Table of Contents
Foundations of Simple Linear Regression in Statistical Analysis
Simple linear regression serves as one of the most fundamental techniques within the broader field of statistics and data analysis. At its core, this method is designed to model the relationship between two continuous variables by fitting a linear equation to the observed data. By establishing a functional connection between an independent factor and a dependent outcome, researchers and analysts can discern patterns that might otherwise remain hidden within raw datasets. This mathematical approach is not merely about drawing lines; it is about quantifying the degree to which changes in one aspect of a system influence another, providing a rigorous framework for predictive modeling across diverse industries such as economics, medicine, and social sciences.
The primary objective of simple linear regression is to find a line that represents the data as accurately as possible, minimizing the discrepancy between the observed values and the values predicted by the model. This process allows for the identification of the strength of the association and the direction of the trend—whether positive, negative, or non-existent. In a world increasingly driven by data-centric decision-making, mastering this tool is essential for anyone looking to draw meaningful conclusions from empirical evidence. It acts as the building block for more complex methodologies, such as multiple regression, by introducing the core concepts of error minimization and parameter estimation.
To understand how this works in practice, consider the necessity of isolating variables. In regression analysis, we assume that the relationship between the variables can be described by a straight line. While real-world data is rarely perfectly linear due to inherent noise and external influences, the linear model provides a powerful approximation that simplifies complex interactions into an interpretable format. This simplification is the hallmark of effective statistical modeling, enabling professionals to communicate findings with clarity and precision while maintaining a high level of scientific rigor.
Defining the Variables: Predictors and Responses
In any simple linear regression model, the focus is strictly on two specific types of variables. The first is the predictor variable, commonly denoted as x. This is also referred to as the independent variable, as it is the factor that is either controlled or observed to see how it affects the other variable. In the context of experimental design, the predictor is the input that we believe drives a change in the system. For instance, in a study of crop yields, the amount of rainfall might serve as the predictor variable.
The second component is the response variable, denoted as y, also known as the dependent variable. The value of the response variable depends on the state of the predictor. The goal of the regression model is to determine the extent to which y changes when x is modified. By distinguishing between these two roles, we can structure our analysis to answer specific questions about causality and correlation. It is important to note that while regression indicates a relationship, it does not strictly prove causation without further experimental controls.
To illustrate these concepts, let us examine a specific scenario involving biological measurements. Suppose we have collected a dataset containing the weight and height of seven unique individuals. In this case, we are interested in seeing if a person’s weight can help us predict their height. The raw data for this example is presented in the table below, showcasing the paired observations that will form the basis of our statistical inquiry:

In this specific context, we define weight as our predictor variable (x) and height as our response variable (y). By organizing the data in this manner, we set the stage for visual exploration and mathematical modeling. This structural clarity is vital, as it dictates how the data will be plotted on a coordinate plane and how the resulting regression equation will be interpreted in real-world terms.
Visualizing Data Trends Through Scatter Plots
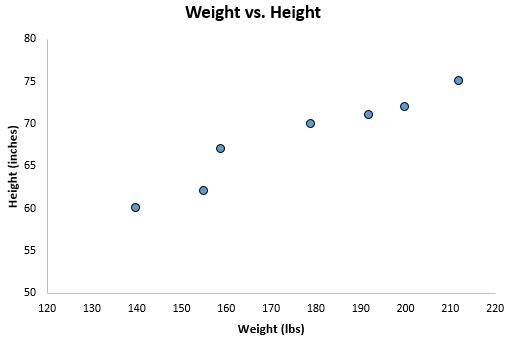
Before performing any complex calculations, the first step in data analysis is often visual inspection. A scatter plot is the most effective tool for this purpose. By plotting each pair of weight and height measurements as a single point on a two-dimensional graph, we can immediately see the distribution of the data. The x-axis represents our predictor (weight), while the y-axis represents our response (height). This visual representation allows us to identify potential outliers, clusters, and the general trend of the relationship.
When we graph the weight and height data of our seven individuals, a clear pattern begins to emerge. Below is the scatterplot generated from our dataset:

