Table of Contents
The t distribution in Python is an essential tool for statistical inference, particularly when dealing with small sample sizes or when the population standard deviation is unknown. This powerful distribution is frequently employed in complex statistical calculations necessary to determine confidence intervals, execute rigorous hypothesis testing, and compare the means between two or more samples effectively. The primary implementation within the Python ecosystem is achieved through the scipy.stats.t class, which provides a comprehensive suite of methods for distribution analysis. Key functions include t.ppf(), which is used for calculating the Percent Point Function (or inverse CDF), t.cdf() for determining the cumulative distribution function, and t.sf() for calculating the survival function.
Furthermore, researchers commonly leverage the t.interval() method to calculate precise confidence intervals corresponding to a specified probability level and number of degrees of freedom (df). The flexibility and robustness of the t distribution make it a cornerstone of modern inferential statistics implemented in Python, providing reliable results even when the assumption of normality is tenuous due to limited data.
This tutorial serves as a comprehensive guide, detailing the core concepts of the t distribution and demonstrating step-by-step how to utilize its functionalities within the Python programming environment, primarily using the scipy.stats module.
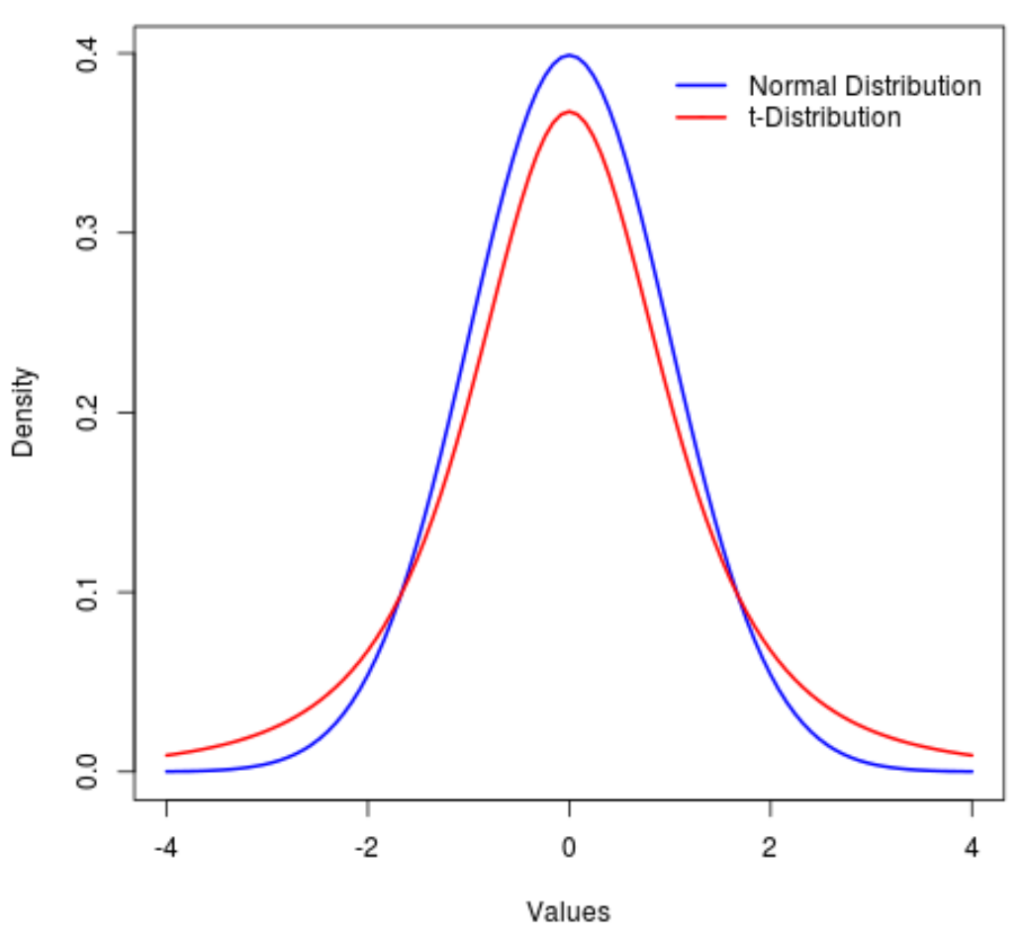
The t distribution, formally known as the Student’s t-distribution, is a critical probability distribution utilized extensively in statistical inference. While fundamentally similar to the standard Normal distribution (or Z-distribution), the t-distribution is distinguished by its characteristic of having significantly heavier “tails.” This difference is crucial, as it accounts for the increased uncertainty inherent when estimating parameters from smaller datasets, leading to a distribution that is more dispersed than the Normal curve.
