Table of Contents
Understanding the Fundamentals of Kendall’s Tau
In the vast field of statistics, researchers often seek to quantify the degree to which two variables move in tandem. This relationship is formally known as correlation, a measure that describes both the strength and the direction of a linear or monotonic association. While many are familiar with traditional methods, Kendall’s Tau serves as a robust non-parametric alternative. Unlike parametric tests that require data to follow a specific normal distribution, Kendall’s Tau makes no such assumptions, making it exceptionally versatile for analyzing real-world data that may be skewed or contain outliers.
The primary utility of Kendall’s Tau lies in its ability to handle ordinal data, where variables have a clear, inherent order but the numerical distance between them is not necessarily uniform. For instance, ranking preferences, educational levels, or socio-economic statuses often requires a measure that respects the relative positioning of data points rather than their absolute values. By focusing on the rank of the observations, this coefficient provides a reliable estimate of association that is less sensitive to the specific magnitudes of the data points, thereby offering a clearer picture of the underlying trend.
Mathematically, the coefficient ranges from -1 to 1. A value of 1 represents a perfect positive correlation, where the rankings of both variables are identical. Conversely, a value of -1 indicates a perfect negative correlation, where the rankings are exactly reversed. A value of 0 suggests that there is no observable relationship between the two sets of rankings. Because it relies on the counting of concordant and discordant pairs, it offers a more intuitive grasp of probability—specifically, the difference between the probability that the observed data are in the same order versus the probability that they are in a different order.
Beyond its theoretical elegance, Kendall’s Tau is frequently employed in diverse fields such as psychology, economics, and bioinformatics. It is particularly useful when sample sizes are small or when the data set contains many tied ranks, though specific variations of the formula exist to account for such ties. By providing a clear statistical measure of association, it allows researchers to draw meaningful conclusions from data that might otherwise be difficult to interpret using standard linear regression models.
Distinguishing Kendall’s Tau from Other Correlation Measures
When selecting a correlation coefficient, practitioners must choose between several distinct methodologies, most notably the Pearson correlation coefficient and Spearman’s rank correlation coefficient. Pearson’s method is the gold standard for continuous, normally distributed data where a linear relationship is expected. However, it is highly susceptible to outliers, which can drastically distort the resulting coefficient. In contrast, Spearman’s rho and Kendall’s Tau are both rank-based and thus more resilient to extreme values and non-linear (but monotonic) relationships.
While Spearman’s rho is often more popular in social science literature, Kendall’s Tau possesses several advantages, particularly in terms of its mathematical properties. Specifically, it has a smaller gross error sensitivity and is considered more robust than Spearman’s rho. In many cases, the p-values generated by Kendall’s Tau are more accurate with smaller sample sizes. Furthermore, the interpretation of Kendall’s Tau is often considered more direct: it represents the difference between the probability of the data being in the same order versus the probability of them being in a different order.
Choosing the correct measure involves evaluating the level of measurement of your variables and the distribution of your data. If your data is continuous and follows a bell curve, Pearson is appropriate. If your data is ordinal or non-normal, you should lean toward Spearman or Kendall. Kendall’s Tau is especially favored when the dataset is small or when researchers need a coefficient that provides a more conservative and stable estimate of the relationship. This stability is crucial when the goal is to generalize findings from a limited set of observations to a broader population.
It is also worth noting that while Spearman and Kendall often yield different numerical values for the same dataset, they generally lead to the same statistical significance conclusions. Kendall’s Tau values are typically smaller in absolute magnitude than Spearman’s rho values, but this does not imply a weaker relationship; rather, it reflects a different underlying logic of calculation. Understanding these nuances ensures that the data scientist or researcher applies the most statistically sound method for their specific research question, maintaining the integrity of their quantitative analysis.
The Mathematical Framework and Core Formula
The calculation of Kendall’s Tau is centered on the concept of pairs of observations. For any two variables, we examine all possible pairs of data points to determine if they are concordant or discordant. A pair is considered concordant if the ranks for both elements agree—that is, if both members of one pair are higher or lower than the members of the other pair. Conversely, a pair is discordant if the ranks disagree. This focus on pairwise comparisons is what allows the measure to remain non-parametric and effective for ranked data.
The standard formula for calculating the coefficient, often denoted by the Greek letter τ (tau), is expressed as follows:
τ = (C – D) / (C + D)
In this equation, the variables are defined as:
- C: The total number of concordant pairs within the dataset.
- D: The total number of discordant pairs within the dataset.
The denominator, (C + D), represents the total number of pairs compared. This can also be calculated using the combination formula n(n-1)/2, where n is the number of observations. By dividing the difference between concordant and discordant pairs by the total number of pairs, we normalize the result to a range between -1 and 1, facilitating easy comparison across different studies and datasets.
This approach to correlation is fundamentally grounded in combinatorics. By evaluating every possible pairing, the test captures the global structure of the data’s ordering. This is particularly useful in identifying whether an increase in one variable is consistently associated with an increase in another, regardless of whether that increase follows a straight line. Because the formula relies on the sign of the difference between pairs rather than the magnitude of the difference, it effectively ignores variance inconsistencies that would otherwise plague parametric tests.
Moreover, the formula provided above is specifically known as Tau-a, which is most applicable when there are no tied ranks in the data. When ties are present—meaning multiple observations share the same rank—more complex versions like Tau-b or Tau-c are utilized. These adjustments ensure that the correlation coefficient remains accurate even when the data is “noisy” or when the ranking system is not granular enough to distinguish between every single observation. Such mathematical flexibility makes Kendall’s Tau a cornerstone of robust statistics.
Practical Application: A Coaching Rank Case Study
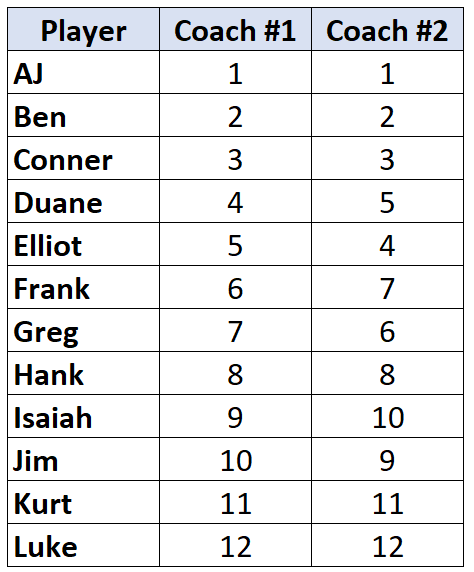
To better illustrate the practical application of Kendall’s Tau, consider a scenario involving athletic evaluation. Suppose two professional basketball coaches are asked to evaluate and rank 12 of their players based on their overall performance throughout a season. Each coach provides a ranking from 1 (the best player) to 12 (the worst player). Because the data is provided in ranks, a standard Pearson correlation would be inappropriate, as we cannot assume the “distance” between the 1st and 2nd player is the same as the distance between the 11th and 12th player.
The following table presents the rankings assigned by the two coaches for the 12 players:

In this instance, Kendall’s Tau is the ideal statistical test to determine the level of agreement between the two experts. If the coaches have a high degree of consensus, we would expect a Tau value close to 1. If their evaluations are entirely contradictory, the value would approach -1. This type of analysis is vital in fields like human resources, sports management, and peer review, where subjective rankings must be synthesized into objective conclusions.
The process of calculation involves organizing the data based on the ranks of the first coach and then examining the sequence of the second coach’s ranks. By doing so, we can systematically identify how many times the second coach agreed with the relative ordering established by the first coach. This systematic comparison allows us to quantify “expert agreement” in a way that is mathematically rigorous and resistant to the biases that might occur if we simply averaged the scores.
Ultimately, the goal of this exercise is to derive a single numerical value that summarizes the inter-rater reliability. In many research contexts, establishing this reliability is a prerequisite for further data analysis. If the two coaches do not agree, the rankings may be considered unreliable for making personnel decisions. However, if Kendall’s Tau reveals a high and statistically significant correlation, the organization can proceed with confidence, knowing that their evaluation process is consistent across different observers.
Identifying Concordant Pairs in Ranked Datasets
The first intensive step in calculating Kendall’s Tau is to determine the number of concordant pairs (C). To begin, we sort the data based on the rankings of the first variable (Coach #1). This simplifies the process because the first variable is now in a natural ascending order (1, 2, 3, …). We then focus exclusively on the rankings provided by Coach #2 to see how well they align with this ascending sequence. A pair is concordant if a rank appearing later in the list is larger than the rank currently being evaluated.
Let us walk through the initial calculation. Starting with the first player in the sorted list (AJ), Coach #2 assigned a rank of “1”. We then look at all the ranks below “1” in Coach #2’s column. Since “1” is the smallest possible rank, all 11 subsequent ranks are larger than “1”. Therefore, we record 11 concordant pairs for the first entry:

We then move to the second player, Billy, who was ranked “2” by Coach #2. Examining the remaining 10 ranks below him, we find that all 10 are larger than “2”. Thus, we add 10 to our concordant count. This pattern continues until we encounter a deviation in the natural order:

A critical nuance occurs when a rank is smaller than the one preceding it in the sequence. For example, Elliot is ranked “4” while the player above him (Dan) was ranked “5”. When calculating concordant pairs for Elliot, we only look at the ranks *below* him. Since we are looking for values larger than “4” among the remaining players, we count how many of the remaining ranks satisfy this condition. The process is repeated meticulously for every player in the list to ensure no pair is overlooked:

By the time we reach the final player, we have a complete list of concordant counts for each position. Summing these values provides the total C. This value represents the aggregate frequency with which the two coaches agreed on the relative “better than” or “worse than” status of the players. The higher this sum, the more the two sets of ranked data are in harmony:

Determining Discordant Pairs and Finalizing the Calculation
After finding the concordant pairs, the next phase is to calculate the discordant pairs (D). A pair is discordant if the relative ordering of two players is reversed between the two coaches. In our sorted list, this means looking at Coach #2’s rankings and counting how many ranks below a specific player are *smaller* than that player’s rank. Discordance represents a direct disagreement between the evaluators regarding who is the superior player in a specific pairing.
Using the same dataset, we look at AJ again. Coach #2 ranked him “1”. Since no rank can be smaller than 1, there are 0 discordant pairs below him. Moving down to Dan, who was ranked “5”, we look at the ranks below him and find that Elliot was ranked “4”. Because 4 is smaller than 5, this constitutes one discordant pair. We record these values for every player:

This systematic tallying continues through the entire list of 12 players. Each time a rank is “out of place” (i.e., smaller than a rank appearing above it), it contributes to the discordant count. This process captures every instance of ranking inversion. Once we have completed this for all individuals, we sum the discordant column to find our total D:

With both C and D identified, we can finally apply the Kendall’s Tau formula. In our basketball coach example, the sum of concordant pairs (C) is 63, and the sum of discordant pairs (D) is 3. Plugging these into our formula yields a result that quantifies the relationship:

τ = (63 – 3) / (63 + 3) = 60 / 66 = 0.909
A result of 0.909 is an extremely high correlation coefficient. It indicates that the two coaches are in very strong agreement regarding the talent of the players. While they do not agree perfectly—as evidenced by the 3 discordant pairs—their overall assessment of the team’s hierarchy is remarkably consistent.
Assessing Statistical Significance and Z-Scores
While calculating the Kendall’s Tau coefficient provides a descriptive measure of the relationship, it does not tell us whether that relationship is statistically significant or if it could have occurred by sheer chance. To determine this, we must perform a hypothesis test. For sample sizes larger than 10 (n > 10), the distribution of Kendall’s Tau tends to approximate a normal distribution, allowing us to calculate a z-score.
The z-score formula for Kendall’s Tau is as follows:
z = 3τ * √n(n – 1) / √2(2n + 5)
In this formula, τ is the coefficient we calculated (0.909) and n is the number of pairs (12). By substituting our values into the equation, we can derive the standardized score:
z = 3(0.909) * √12(11) / √2(24 + 5) = 2.727 * √132 / √58 = 2.727 * 11.489 / 7.615 = 4.11
A z-score of 4.11 is quite high. To find the associated p-value, we compare this score to a standard normal distribution table. A z-score of 4.11 corresponds to a p-value of approximately 0.00004. Since this value is far below the standard alpha level of 0.05, we reject the null hypothesis that there is no relationship between the rankings.
Rejecting the null hypothesis allows us to conclude with high confidence that the agreement between the coaches is not a fluke. This step is essential in inferential statistics, as it provides the mathematical justification needed to support the findings. Without testing for significance, even a high Tau value could be misleading, especially if the sample size were very small. In this case, the combination of a high coefficient and a very low p-value strongly suggests a genuine consensus in the evaluation process.
Executing Kendall’s Tau Using the R Programming Language
In modern data science, manual calculations are rarely performed outside of academic settings. Instead, statistical software is used to process large datasets quickly and accurately. The R programming language is one of the most powerful tools available for this purpose. To calculate Kendall’s Tau in R, one can utilize the kendall.tau() function, which is found in the VGAM library. This allows for seamless exploratory data analysis and hypothesis testing.
To implement this, you first need to install and load the necessary package. Then, define your data as numerical vectors. The syntax is straightforward: kendall.tau(x, y), where x and y represent the two sets of rankings or continuous data points you wish to compare. Below is the R code used to replicate our basketball coach calculation:
#load VGAM library(VGAM) #create vector for each coach's rankings coach_1 <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12) coach_2 <- c(1, 2, 3, 5, 4, 7, 6, 8, 10, 9, 11, 12) #calculate Kendall's Tau kendall.tau(coach_1, coach_2) #[1] 0.9090909
The output 0.9090909 confirms our manual calculation, demonstrating the precision of the software. Using R also provides access to more advanced variations of the test, such as those that handle ties automatically. This is particularly useful when dealing with big data where manual checking for concordant and discordant pairs would be impossible.
Furthermore, R provides extensive documentation and community support for its statistical functions. Beyond just the coefficient, R can easily produce confidence intervals and detailed summaries of the test statistics. This makes it an indispensable environment for quantitative researchers who require reproducible and verifiable results. By integrating these computational tools, analysts can focus more on interpreting the results and less on the mechanical aspects of the arithmetic.
Real-World Applications and Interpretive Nuances
Understanding Kendall’s Tau extends beyond just knowing the formula; it involves knowing when and where to apply it for maximum impact. In the medical field, for instance, it is often used to compare the diagnostic rankings of two different imaging techniques or the assessments of two different doctors. In bioinformatics, it helps in comparing the expression levels of genes across different experimental conditions, where the data might not meet the strict requirements of parametric statistics.
One must also be aware of the “ties” problem. In many real-world datasets, two items may receive the same rank. This is common in survey data where multiple respondents might give the same score to a product. In such instances, the standard Tau-a formula is insufficient because it doesn’t account for the fact that a tie is neither concordant nor discordant. Utilizing Tau-b or Tau-c adjustments is necessary to ensure the correlation coefficient is not artificially deflated or inflated by these tied observations.
Finally, it is important to remember that correlation does not equal causation. Even a perfect Kendall’s Tau of 1.0 only indicates that the two variables move in the same relative order; it does not prove that one variable causes the other to change. However, as a measure of monotonic association, it is one of the most reliable and robust tools in a statistician’s arsenal. Whether you are a student, a researcher, or a data analyst, mastering Kendall’s Tau provides a sophisticated way to uncover and quantify the hidden relationships within your data.
Cite this article
stats writer (2026). How to Calculate and Interpret Kendall’s Tau for Ranking Data. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-kendalls-tau-and-can-you-provide-an-example-of-its-use/
stats writer. "How to Calculate and Interpret Kendall’s Tau for Ranking Data." PSYCHOLOGICAL SCALES, 7 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-kendalls-tau-and-can-you-provide-an-example-of-its-use/.
stats writer. "How to Calculate and Interpret Kendall’s Tau for Ranking Data." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-kendalls-tau-and-can-you-provide-an-example-of-its-use/.
stats writer (2026) 'How to Calculate and Interpret Kendall’s Tau for Ranking Data', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-kendalls-tau-and-can-you-provide-an-example-of-its-use/.
[1] stats writer, "How to Calculate and Interpret Kendall’s Tau for Ranking Data," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Calculate and Interpret Kendall’s Tau for Ranking Data. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.