
Table of Contents
In the field of statistics, understanding a dataset requires more than just knowing its central tendency. While metrics like the mean or median indicate the average value, they fail to reveal how individual data points are distributed around that center. This is where measures of dispersion become indispensable.
These crucial statistical calculations quantify the extent of variation or spread within a dataset. By analyzing the degree of scatter, we gain comprehensive insight into the data’s reliability and homogeneity. Key examples of these measures include the range, the interquartile range, variance, and the standard deviation.
A comprehensive analysis of any dataset typically focuses on two primary characteristics:
When conducting thorough data analysis, two characteristics are paramount:
- The location of the central tendency. This is typically measured using metrics such as the mean or median.
- The degree of variability, or how spread out the values are. This spread is quantitatively assessed using the range, interquartile range, variance, and standard deviation.
The Range
The range is arguably the simplest measure of dispersion. It is defined as the difference between the maximum value and the minimum value found within a given dataset. This calculation provides a rapid initial assessment of the data’s span, indicating the total width covered by the observations. While easy to calculate and interpret, the range is highly susceptible to extreme values, often making it a less robust measure compared to other statistics.
Consider the following illustrative dataset, which records the final mathematics exam scores for 20 students. To determine the range, we must first identify the highest and lowest scores.
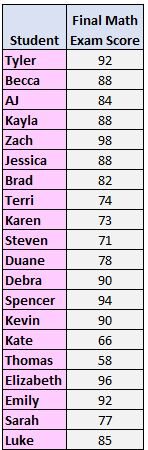
Upon inspection of the scores, the largest value recorded is 98, and the smallest value is 58. Therefore, the calculation of the range is straightforward: 98 minus 58, yielding a result of 40. This means the scores span 40 points from the lowest to the highest mark.
The Interquartile Range (IQR)
The interquartile range (IQR) is a robust measure of statistical dispersion that describes the middle 50% of values when ordered from lowest to highest. Unlike the simple range, the IQR is calculated by finding the difference between the third quartile (Q3) and the first quartile (Q1) of a dataset.
Quartiles are specific values that divide the dataset into four equal parts, or quarters. Q1 marks the 25th percentile, Q2 is the median (50th percentile), and Q3 marks the 75th percentile. The IQR is especially useful as it largely ignores extreme values at the upper and lower ends, providing a clear picture of the concentration of the bulk of the data.
Let us apply this calculation to the same set of 20 exam scores used previously:
To calculate the IQR, we follow a systematic three-step process:
- Order the Dataset. Arrange all 20 scores sequentially from the smallest value to the largest value.
58, 66, 71, 73, 74, 77, 78, 82, 84, 85, 88, 88, 88, 90, 90, 92, 92, 94, 96, 98
- Determine the Median (Q2). Since there are 20 values (an even number), the median is the average of the two middle values (the 10th and 11th values). In this ordered set, the median lies between 85 and 88.
58, 66, 71, 73, 74, 77, 78, 82, 84, 85 | 88, 88, 88, 90, 90, 92, 92, 94, 96, 98. (Median = 86.5)
- Calculate Q1 and Q3. The median effectively divides the data into a lower half and an upper half. The first quartile (Q1) is the median of the lower half, and the third quartile (Q3) is the median of the upper half.
Lower Half: 58, 66, 71, 73, 74, 77, 78, 82, 84, 85
Upper Half: 88, 88, 88, 90, 90, 92, 92, 94, 96, 98
For this specific dataset, Q1 is the average of the middle two values in the lower half (74 and 77), resulting in Q1 = 75.5. Similarly, Q3 is the average of the middle two values in the upper half (90 and 92), resulting in Q3 = 91.
The final interquartile range is determined by subtracting Q1 from Q3: 91 – 75.5, which equals 15.5. This value represents the spread across the central 50% of the exam scores.