The practical implication of these heavier tails is that the probability of observing extreme values—those far from the mean—is higher in the t distribution compared to the Normal distribution. This phenomenon is directly tied to the concept of degrees of freedom (df), which dictates the distribution’s shape; as the degrees of freedom increase, the t-distribution gradually converges toward the standard Normal distribution, eventually becoming indistinguishable when $df$ approaches infinity.

This section provides a visual comparison of the Normal distribution versus a t-distribution with limited degrees of freedom, clearly illustrating the difference in density located in the tail ends relative to the center.
Generating Random Variates: The `t.rvs()` Method
To simulate data that conforms to a t distribution, the scipy.stats module provides the efficient t.rvs(df, size) function. This function allows users to generate random variates from the distribution, requiring two critical parameters: the degrees of freedom (df), which defines the specific shape of the distribution, and the desired sample size (size), which determines the number of random values to be returned. This is essential for conducting simulations or generating synthetic data sets that mimic real-world small-sample statistical properties.
Generating random samples is fundamental for various applications, including Monte Carlo simulations, power analysis, and visualizing the distribution’s theoretical shape based on specific parameters. The flexibility of t.rvs() ensures that analysts can easily create datasets tailored to their simulation needs, providing a robust foundation for examining statistical models under different assumptions of uncertainty. This method is the primary way to interact with the stochastic properties of the Student’s t distribution in a computational environment.
The following Python syntax demonstrates how to invoke this method. We specify a degrees of freedom equal to 6 and request an array containing 10 random values, showcasing the simplicity of data generation in scipy:
from scipy.stats import t #generate random values from t distribution with df=6 and sample size=10 t.rvs(df=6, size=10) array([-3.95799716, -0.01099963, -0.55953846, -1.53420055, -1.41775611, -0.45384974, -0.2767931 , -0.40177789, -0.3602592 , 0.38262431])
Upon execution, the resulting output is a NumPy array containing ten floating-point values. These values are statistically drawn from a t distribution defined by six degrees of freedom. Note that due to the random nature of the function, your specific output array will vary slightly from the example provided, but it will always adhere to the same underlying probabilistic rules defined by the distribution parameters.
Calculating Critical Values and P-Values Using `t.cdf()`
A fundamental application of the t distribution in hypothesis testing involves determining the probability of obtaining a test statistic as extreme as, or more extreme than, the observed value—this probability is universally known as the P-value. We leverage the t.cdf(x, df, loc=0, scale=1) function for this purpose, where CDF stands for Cumulative Distribution Function. The CDF calculates the probability that a random variable drawn from the distribution will be less than or equal to a given value ‘x’, which is typically our calculated t-test statistic.
The required parameters for t.cdf() include x (the observed t statistic) and df (the degrees of freedom). The optional parameters, loc (location parameter, usually 0 for the standard t-distribution) and scale (scale parameter, usually 1), are often left at their default values for standard calculations. Understanding the P-value is crucial as it informs the decision-making process regarding the null hypothesis: a small P-value (typically less than a predetermined significance level $alpha$, often 0.05) suggests strong evidence against the null hypothesis, leading to its rejection.
Example 1: Determining a One-Tailed P-Value
Consider a scenario where we are conducting a statistical analysis utilizing a one-tailed t-test. This type of test is used when the research hypothesis specifies the direction of the effect (e.g., testing if the mean is significantly less than a certain value). Suppose our calculations result in an observed t-test statistic of -1.5, and the associated sample size yields degrees of freedom equal to 10. Since we are testing for the probability of observing a value less than or equal to -1.5 (a requirement for a lower one-tailed test), the t.cdf() function directly provides the required P-value, representing the area in the left tail.
When dealing with a negative t-statistic in a lower one-tailed test, the cumulative distribution function simplifies the calculation significantly, as it inherently computes the area from $-infty$ up to the observed t-value. This calculation is vital for determining if the sample mean deviates sufficiently far in the hypothesized negative direction to warrant rejecting the null hypothesis.
The following code snippet demonstrates the straightforward calculation of the one-tailed P-value using the defined parameters:
from scipy.stats import t #calculate p-value for t = -1.5 with df = 10 (left tail) t.cdf(x=-1.5, df=10) 0.08225366322272008
The resulting one-tailed P-value that corresponds to a t test statistic of -1.5 with 10 degrees of freedom is calculated to be approximately 0.0823. If we were using the conventional significance level ($alpha$) of 0.05, we would not reject the null hypothesis, as 0.0823 is greater than the critical threshold of 0.05, indicating insufficient evidence for the hypothesized effect.
Example 2: Calculating the Two-Tailed P-Value
In contrast to the previous example, a two-tailed t-test is employed when we are interested in detecting whether the population parameter is simply different from a specific value, without making assumptions about the direction of the difference (i.e., mean is not equal to a value). Here, the rejection region is split equally between both the upper and lower tails of the t distribution. Assume we conduct such a test and observe a positive t-test statistic of 2.14, with 20 degrees of freedom.
