Table of Contents
Microsoft Excel remains one of the most widely utilized tools globally for data management and fundamental statistical operations. While specialized statistical software often handles complex modeling, Excel possesses powerful native functions that allow users to perform advanced techniques, such as predictive analysis using multiple linear regression. This methodology is indispensable for forecasting outcomes based on the interaction of several input variables. Understanding how to leverage Excel for this purpose transforms raw data into actionable insights, providing a competitive edge in decision-making processes.
The core process involves three critical steps: preparing a structured dataset, employing Excel’s built-in formulas—specifically the powerful LINEST array function—to derive the regression equation, and subsequently applying this equation to new data points for prediction. This rigorous approach moves beyond simple data entry, requiring careful calculation of correlations, identification of key predictor variables, and finally, formulation of a robust linear model. Furthermore, Excel facilitates the creation of detailed visualizations, allowing for comprehensive data analysis and trend monitoring, which are crucial components of effective regression analysis.
This guide provides a comprehensive, step-by-step walkthrough demonstrating how to fit a multiple linear regression model in Excel and use it effectively to forecast response values for new observations or future data points. While the example uses a simulated dataset for clarity, the principles apply universally to real-world business, scientific, or financial data, offering a powerful method for estimating unknown outcomes based on established relationships between variables.
Understanding Multiple Linear Regression Principles
Before diving into the Excel mechanics, it is beneficial to grasp the fundamental concept of multiple linear regression (MLR). MLR is an extension of simple linear regression, designed to model the linear relationship between a response variable (Y) and two or more predictor variables (X1, X2, X3, etc.). The goal is to estimate the best-fit line (or hyperplane in higher dimensions) that minimizes the sum of squared errors between the predicted values and the actual observed values.
The mathematical representation of a MLR model is expressed as: Y = β0 + β1X1 + β2X2 + … + βnXn + ε. Here, Y represents the dependent variable (the outcome we wish to predict); X1 through Xn are the independent or predictor variables; β0 is the intercept (the predicted value of Y when all X variables are zero); β1 through βn are the regression coefficients, which quantify the change in Y for a one-unit change in the corresponding X, holding all other predictors constant; and ε represents the error term.
Successfully implementing this model in Excel hinges on accurately calculating these regression coefficients (β values). These coefficients determine the precise weight and direction of the relationship between each predictor variable and the outcome variable. Once these coefficients are calculated using Excel’s statistical functions, the resulting equation serves as the predictive model, ready to accept new input values to generate forecasts.
Step 1: Preparing Your Dataset in Excel
The first crucial step in any regression analysis is the meticulous preparation and entry of the data. For multiple linear regression, the data must be organized into distinct columns, where one column represents the dependent (response) variable (Y), and the subsequent columns represent the independent (predictor) variables (X1, X2, X3, etc.). Consistency and accuracy in data entry are paramount, as errors at this stage will propagate throughout the model fitting process, leading to unreliable predictions.
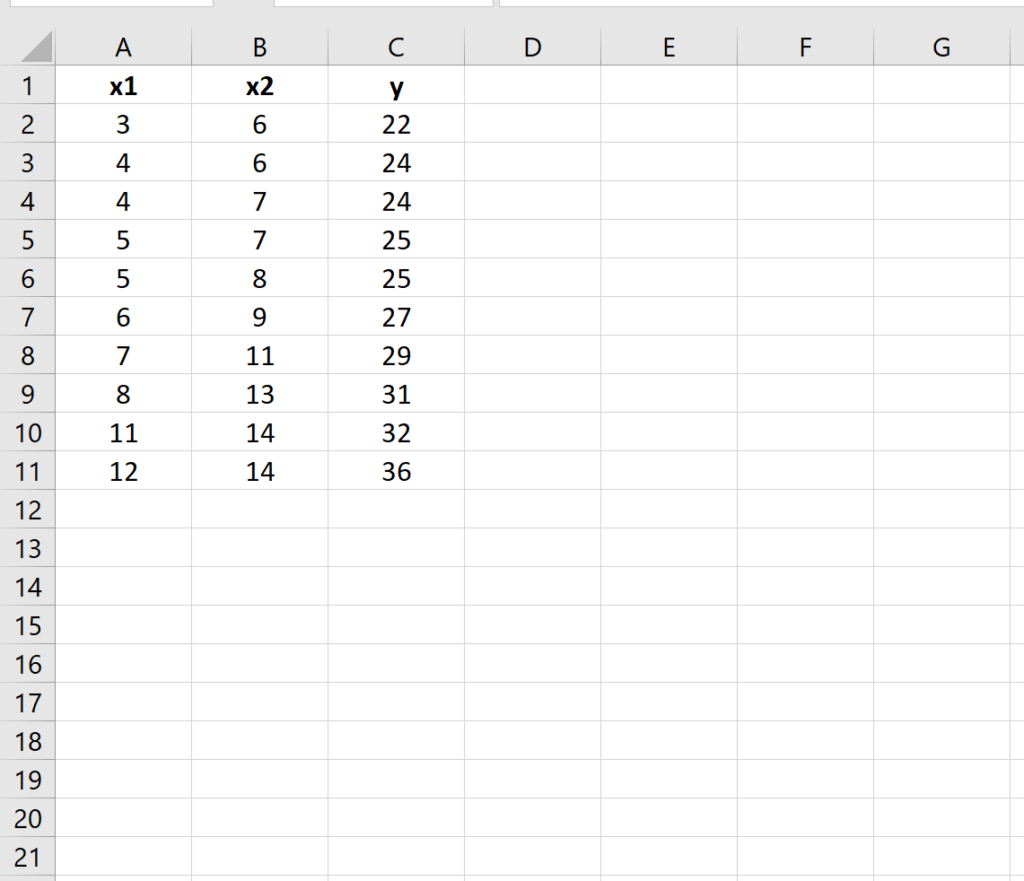
To illustrate this process, we will establish a fictitious dataset containing two predictor variables, X1 and X2, and one response variable, Y. This setup mimics a common scenario where an outcome (Y) is influenced by two measurable factors (X1 and X2). Ensure your data is contiguous and labeled clearly in the top row for easy reference.
For our example, we create the following simulated data table in Excel, which serves as the training data for our predictive model:

