Table of Contents
The Fundamental Role of Linear Regression in Statistical Modeling
Linear regression serves as a cornerstone of predictive analytics and statistical inference, providing a robust framework for modeling the relationship between a dependent variable and one or more independent variables. By quantifying how changes in a predictor variable influence a response variable, researchers and data scientists can uncover trends, make forecasts, and establish causal links within complex datasets. However, the mathematical validity of a linear regression model is not guaranteed simply by fitting a line to data points. Instead, the reliability of the model’s coefficients and its predictive power depends heavily on a set of core underlying assumptions that must be rigorously tested and verified.
The primary goal of regression analysis is to produce the Best Linear Unbiased Estimator, a concept often referred to in statistics as the Gauss-Markov theorem. When the four key assumptions of linear regression are met, the resulting model provides estimates that are unbiased and have the minimum possible variance. Conversely, if these assumptions are violated, the standard error of the coefficients may be underestimated or overestimated, leading to incorrect p-values and misleading conclusions about the statistical significance of the predictors. Therefore, understanding these prerequisites is essential for any rigorous data analysis workflow.
In this comprehensive guide, we will explore the four foundational assumptions: linearity, independence, homoscedasticity, and normality. We will discuss why each is critical for the integrity of the model, how to diagnose potential violations using visual and statistical tools, and the specific corrective measures that can be taken when a model fails to meet these standards. By adhering to these principles, analysts ensure that their findings are not only mathematically sound but also practically applicable in real-world scenarios, ranging from economics and social sciences to engineering and medical research.
Assumption 1: Establishing a Linear Relationship
The first and perhaps most intuitive assumption of simple linear regression is that the relationship between the independent variable (typically denoted as X) and the dependent variable (Y) is linear. This implies that the rate of change in Y remains constant for every unit increase in X, which can be expressed mathematically through a straight-line equation. If the true relationship in the population is non-linear, a linear model will fail to capture the underlying pattern, resulting in a poor fit and inaccurate predictions that do not reflect the reality of the data generating process.
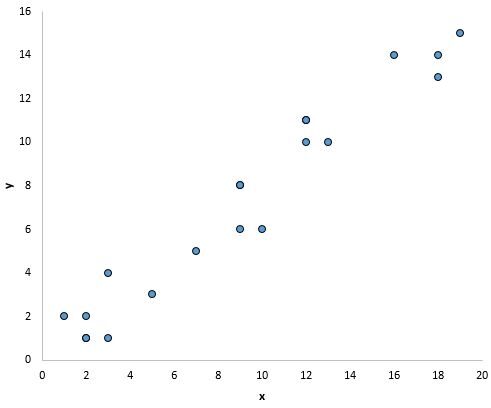
Detecting a violation of this assumption is most effectively achieved through visual inspection. By creating a scatter plot of the variables, an analyst can quickly identify whether the data points follow a linear trend or exhibit more complex curvature. In a well-behaved linear model, the points should appear to cluster around a straight trajectory. If the scatter plot reveals a clear curve, such as a parabolic or exponential shape, it is a definitive signal that a standard linear approach is insufficient and that the model must be adapted to account for the non-linear dynamics present in the dataset.

Consider the visualization above, which demonstrates a scenario where the linearity assumption is satisfied. The data points follow a discernible straight path, suggesting that a linear equation can accurately summarize the interaction between the two variables. In such cases, the residuals—the differences between the observed values and the values predicted by the model—will be randomly distributed around the regression line, indicating that the model has captured the essential information within the data.

Conversely, the plot above illustrates a lack of a clear linear trend. When the relationship is weak or non-existent, the scatter plot appears as a random cloud of points with no specific orientation. In more problematic cases, as shown in the subsequent image, the relationship may be strong but distinctly non-linear. For example, a “U-shaped” distribution suggests that the effect of the independent variable changes direction at a certain threshold, a phenomenon that a simple linear model is fundamentally incapable of representing without modification.

When the linearity assumption is violated, analysts have several powerful remedies at their disposal. One common approach is to apply a logarithmic transformation or a square root transformation to the variables, which can often linearize an exponential or multiplicative relationship. Alternatively, one might transition to polynomial regression, adding squared or cubed terms to the model to account for curvature. These adjustments allow the regression framework to maintain its predictive utility even when the raw data does not conform to a strictly linear path.
Assumption 2: Independence of Residuals
The second assumption requires that the residuals (or error terms) are independent of one another. This means that the error associated with one observation should not provide any information about the error associated with any other observation. This assumption is particularly crucial when analyzing time series data, where observations are collected sequentially over time. If the residuals are not independent, the model suffers from autocorrelation, which can severely distort the results of hypothesis tests and lead to overconfident conclusions about the model’s accuracy.
In the context of time-ordered data, autocorrelation often manifests as a pattern where positive errors are followed by more positive errors, or negative errors by more negative errors. This phenomenon, known as positive serial correlation, typically results in an underestimation of the standard error of the coefficients. As a result, the model may report that certain variables are statistically significant when they are actually just reflecting the temporal structure of the noise. Identifying this issue requires checking the residuals for patterns that correlate with the order of data collection.
To determine if this assumption is met, researchers often utilize the Durbin-Watson test, a statistical measure specifically designed to detect the presence of autocorrelation at lag 1. A value near 2.0 indicates no significant autocorrelation, while values significantly lower than 2.0 suggest positive correlation and values toward 4.0 suggest negative correlation. Visual diagnostics, such as plotting the residuals against time or using an Autocorrelation Function (ACF) plot, are also invaluable for identifying more complex patterns that might not be captured by a single test statistic.
If the independence assumption is violated, the model’s structure must be revised to incorporate the dependency between observations. For time series data, this might involve adding lagged versions of the dependent or independent variables as new predictors, which explicitly models the temporal relationship. In other cases, using generalized least squares (GLS) or incorporating seasonal dummy variables can help account for the structured nature of the errors, ensuring that the final estimates are robust and valid.
Assumption 3: The Importance of Homoscedasticity
The third assumption, known as homoscedasticity, dictates that the variance of the residuals must remain constant across all levels of the independent variables. In simpler terms, the “noise” or uncertainty in the model should be uniform throughout the entire range of data. When the spread of the residuals changes as the value of the independent variable increases or decreases, the data is said to exhibit heteroscedasticity. This violation is problematic because it invalidates the standard formulas used to calculate the variance of the regression coefficients, leading to unreliable confidence intervals.
Heteroscedasticity is frequently encountered in financial and demographic data. For instance, if one were to model the relationship between annual income and discretionary spending, they would likely find that low-income individuals have very similar spending habits due to budget constraints, while high-income individuals exhibit much wider variation in their spending. This increasing variance creates a distinctive “fan” or “cone” shape when the residuals are plotted against the fitted values, signaling that the model’s predictive precision is not consistent across the population.

