Table of Contents
High Dimensional Data (HDD) represents datasets characterized by a significantly large number of features or variables. While the term might intuitively suggest any dataset with many columns, its formal definition is tied to the critical ratio of variables versus observations. These complex datasets are notoriously challenging to analyze, visualize, and model effectively due to the intricate relationships that emerge across numerous dimensions. The sheer volume of interconnected variables increases computational complexity and introduces severe statistical challenges, often leading to sparsity and instability in predictive models.
This type of data structure is fundamental across modern computational fields, forming the bedrock of advanced applications in Machine Learning, artificial intelligence, and deep learning. However, successfully extracting meaningful insights from HDD requires specialized techniques, as traditional statistical methods often fail or become computationally infeasible when dealing with hundreds or thousands of dimensions simultaneously. Understanding the nature and specific challenges of HDD is paramount for data scientists aiming to build robust and predictive models across various scientific and commercial disciplines.
The Formal Definition of High Dimensionality
Formally, a dataset is classified as High Dimensional Data when the number of features or variables, denoted by p, is significantly greater than the number of observations or data points, denoted by N. This relationship is often summarized mathematically as $p > N$ or, more strictly in statistical literature, $p gg N$. This condition is critical because it fundamentally alters the statistical properties of the dataset and severely compromises the reliability of traditional analytical methods applied to it.
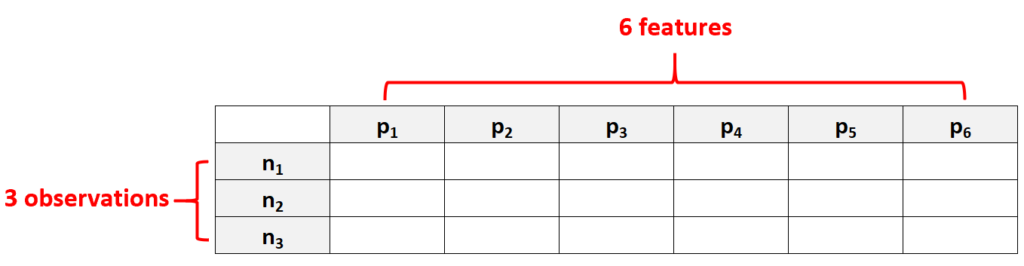
Consider a small-scale example to illustrate this concept: if a dataset contains $p = 6$ distinct features but only $N = 3$ recorded observations, it meets the criterion for high dimensionality ($6 > 3$). In such scenarios, the available data points are insufficient to capture the complexity and variance introduced by the numerous features, leading to situations where standard statistical models become unstable, underdetermined, or impossible to solve deterministically.
It is crucial to distinguish high dimensionality from merely large datasets. A common misconception is equating “high dimensional” solely with having a vast count of features. For instance, a dataset containing 10,000 features is certainly large, but if it also possesses 100,000 observations, it is generally not considered high dimensional in the statistical sense because $N gg p$. The definition hinges on the critical imbalance between the features and the sample size.

For readers seeking a rigorous mathematical exploration of the underlying statistical theory and the proof points supporting the $p gg N$ requirement, we recommend consulting advanced academic texts. Specifically, referring to Chapter 18 in relevant econometric or statistical learning literature offers a detailed examination of the proofs involved in high-dimensional estimation.
The Phenomenon of the Curse of Dimensionality
The central problem intrinsically linked to High Dimensional Data is the inevitable emergence of the Curse of Dimensionality. This term, originally coined by Richard Bellman, describes various counter-intuitive phenomena that arise when analyzing and organizing data in high-dimensional spaces that do not occur in low-dimensional settings. As the number of dimensions (features) increases, the volume of the space increases exponentially, meaning that the available data becomes increasingly sparse.
In simpler terms, to maintain the same data density when moving from a two-dimensional space to a three-dimensional space, one needs exponentially more data points. When dealing with hundreds or thousands of dimensions, the data points become isolated, and the concept of ‘proximity’ or ‘distance’—which is fundamental to many Machine Learning algorithms like K-Nearest Neighbors and clustering methods—loses its practical meaning. Nearly all pairs of points become roughly equidistant from one another, dissolving local structure and making traditional inference techniques highly unreliable.
Furthermore, the Curse of Dimensionality significantly exacerbates the risk of overfitting. When the number of features is much greater than the number of observations ($p gg N$), it is statistically easy for a complex model to find spurious correlations that fit the training data perfectly but generalize extremely poorly to unseen data. This lack of robustness undermines the model’s predictive utility, forcing practitioners to employ specialized techniques like penalization methods or data projection to mitigate these pervasive issues.