A key consideration during data preparation is ensuring that the data meets the assumptions of linear regression, such as linearity, independence of errors, and homoscedasticity. While Excel’s primary calculation functions do not automatically validate these assumptions, the quality of your input data directly impacts the validity of the final predictive model.
Step 2: Executing the LINEST Function for Model Fitting
Fitting the multiple linear regression model in Excel is achieved using the powerful LINEST (Linear Estimate) function. This function returns an array of values describing the regression line, including the crucial regression coefficients and the intercept. Because LINEST returns multiple values, it must be entered as an array formula, which is a critical difference from standard Excel formulas.
The syntax for the LINEST function is generally LINEST(known_y’s, known_x’s, [const], [stats]). In our case, the known_y's are the values in the Y column, and the known_x's are the combined ranges for X1 and X2. We will set the optional arguments [const] and [stats] to TRUE, although for simply obtaining the coefficients, the default behavior (TRUE for both) is sufficient. Setting [stats] to TRUE provides additional metrics necessary for rigorous statistical interpretation, such as R-squared and standard errors.
To execute LINEST correctly, you must first select a range of empty cells corresponding to the expected output array. For a multiple linear regression with two predictors, the minimum output array size needed to capture coefficients and the intercept is 1 row by (n+1) columns (where n is the number of predictors). Select a range of three cells horizontally (for the coefficient of X1, coefficient of X2, and the intercept). Then, enter the function:
=LINEST(Y_range, X1_range:X2_range)After typing the formula, instead of just pressing Enter, you must commit the formula as an array formula by pressing Ctrl + Shift + Enter (or Cmd + Shift + Enter on Mac). This action ensures that the function populates the entire selected range with the calculated coefficients.
Using the data created in Step 1, the formula execution looks like this:

Once committed, the crucial regression coefficients appear in the selected cells. Note that LINEST outputs the coefficients in reverse order of how they were entered: the coefficient for the last X variable entered (X2), then the second to last (X1), and finally, the intercept (β0).