Upon reviewing this scatter plot, it is evident that as the weight of an individual increases, their height generally tends to increase as well. This upward trajectory suggests a positive linear relationship. However, visualization alone is insufficient for precise scientific work. While we can see the trend, we cannot yet determine exactly how much height increases for every additional pound of weight. To quantify this relationship and move beyond visual intuition, we must apply the formal mathematical procedures of regression analysis.
The scatter plot serves as a diagnostic tool, helping us decide if a linear model is appropriate. If the points were scattered randomly with no discernible shape, or if they followed a curved path, a simple linear model would be unsuitable. In our case, the points appear to cluster along a roughly straight path, justifying the use of a least squares regression line to summarize the data. This line will act as a “best fit” that represents the average relationship between the variables across the entire range of the observed data.
The Mathematical Framework: The Least Squares Regression Line
The “line of best fit” in simple linear regression is mathematically defined as the least squares regression line. The name “least squares” comes from the fact that the line is calculated by minimizing the sum of the squares of the vertical deviations between each data point and the line itself. These deviations are known as residuals. By squaring these values, we ensure that positive and negative errors do not cancel each other out, and we place a higher penalty on larger discrepancies, resulting in a line that stays as close to all points as possible.
The standard formula for this linear equation is expressed as follows:
ŷ = b0 + b1x
In this equation, several critical components must be understood:
- ŷ (y-hat): This represents the predicted value of the response variable for a given value of x.
- b0: This is the y-intercept, representing the value of y when x is equal to zero.
- b1: This is the regression coefficient or slope, indicating the change in y for every one-unit increase in x.
- x: This is the specific value of the predictor variable being used to make the prediction.
Calculating these parameters manually involves complex summations, but modern statistics software and calculators streamline this process. By determining the exact values of b0 and b1, we transform a collection of disparate data points into a functional model that can be used for estimation and inference. This linear equation provides a concise summary of the data’s behavior, allowing us to describe the “typical” relationship between weight and height in our sample population.
Calculating and Mapping the Regression Equation
To find the specific least squares regression line for our weight and height dataset, we can utilize computational tools. By inputting our coordinates into a regression calculator, the underlying algorithms process the data to yield the most accurate intercept and slope coefficients. This automation reduces the risk of human error and allows for the processing of much larger datasets than would be feasible by hand.

Based on the calculations provided by the tool, our specific least squares regression line is identified as:
ŷ = 32.7830 + 0.2001x
When we overlay this mathematical line onto our original scatter plot, we can visually confirm its accuracy. The line passes through the center of the cloud of data points, balancing the distances above and below it perfectly. This visualization reinforces the concept that the regression line represents the collective trend of the data rather than any single individual observation. It provides a generalized path that summarizes the association between the two variables.