Challenges Associated with High Dimensional Data
The core challenge posed by the condition where the number of features ($p$) far exceeds the number of observations ($N$) is the loss of statistical identifiability. This means we cannot obtain a deterministic or unique solution for many standard modeling techniques. In this regime, the system is fundamentally underdetermined. For instance, in multivariate statistical analysis or standard linear regression, if $p > N$, the design matrix is column rank deficient, making it mathematically impossible to invert the necessary matrices to find unique parameter estimates using traditional methods like Ordinary Least Squares (OLS).
Statistically, this means that multiple different models—potentially an infinite number of highly complex models—can perfectly explain the observed data. Without sufficient observations, the model lacks the necessary informational variance to isolate the true, underlying relationship between the predictor variables and the response variable. The resulting model becomes susceptible to high variance and unstable predictions, rendering it practically useless for inference or reliable forecasting outside the training sample.
Beyond mathematical instability, high dimensionality dramatically increases the computational burden. Algorithms designed for low-dimensional data often scale poorly, with execution time increasing exponentially with the number of dimensions. Data storage, memory usage, and the time required for optimization routines all inflate considerably, making iterative model development and hyperparameter tuning a significant logistical and financial hurdle. This necessitates careful selection of algorithms that are intrinsically more scalable and less prone to the difficulties imposed by the Curse of Dimensionality.
Real-World Applications Featuring High Dimensional Data
The occurrence of High Dimensional Data is not confined to theoretical scenarios; it is a pervasive challenge across numerous scientific and commercial domains where detailed measurements are collected on limited sample sizes. Examining specific industry examples helps solidify the understanding of why $p gg N$ frequently arises in practice, particularly in specialized research areas.
Healthcare and Personalized Medicine Datasets
In healthcare and personalized medicine, datasets frequently become high dimensional due to the necessity of intense scrutiny required for individual patient profiles. The number of recorded features for a single patient can be staggering: detailed physiological metrics (blood pressure, resting heart rate), comprehensive laboratory results (hundreds of biomarkers), immunological status indicators, extensive surgical and clinical history, complex imaging data, and lifestyle factors. While the number of potential features ($p$) might reach thousands, the number of patients ($N$) in a specific, highly controlled clinical trial, especially for rare diseases or novel treatments, might be restricted to a few dozen.
This imbalance necessitates sophisticated Machine Learning models capable of identifying signal within noisy, sparse feature spaces without collapsing into overfitting. The goal is often to predict disease risk or treatment efficacy based on this massive feature set, highlighting the constant struggle to gain predictive power despite the statistical limitations imposed by high dimensionality.

Genomics and Molecular Biology Datasets
The field of genomics represents perhaps the most definitive and historically significant example of High Dimensional Data. When analyzing gene expression, the features ($p$) correspond to the thousands or even tens of thousands of genes being measured simultaneously, or the millions of single-nucleotide polymorphisms (SNPs) across the genome. For instance, a gene expression microarray might measure the activity level of 20,000 unique genes for a single tissue sample.
Conversely, obtaining observations ($N$)—samples from individuals undergoing a specific treatment or suffering from a rare condition—is often difficult, ethically complex, and expensive, resulting in cohort sizes that rarely exceed a few hundred. Thus, genetic studies frequently face the acute challenge of $p gg N$. Analyzing gene expression data requires powerful dimensionality reduction techniques to distill the massive feature space down to the handful of truly relevant genetic markers that drive a specific biological outcome.

Financial and Economic Modeling Datasets
In finance, high dimensionality often arises when attempting to model the behavior of limited assets over short timeframes or when utilizing complex quantitative signals. For a single stock, the features ($p$) can include a vast array of technical indicators, macroeconomic variables, proprietary sentiment scores derived from news feeds, and fundamental metrics (P/E Ratio, Market Cap, Trading Volume, Dividend Rate, volatility measures, etc.).
If an analyst attempts to model a small portfolio of, say, fifty individual stocks ($N=50$), and uses hundreds of daily predictors ($p=300$) for each, the resulting dataset is severely high dimensional relative to the sample size. This sparsity introduces significant noise and risk of false discovery in algorithmic trading models, emphasizing the critical need for robust Regularization methods to stabilize parameter estimates and prevent excessive risk-taking based on spurious correlations uncovered during model training.

Strategies for Mitigating High Dimensionality
Addressing the inherent instability and sparsity caused by the Curse of Dimensionality requires a shift from standard statistical modeling to advanced dimensionality management strategies. These strategies primarily fall into three complementary categories: feature selection, dimensionality reduction, and model regularization. By applying these techniques, practitioners aim to reduce the effective number of dimensions while preserving the maximum amount of meaningful variance in the data structure.