The visualization above provides a clear example of heteroscedasticity in action. As the fitted values on the x-axis increase, the vertical spread of the residuals on the y-axis expands significantly. This pattern indicates that the model is more accurate for smaller values and becomes progressively less reliable as the values grow. Below, the same data is shown with a conceptual “cone” overlay to highlight the increasing variance that violates the homoscedasticity assumption.

To address heteroscedasticity, analysts often turn to weighted least squares (WLS) regression. In this approach, data points with higher variance are given less weight in the estimation process, effectively minimizing their disruptive impact on the model. Another common strategy is to redefine the dependent variable, such as by using a per-capita rate instead of a raw count, or applying a logarithmic transformation to compress the scale of the data and stabilize the variance. These techniques ensure that the regression model remains a valid tool for inference even in the presence of non-constant error variance.
Assumption 4: Normality of Residuals
The fourth and final assumption is that the residuals of the model follow a normal distribution. This assumption is particularly vital for performing hypothesis tests and constructing confidence intervals, as these procedures are based on the properties of the bell-shaped curve. If the residuals are heavily skewed or have extreme outliers, the resulting p-values may be inaccurate, leading the researcher to make incorrect claims about the significance of their findings.
It is important to clarify that linear regression does not require the independent or dependent variables themselves to be normally distributed; rather, it is the distribution of the errors (the differences between the observed and predicted values) that must be normal. According to the central limit theorem, the normality of residuals becomes less of a concern as the sample size increases. However, for small to moderate datasets, checking for normality remains a critical step in the diagnostic process to ensure the integrity of the statistical tests.
The most common diagnostic tool for this assumption is the Q-Q plot (Quantile-Quantile plot). In a Q-Q plot, the theoretical quantiles of a normal distribution are plotted against the observed quantiles of the residuals. If the residuals are normally distributed, the points will fall roughly along a straight diagonal line. Deviations from this line indicate departures from normality, such as heavy tails (kurtosis) or asymmetry (skewness) in the error distribution.

The Q-Q plot above shows a set of residuals that align closely with the diagonal line, suggesting that the normality assumption has been successfully met. In contrast, the following plot shows residuals that curve away from the line at both ends, indicating that the distribution has “thicker” tails than a normal distribution would suggest. This is a common sign that the model may be influenced by outliers or that the underlying process follows a non-normal distribution, such as a Gamma or Poisson distribution.

When the normality assumption is violated, the first step is often to check the data for influential outliers that might be skewing the results. If the data is accurate but naturally non-normal, non-linear transformations (such as log or square root) can often pull extreme values closer to the mean and normalize the distribution. For more formal verification, analysts may use the Shapiro-Wilk test or the Kolmogorov-Smirnov test, though these are often supplemented with visual Q-Q plots to provide a more holistic view of the model’s health.
Synthesizing the Assumptions for Robust Analysis
In summary, the four assumptions of linear regression—linearity, independence, homoscedasticity, and normality—form the bedrock of sound statistical analysis. Neglecting these checks can lead to models that are visually impressive but mathematically flawed, producing results that do not hold up under scrutiny. By systematically evaluating each assumption through scatter plots, residual analysis, and formal tests, researchers can build more accurate and reliable models that truly represent the relationships within their data.
Adhering to these guidelines not only improves the quality of individual research projects but also contributes to the broader integrity of data-driven decision-making. Whether you are adjusting for heteroscedasticity using weighted regression or transforming variables to achieve linearity, these diagnostic steps are what separate a cursory analysis from a professional statistical study. As you continue to refine your skills in linear regression, always remember that the validity of your output is only as strong as the assumptions upon which it is built.
Further Reading:
Introduction to Simple Linear Regression
Understanding Heteroscedasticity in Regression Analysis
How to Create & Interpret a Q-Q Plot in R
Cite this article
stats writer (2026). How to Verify the Assumptions of Linear Regression. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-are-the-four-assumptions-of-linear-regression/
stats writer. "How to Verify the Assumptions of Linear Regression." PSYCHOLOGICAL SCALES, 5 Mar. 2026, https://scales.arabpsychology.com/stats/what-are-the-four-assumptions-of-linear-regression/.
stats writer. "How to Verify the Assumptions of Linear Regression." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-are-the-four-assumptions-of-linear-regression/.
stats writer (2026) 'How to Verify the Assumptions of Linear Regression', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-are-the-four-assumptions-of-linear-regression/.
[1] stats writer, "How to Verify the Assumptions of Linear Regression," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Verify the Assumptions of Linear Regression. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.