higher than for smaller values, leading to “surprises” when actual outcomes fall far outside the predicted range.
Visual and Statistical Methods for Detecting Non-Constant Variance
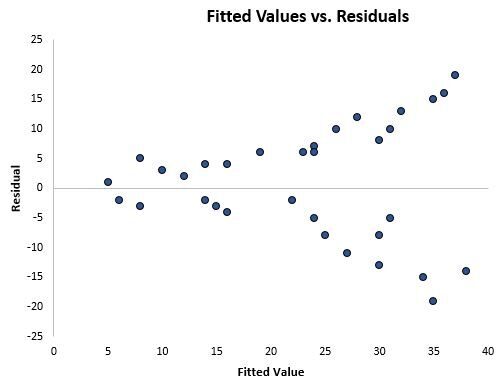
Detecting heteroscedasticity is a critical step in the diagnostic phase of regression analysis. The most intuitive and frequently used method is the visual inspection of a fitted value vs. residual plot. By plotting the predicted values on the x-axis and the residuals on the y-axis, researchers can look for patterns that deviate from a random cloud of points. If the points expand or contract as the fitted values increase, it is a clear indication that the variance is not constant.
Consider the following visual representation of a dataset exhibiting these characteristics:

As observed in the scatterplot, the residuals show a distinct “cone” or “trumpet” shape. This indicates that as the model predicts higher values, the errors become increasingly large and unpredictable. This visual evidence is often sufficient to diagnose the problem, but it is frequently supplemented with formal statistical tests to provide a more rigorous confirmation of the issue.

In addition to visual plots, statisticians often employ formal tests such as the Breusch-Pagan test or the White test. These tests mathematically evaluate whether the variance of the residuals depends on the values of the independent variables. If the resulting p-value from these tests is below a certain threshold (usually 0.05), the null hypothesis of homoscedasticity is rejected, and the researcher must acknowledge the presence of non-constant variance in their model.
Analyzing Common Causes and Real-World Examples
Heteroscedasticity is not an abstract mathematical error but a reflection of real-world complexity. It naturally occurs in datasets where the scale of the observations varies widely. For instance, in economics, the relationship between income and expenditure is a classic example. Individuals with lower incomes have limited discretionary spending power, so their expenditures are relatively predictable and cluster closely together. However, as income increases, the variability in spending habits grows; some wealthy individuals remain frugal, while others spend lavishly, leading to a much wider spread in the data.
Another common cause is the presence of outliers or extreme observations that do not follow the general trend of the data. These points can pull the regression line away from the majority of the data, causing the residuals to fluctuate wildly in certain regions of the model. Furthermore, heteroscedasticity can result from measurement errors that increase in proportion to the magnitude of the variable being measured, a common issue in physical sciences and engineering.
Demographic data also frequently exhibits these traits. Consider a study of city populations versus the number of specialized services, such as flower shops or luxury boutiques. In small towns, the number of such shops is consistently low. In large metropolises, however, the number can vary significantly based on factors like tourism, local culture, and city wealth, even if the total population remains similar. This inherent variability in larger samples makes regression analysis more challenging and necessitates specialized techniques to ensure accuracy.
Data Transformation Strategies to Mitigate Variance Issues
When heteroscedasticity is identified, one of the most effective first steps is to apply a mathematical transformation to the dependent variable. The goal of transformation is to stabilize the variance and make the relationship between variables more linear. The log transformation is particularly popular because it compresses the scale of larger values more than smaller values, effectively “shrinking” the wide end of the cone-shaped residual plot.
For example, if a researcher is modeling the price of real estate based on square footage, they might find that the variance in price is much higher for large mansions than for small apartments. By taking the logarithm of the price, the researcher can often achieve a more uniform distribution of residuals. This makes the OLS assumptions more tenable and allows for more reliable statistical significance testing, although it does change the interpretation of the coefficients to represent percentage changes rather than absolute units.
Other transformations include taking the square root or the inverse of the dependent variable. The choice of transformation depends on the specific nature of the heteroscedasticity observed. While these methods are powerful, they require the researcher to be careful when interpreting the final model. It is always necessary to back-transform the results if the goal is to provide predictions in the original units of measurement, adding a layer of complexity to the final reporting of the analysis.