Method 1: Feature Selection and Screening
The most straightforward approach to managing High Dimensional Data is to deliberately reduce the number of features ($p$) included in the analysis. This process, known as feature selection, focuses on identifying and retaining only the variables that contribute most significantly to the predictive power of the model. This is often an iterative, domain-specific process based on both statistical criteria and expert knowledge.
Several screening techniques are commonly employed to simplify the feature space prior to model training:
- Dropping Features with Excessive Missing Values: If a variable column contains a high percentage of missing data points, imputing these values may introduce substantial bias or unwarranted noise. Dropping such features is often a necessary and pragmatic solution, provided the information loss from removal is deemed minimal.
- Removing Features Exhibiting Low Variance: Variables whose values change very little across all observations (i.e., low variance) are unlikely to discriminate effectively between different outcomes or response variables. These features contribute little useful signal and, due to their near-constant nature, can often be safely eliminated without loss of explanatory power.
- Filtering Based on Low Correlation with the Response Variable: A key indicator of a feature’s utility is its statistical correlation with the outcome variable of interest. Features showing weak or negligible correlation are unlikely to be powerful predictors in a complex model and are prime candidates for exclusion, as their inclusion primarily contributes to the dimensional strain.
- Employing Wrapper Methods (e.g., Recursive Feature Elimination): More sophisticated techniques involve iteratively training the model on subsets of features, rigorously evaluating performance using cross-validation, and systematically removing the least important features until an optimal, reduced subset is found.
Method 2: Regularization Methods in Modeling
A powerful alternative, especially useful when maintaining the interpretability of original features is desired, involves incorporating penalty terms directly into the model training objective function. This approach, known as Regularization, constrains the magnitude of the model coefficients, thereby stabilizing the model estimates and preventing the extreme overfitting caused by unstable estimates in high-dimensional settings.
Regularization methods are critical when $p gg N$ because they effectively shrink the coefficients of less important variables toward zero, mitigating the influence of noise and collinearity. While they do not explicitly drop features in all cases, they achieve a similar effect by rendering many features non-contributory to the final prediction, ensuring model parsimony and improved generalization.
Key regularization techniques commonly applied to high-dimensional data include:
- Ridge Regression (L2 Regularization): Adds a penalty proportional to the square of the magnitude of the coefficients. This shrinkage process improves model stability and reduces variance but generally does not drive coefficients to absolute zero.
- Lasso Regression (L1 Regularization): Adds a penalty proportional to the absolute value of the coefficients. Crucially, the Lasso penalty often forces the coefficients of irrelevant features to exactly zero, effectively performing simultaneous model fitting and automated feature selection.
- Elastic Net Regularization: A robust hybrid method that combines both L1 (Lasso) and L2 (Ridge) penalties. This approach is highly effective in scenarios where there are groups of highly correlated features, offering the best balance of coefficient stability and feature sparsity.
Method 3: Advanced Dimensionality Reduction
Instead of merely selecting a subset of existing features (feature selection), dimensionality reduction aims to create an entirely new, smaller set of features (or components) that are combinations of the original variables. These components are mathematically derived to capture the highest variance within the data, effectively projecting the high-dimensional data onto a low-dimensional subspace where the Curse of Dimensionality is less severe.
The most widely used linear technique is Principal Component Analysis (PCA), which identifies orthogonal directions (principal components) that maximize the variance explained. PCA is invaluable for reducing noise and transforming correlated features into a smaller set of uncorrelated features. For situations requiring non-linear structure preservation, techniques such as t-distributed Stochastic Neighbor Embedding (t-SNE) or Uniform Manifold Approximation and Projection (UMAP) are utilized, primarily for visualization purposes, as they excel at preserving local data structure when reducing dimensions dramatically.
For comprehensive instruction and practical guides on implementing these dimensionality management techniques and other advanced topics in statistical learning, you can find a complete list of all machine learning tutorials on arabpsychology on the main tutorial index.
Cite this article
stats writer (2025). What is High Dimensional Data?. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-high-dimensional-data/
stats writer. "What is High Dimensional Data?." PSYCHOLOGICAL SCALES, 10 Dec. 2025, https://scales.arabpsychology.com/stats/what-is-high-dimensional-data/.
stats writer. "What is High Dimensional Data?." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/what-is-high-dimensional-data/.
stats writer (2025) 'What is High Dimensional Data?', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-high-dimensional-data/.
[1] stats writer, "What is High Dimensional Data?," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. What is High Dimensional Data?. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.