Table of Contents
High dimensional data refers to data sets that contain a large number of variables or features, making it difficult to visualize and analyze. This type of data is commonly found in fields such as genetics, finance, and marketing, where there are numerous factors that can influence the outcome. Examples of high dimensional data include DNA sequences, financial market data, and customer behavior data. Due to the complexity and size of high dimensional data, specialized techniques and algorithms are often required to extract meaningful insights and patterns.
What is High Dimensional Data? (Definition & Examples)
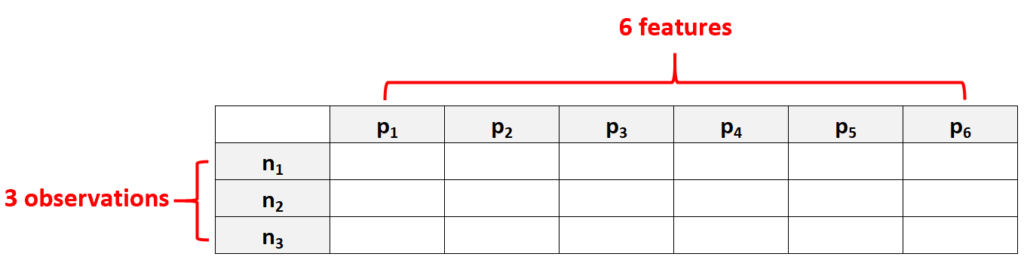
High dimensional data refers to a dataset in which the number of features p is larger than the number of N, often written as p >> N.
For example, a dataset that has p = 6 features and only N = 3 observations would be considered high dimensional data because the number of features is larger than the number of observations.

One common mistake people make is assuming that “high dimensional data” simply means a dataset that has a lot of features. However, that’s incorrect. A dataset could have 10,000 features, but if it has 100,000 observations then it’s not high dimensional.
Note: Refer to Chapter 18 in for a deep dive into the math underlying high dimensional data.
Why is High Dimensional Data a Problem?
When the number of features in a dataset exceeds the number of observations, we will never have a deterministic answer.
In other words, it becomes impossible to find a model that can describe the relationship between the predictor variables and the because we don’t have enough observations to train the model on.
Examples of High Dimensional Data
The following examples illustrate high dimensional datasets in different fields.
Example 1: Healthcare Data
High dimensional data is common in healthcare datasets where the number of features for a given individual can be massive (i.e. blood pressure, resting heart rate, immune system status, surgery history, height, weight, existing conditions, etc.).
In these datasets, it’s common for the number of features to be larger than the number of observations.

Example 2: Financial Data
High dimensional data is also common in financial datasets where the number of features for a given stock can be quite large (i.e. PE Ratio, Market Cap, Trading Volume, Dividend Rate, etc.)
In these types of dataset, it’s common for the number of features to be much greater than the number of individual stocks.

Example 3: Genomics
High dimensional data also occurs often in the field of genomics where the number of gene features for a given individual can be massive.

How to Handle High Dimensional Data
There are two common ways to deal with high dimensional data:
1. Choose to include fewer features.
The most obvious way to avoid dealing with high dimensional data is to simply include fewer features in the dataset.
There are several ways to decide which features to drop from a dataset, including:
- Drop features with many missing values: If a given column in a dataset has a lot of missing values, you may be able to drop it completely without losing much information.
- Drop features with low variance: If a given column in a dataset has values that change very little, you may be able to drop it since it’s unlikely to offer as much useful information about a response variable compared to other features.
- Drop features with low correlation with the response variable: If a certain feature is not highly correlated with the response variable of interest, you can likely drop it from the dataset since it’s unlikely to be a useful feature in a model.
2. Use a regularization method.
Another way to handle high dimensional data without dropping features from the dataset is to use a regularization technique such as:
Each of these techniques can be used to effectively deal with high dimensional data.
You can find a complete list of all machine learning tutorials on Statology on .
Cite this article
stats writer (2024). What is High Dimensional Data? (Definition & Examples). PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-high-dimensional-data-definition-examples/
stats writer. "What is High Dimensional Data? (Definition & Examples)." PSYCHOLOGICAL SCALES, 25 Apr. 2024, https://scales.arabpsychology.com/stats/what-is-high-dimensional-data-definition-examples/.
stats writer. "What is High Dimensional Data? (Definition & Examples)." PSYCHOLOGICAL SCALES, 2024. https://scales.arabpsychology.com/stats/what-is-high-dimensional-data-definition-examples/.
stats writer (2024) 'What is High Dimensional Data? (Definition & Examples)', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-high-dimensional-data-definition-examples/.
[1] stats writer, "What is High Dimensional Data? (Definition & Examples)," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, April, 2024.
stats writer. What is High Dimensional Data? (Definition & Examples). PSYCHOLOGICAL SCALES. 2024;vol(issue):pages.