To find the two-tailed P-value, we must calculate the probability of observing a value as extreme as 2.14 in either the upper tail (values $geq 2.14$) or the corresponding extreme value in the lower tail (values $leq -2.14$). Since the t distribution is symmetric around zero, we calculate the probability in one tail (the upper tail, using $1 – text{CDF}$) and multiply it by two. This ensures that we capture the total probability of observing an effect of that magnitude, regardless of its direction.
The methodology for calculating the two-tailed P-value is demonstrated below, where we compute the area in the right tail (the region beyond $x=2.14$) and double the result:
from scipy.stats import t #calculate p-value: (Area in Right Tail) * 2 (1 - t.cdf(x=2.14, df=20)) * 2 0.04486555082549959
The calculated two-tailed P-value is 0.0449. If this analysis were conducted at the conventional $alpha=0.05$ level, we would conclude that there is sufficient statistical evidence to reject the null hypothesis, as 0.0449 is less than 0.05. Note: You can double check these answers by using an online t-statistic calculator or by referencing a standardized t-distribution table. For example, t.sf(x=2.14, df=20) * 2 is an equivalent, often cleaner, way to compute the two-tailed probability, utilizing the survival function directly.
Visualizing the t Distribution using Python Libraries
Visualizing the shape of the t distribution is crucial for gaining intuitive insight into how the degrees of freedom affect its spread and tail behavior. Python offers excellent tools, such as the widely used Matplotlib library, for generating clear and informative plots. The process begins by generating a large sample of random variates using t.rvs(), which provides the necessary data points to construct a histogram or density plot representing the distribution.
The following code snippet demonstrates the generation of 10,000 random values from a t-distribution with 12 degrees of freedom, followed by the creation of a standardized histogram. Using density=True ensures that the y-axis represents probability density, making the histogram comparable to the theoretical probability density function (PDF). The use of bins helps define the resolution of the visualization, clearly outlining the bell shape characteristic of the distribution:
from scipy.stats import t import matplotlib.pyplot as plt #generate t distribution with sample size 10000 and 12 df x = t.rvs(df=12, size=10000) #create plot of t distribution using a histogram plt.hist(x, density=True, edgecolor='black', bins=20)

Alternatively, for creating a smoother, non-parametric visualization known as a Kernel Density Estimate (KDE) plot, analysts often prefer using the powerful Seaborn visualization package. Seaborn, built atop Matplotlib, provides simplified functions for drawing aesthetically pleasing statistical graphics, making the process of generating a density curve extremely efficient and often cleaner than a raw histogram, particularly for theoretical comparisons.
import seaborn as sns #create density curve based on the previously generated variable 'x' sns.kdeplot(x)

Further Applications of the t Distribution in Data Science
Beyond the fundamental calculations of P-values and basic plotting, the t distribution underpins several advanced statistical methodologies critical in data science. One significant application is the calculation of confidence intervals for sample means when the population variance is unknown. The t.interval(confidence, df) function in scipy.stats provides the exact bounds for these intervals, ensuring robust estimation even with limited data by incorporating the added uncertainty reflected by the heavy tails of the distribution when degrees of freedom are low.
Furthermore, the t-distribution is central to performing regression analysis. Specifically, it is used to test the significance of individual regression coefficients, determining whether a predictor variable has a statistically meaningful relationship with the response variable. The t-test statistic calculated for each coefficient is evaluated against the t-distribution with $n-k-1$ degrees of freedom (where $n$ is the sample size and $k$ is the number of predictors), allowing analysts to discard non-significant variables and build parsimonious models. This application ensures that modeling conclusions are statistically sound.
Mastering the use of the scipy.stats.t class, encompassing functions like t.ppf() for finding critical t-values (which define the boundaries of confidence intervals) and t.interval(), empowers the user to perform comprehensive statistical inference that accurately accounts for sample variability and uncertainty in real-world data analysis tasks.
For those seeking to deepen their understanding of related concepts, the following resources offer additional information about the t distribution and its practical applications in statistical modeling:
Cite this article
stats writer (2025). How to Perform t-Tests and Calculate Confidence Intervals Using Python. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-use-the-t-distribution-in-python/
stats writer. "How to Perform t-Tests and Calculate Confidence Intervals Using Python." PSYCHOLOGICAL SCALES, 3 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-use-the-t-distribution-in-python/.
stats writer. "How to Perform t-Tests and Calculate Confidence Intervals Using Python." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-use-the-t-distribution-in-python/.
stats writer (2025) 'How to Perform t-Tests and Calculate Confidence Intervals Using Python', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-use-the-t-distribution-in-python/.
[1] stats writer, "How to Perform t-Tests and Calculate Confidence Intervals Using Python," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Perform t-Tests and Calculate Confidence Intervals Using Python. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.