Interquartile Range vs. Range: Robustness Against Outliers
The primary advantage of employing the interquartile range over the simple range lies in its inherent resistance to the influence of outliers. An outlier is an observation point that is distant from other observations in a dataset. Since the range relies solely on the two most extreme values (minimum and maximum), a single aberrantly large or small value can drastically inflate the measure, providing a misleading interpretation of the typical data spread.
The IQR, conversely, discards the lowest 25% and the highest 25% of the data, focusing only on the central distribution. This truncation makes the IQR a significantly more stable and reliable metric for assessing variability, especially in skewed distributions or datasets where data quality might be questionable due to potential measurement errors or anomalies.
To demonstrate this effect, consider a hypothetical dataset recording the annual incomes for ten individuals:

In this income data, Person J’s income is clearly an outlier, skewing the overall perception of wealth distribution. When calculating the measures: the range is $2,468,000. However, the interquartile range is only $34,000. The IQR provides a much more accurate indication of the typical spread among the majority of the workers, demonstrating why it is often preferred in financial and socioeconomic analysis.
Understanding Variance (σ²)
The variance (denoted as $sigma^2$ for populations and $s^2$ for samples) is a fundamental measure of dispersion that quantifies how far a set of numbers is spread out from their average value. Specifically, variance calculates the average of the squared differences from the mean. Squaring the differences ensures that negative differences do not cancel out positive ones, and it places more weight on values that are further from the mean, highlighting greater deviations.
Calculating the variance allows statisticians to assess the consistency of the data; a low variance indicates that data points tend to be very close to the mean, while a high variance suggests that data points are spread widely across the distribution.
When dealing with an entire population, the formula for calculating population variance ($sigma^2$) is defined as:
σ2 = Σ (xi – μ)2 / NIn this equation, $mu$ represents the population mean, $x_i$ is the $i^{th}$ element from the population, $N$ is the total population size, and $Sigma$ symbolizes the operation of summation.
However, in practical statistical analysis, researchers typically work with samples rather than the entire population. The calculation of sample variance (denoted as $s^2$) incorporates a subtle but important adjustment known as Bessel’s correction, using $n-1$ in the denominator instead of $N$. This correction is used to provide an unbiased estimate of the true population variance.
The formula for calculating the sample variance ($s^2$) is:
s2 = Σ (xi – $overline{x}$)2 / (n-1)Standard Deviation: The Most Common Metric (σ)
The standard deviation (SD) is the definitive and most frequently used measure of statistical dispersion. It is mathematically defined as the square root of the variance. By taking the square root, the SD returns the measure of variability to the original units of the data, making it far more interpretable than variance itself. For example, if the data measures height in meters, the variance will be in square meters, while the standard deviation will also be in meters.
A low standard deviation suggests that the data points are clustered closely around the mean, indicating high consistency. Conversely, a large standard deviation shows that the data points are widely spread out, suggesting greater variability and perhaps lower predictability. It forms the basis of many inferential statistical tests.
The formula used to find the population standard deviation (denoted as $sigma$) is the square root of the population variance:
√Σ (xi – μ)2 / NSimilarly, the formula for determining the sample standard deviation ($s$) is the square root of the sample variance, retaining the $n-1$ adjustment for unbiased estimation:
√Σ (xi – $overline{x}$)2 / (n-1)Cite this article
stats writer (2026). How to Calculate Measures of Dispersion for Your Data. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-are-measures-of-dispersion/
stats writer. "How to Calculate Measures of Dispersion for Your Data." PSYCHOLOGICAL SCALES, 1 Jan. 2026, https://scales.arabpsychology.com/stats/what-are-measures-of-dispersion/.
stats writer. "How to Calculate Measures of Dispersion for Your Data." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-are-measures-of-dispersion/.
stats writer (2026) 'How to Calculate Measures of Dispersion for Your Data', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-are-measures-of-dispersion/.
[1] stats writer, "How to Calculate Measures of Dispersion for Your Data," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, January, 2026.
stats writer. How to Calculate Measures of Dispersion for Your Data. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.