Note how the data points are tightly clustered around the line. This proximity is a strong indicator of a high-quality fit. In regression analysis, the closer the observed points are to the regression line, the more reliable the model is for making predictions. If the points were widely dispersed, the line would still represent the average trend, but our confidence in individual predictions would be significantly lower. The visual alignment here suggests that weight is a powerful predictor of height within this specific group.
Interpreting the Regression Coefficients
Understanding the numerical output of a simple linear regression model requires a careful interpretation of the coefficients. These numbers are not just abstract values; they provide tangible insights into the relationship between the variables. In our model, ŷ = 32.7830 + 0.2001x, we must break down what the intercept and the slope tell us about human height and weight.
The y-intercept, b0 = 32.7830, represents the predicted height when weight is exactly zero. In many statistical models, the intercept is a purely mathematical anchor used to position the line and may not have a practical real-world meaning. This is certainly the case here; since it is biologically impossible for a person to weigh zero pounds, the value of 32.7830 inches does not describe a real human being. However, it remains a necessary part of the linear equation to ensure the slope is correctly calibrated for the range of data we actually observed.
The slope, b1 = 0.2001, is the most critical part of the interpretation. It tells us that for every one-pound increase in weight, the model predicts an average increase in height of approximately 0.2001 inches. This coefficient quantifies the rate of change. Because the value is positive, we confirm a positive correlation. If the slope were negative, it would indicate that as weight increases, height decreases. The magnitude of the slope (0.2001) gives us a precise measure of the sensitivity of the response variable to changes in the predictor.
Applying the Model for Predictive Analytics
The practical utility of simple linear regression lies in its ability to generate predictions for new observations. By plugging a known value of x (weight) into our equation, we can calculate an expected value for y (height). This application is widely used in predictive modeling to estimate outcomes where only the predictor is available. For example, if we encounter a new individual whose weight is known, we can use the model to provide a statistically grounded estimate of their height.
Let’s apply this to two specific examples based on our model:
- Example 1: For a person weighing 170 pounds, we calculate height as: ŷ = 32.7830 + 0.2001(170) = 66.8 inches.
- Example 2: For a person weighing 150 pounds, we calculate height as: ŷ = 32.7830 + 0.2001(150) = 62.798 inches.
While these predictions are powerful, they must be used with caution. A critical rule in statistics is to avoid extrapolation. This means you should only use the regression equation to make predictions within the range of the data used to create the model. In our dataset, the weights ranged from 140 lbs to 212 lbs. Therefore, our model is reliable for predicting heights of people within that weight range. Attempting to predict the height of someone weighing 50 lbs or 500 lbs using this specific equation would likely lead to inaccurate and misleading results, as the linear relationship may not hold true at those extremes.
Measuring Model Accuracy: The Coefficient of Determination
Once a least squares regression line is established, we must evaluate how well it actually explains the data. The standard metric for this evaluation is the coefficient of determination, denoted as R2. This value represents the proportion of the variance in the response variable (height) that can be explained by the predictor variable (weight). It is a measure of the “goodness of fit” for our model.
The R2 value ranges from 0 to 1, or 0% to 100%. A value of 0 indicates that the model explains none of the variability, while a value of 1 indicates a perfect fit where every data point falls exactly on the regression line. In most real-world data analysis, we look for a high R2 to indicate a strong relationship. For instance, an R2 of 0.77 would mean that 77% of the change in height is attributable to weight, while the remaining 23% is due to other factors or random noise.
In our weight-height example, the calculator provided an R2 of 0.9311. This is an exceptionally high value, indicating that 93.11% of the variability in height is explained by weight. This confirms that weight is a very strong predictor for height in this dataset. The high coefficient of determination gives us significant confidence in the model’s ability to represent the underlying pattern of the data.

Core Assumptions of the Linear Regression Model
For the results of any simple linear regression to be considered valid and statistically significant, the data must satisfy four fundamental assumptions. These criteria ensure that the residuals (the errors between observed and predicted values) behave in a way that doesn’t bias the model. Violating these assumptions can lead to inaccurate coefficients, misleading p-values, and unreliable predictions. The four pillars are:
- Linearity: The relationship between the predictor (x) and the response (y) must be linear. This means that for every unit change in x, the change in y remains constant. If the relationship is curved, a different type of regression analysis is required.
- Independence: The observations must be independent of one another. This is particularly important in time-series data, where one observation might influence the next. In our height-weight study, this means one person’s measurements should not affect another’s.
- Homoscedasticity: This refers to “constant variance.” The residuals should have the same spread across all levels of the predictor variable. If the errors get larger as x increases, the assumption of homoscedasticity is violated.
- Normality: The residuals of the model should follow a normal distribution. While the raw data itself doesn’t always have to be normal, the errors produced by the model should be bell-shaped and centered around zero for the most reliable statistical inference.
Checking these assumptions is a vital step in the workflow of a professional data scientist. Techniques such as plotting residuals against predicted values or using a Q-Q plot can help verify these conditions. By ensuring these four assumptions are met, you can be confident that your simple linear regression model is a robust and accurate representation of the real-world relationship you are investigating.
Cite this article
stats writer (2026). How to Understand and Apply Simple Linear Regression. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-introduction-to-simple-linear-regression/
stats writer. "How to Understand and Apply Simple Linear Regression." PSYCHOLOGICAL SCALES, 28 Feb. 2026, https://scales.arabpsychology.com/stats/what-is-introduction-to-simple-linear-regression/.
stats writer. "How to Understand and Apply Simple Linear Regression." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-introduction-to-simple-linear-regression/.
stats writer (2026) 'How to Understand and Apply Simple Linear Regression', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-introduction-to-simple-linear-regression/.
[1] stats writer, "How to Understand and Apply Simple Linear Regression," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Understand and Apply Simple Linear Regression. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.