Advanced Remediation: Weighted Least Squares and Robust Errors
If simple data transformations are insufficient or inappropriate for the research context, more advanced statistical techniques like Weighted Least Squares (WLS) can be employed. Unlike Ordinary Least Squares, which treats all data points as equal, WLS assigns a specific weight to each observation based on the variance of its error term. Data points with low variance are given more weight because they provide more precise information about the regression line, while high-variance points are down-weighted.
This approach effectively “equalizes” the influence of the observations, neutralizing the distorting effects of heteroscedasticity. When the weights are correctly specified—often by using the inverse of the variance—the WLS estimator regains the property of being the Best Linear Unbiased Estimator. However, the challenge lies in accurately estimating the weights, which often requires prior knowledge or a two-step estimation process known as Feasible Generalized Least Squares (FGLS).
Alternatively, researchers can use “robust” standard errors, also known as Huber-White standard errors. This method does not change the regression coefficients themselves but adjusts the standard errors to account for the presence of heteroscedasticity. This allows for valid hypothesis testing and confidence intervals even when the homoscedasticity assumption is violated, making it a highly practical and popular solution in modern econometrics and social science research.
Redefining Variables for Better Model Specification
Sometimes, heteroscedasticity is a symptom of poor model specification rather than an inherent problem with the data. In such cases, redefining the dependent variable can resolve the issue. A common strategy is to convert raw counts or values into rates or per capita measurements. By normalizing the data relative to the size or scale of the observation, the natural increase in variance associated with larger units is often eliminated.
Using the earlier example of flower shops in cities, instead of predicting the total number of shops based on population, a researcher could predict the number of shops per 10,000 residents. This change in perspective often smooths out the variance because it accounts for the fact that larger cities naturally have more of everything. The resulting model focuses on the density of the shops rather than the sheer volume, which is often a more meaningful metric for economic analysis anyway.
Redefining variables also forces the researcher to think more deeply about the theoretical relationship they are modeling. It encourages the inclusion of control variables that might explain the changing variance. By improving the specification of the model, the researcher not only solves a statistical problem but also creates a more nuanced and accurate representation of the real-world phenomenon they are studying, leading to better insights and more reliable conclusions.
Conclusion: Ensuring the Validity of Regression Results
In conclusion, heteroscedasticity is a fundamental concept that every practitioner of regression analysis must master. While it poses a significant threat to the accuracy of standard errors and the validity of statistical inferences, it is also a manageable problem. Through a combination of visual diagnostics, formal testing, and remediation techniques such as Weighted Least Squares or data transformation, the integrity of a regression model can be preserved.
Ignoring the signs of non-constant variance can lead to overconfident predictions and erroneous conclusions. Therefore, the diagnostic phase of modeling is just as important as the estimation phase. A diligent researcher always checks their residuals, ensuring that the assumptions of their chosen statistical method are met. This commitment to rigor is what separates high-quality data science from simple curve-fitting.
Ultimately, the goal of regression analysis is to uncover the truth hidden within data. By understanding and addressing heteroscedasticity, we move one step closer to that goal, producing models that are not only mathematically sound but also practically relevant. Whether you are in academia, finance, or engineering, respecting the nuances of variance is essential for delivering results that stand up to scrutiny and drive meaningful progress.
Cite this article
stats writer (2026). How to Detect and Correct Heteroscedasticity in Regression Analysis. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-the-concept-of-heteroscedasticity-in-regression-analysis-and-how-does-it-affect-the-accuracy-of-results/
stats writer. "How to Detect and Correct Heteroscedasticity in Regression Analysis." PSYCHOLOGICAL SCALES, 1 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-the-concept-of-heteroscedasticity-in-regression-analysis-and-how-does-it-affect-the-accuracy-of-results/.
stats writer. "How to Detect and Correct Heteroscedasticity in Regression Analysis." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-the-concept-of-heteroscedasticity-in-regression-analysis-and-how-does-it-affect-the-accuracy-of-results/.
stats writer (2026) 'How to Detect and Correct Heteroscedasticity in Regression Analysis', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-the-concept-of-heteroscedasticity-in-regression-analysis-and-how-does-it-affect-the-accuracy-of-results/.
[1] stats writer, "How to Detect and Correct Heteroscedasticity in Regression Analysis," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Detect and Correct Heteroscedasticity in Regression Analysis. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.