Interpreting the Regression Coefficients and Model Equation
The output from the LINEST function provides the essential components needed to construct the predictive equation. Based on the coefficients displayed in the Excel output (1.0183 for X1, 0.3963 for X2, and 17.1159 for the intercept), we can formally define our fitted multiple linear regression model.
The final fitted model equation is:
Y = 17.1159 + 1.0183(X1) + 0.3963(X2)
Interpretation of these values is key to understanding the relationship between the variables. The intercept (17.1159) suggests that if both X1 and X2 were zero, the predicted value of Y would be 17.1159. The coefficient for X1 (1.0183) means that for every one-unit increase in X1, Y is expected to increase by 1.0183 units, assuming X2 is held constant. Similarly, the coefficient for X2 (0.3963) indicates that a one-unit increase in X2 corresponds to a 0.3963 unit increase in Y, holding X1 constant. These interpretations form the basis of the forecasting power of the model.
It is important to remember that these regression coefficients are estimates derived from the sample data. While the LINEST function provides the point estimates, a full statistical analysis would require examining the standard errors and p-values (which can also be obtained from the extended output of LINEST) to determine the statistical significance and reliability of these estimates. For predictive modeling, however, the coefficients themselves are the immediate tools used for forecasting new observations.
Step 3: Performing Single-Observation Prediction
With the regression equation established, the next logical step is to apply this model to predict the response variable (Y) for a new, unseen observation. This involves plugging new values for the predictor variables (X1 and X2) into the derived linear equation. This process is highly valuable in business planning, risk assessment, or scientific hypothesis testing.
Suppose we encounter a new data point where the inputs for the predictors are:
- X1: 8
- X2: 10
To calculate the predicted Y value (Ŷ), we simply substitute these values into our derived equation: Ŷ = 17.1159 + 1.0183(8) + 0.3963(10).
In Excel, this calculation can be implemented directly using cell references to ensure accuracy and ease of adjustment. We designate specific cells for the new X1 and X2 values and then create a formula that multiplies these new inputs by the corresponding regression coefficients and adds the intercept. This method avoids manual calculation errors and ensures that the prediction is dynamically linked to the model coefficients.
The following image illustrates the implementation of the formula in Excel, directly referencing the calculated coefficients and the new input values:

Upon execution, the multiple linear regression model forecasts that the value for Y, given the inputs X1=8 and X2=10, will be 29.22561. This predicted outcome is the best estimate generated by the linear relationship established from the original training dataset.
Step 4: Scaling Predictions for Multiple Observations
While predicting a single value is useful, practical predictive analysis often requires forecasting outcomes for a large batch of new observations simultaneously. To efficiently scale the prediction process in Excel, it is essential to utilize absolute cell references for the regression coefficients and the intercept. Absolute references ensure that when the prediction formula is copied down a column, the input predictor values (X1 and X2) update relative to the row, but the model parameters (the coefficients) remain fixed.
If we want to predict the response value for several new observations, we must structure the formula to maintain constant references to the cells containing the intercept (β0), the coefficient for X1 (β1), and the coefficient for X2 (β2). This is achieved by using the dollar sign ($) before the column letter and row number (e.g., $C$1).
By making absolute cell references to the regression coefficients, we can create a single master formula in the first prediction row and then drag the fill handle down to apply the prediction across an entire list of new X1 and X2 inputs. This technique drastically improves efficiency and maintains the integrity of the model application across the entire prediction set.
The implementation of absolute references, allowing for the easy expansion of predictions across new data, is illustrated below:

This scalable method transforms Excel into a powerful forecasting engine, capable of handling large volumes of data for predictive analysis without resorting to complex programming languages. The resulting predicted Y values can then be easily integrated into dashboards or further analysis.
Advanced Model Validation and Diagnostics
While simply obtaining the predicted values is the immediate goal of forecasting, a truly expert approach requires validating the fitted regression analysis model. When using the LINEST function with the [stats] argument set to TRUE, Excel returns an array of diagnostic statistics essential for validation. This extended output typically spans five rows and n+1 columns (where n is the number of predictor variables).
Key diagnostic statistics returned by the extended LINEST output include the R-squared value, which measures the proportion of the variance in the response variable that is predictable from the predictor variables. A high R-squared value (closer to 1) generally indicates a better fit. Additionally, the standard error of the estimate (or standard error of the Y estimates) provides a measure of the overall accuracy of the prediction. Lower standard errors suggest more precise predictions.
Other critical components are the F statistic and the degrees of freedom, which are used to perform an overall F-test of the model, testing the null hypothesis that all regression coefficients are simultaneously equal to zero. Analyzing these statistics is essential to confirm that the model is statistically significant and not merely fitted by chance. Proper model validation ensures that the forecasts derived from the equation are reliable and trustworthy for critical decision-making.
Leveraging Excel’s Visualization Capabilities
A significant advantage of using Excel for predictive analysis is its robust charting and visualization environment. Although multiple linear regression involves three or more dimensions (one response and multiple predictors), which cannot be plotted on a simple 2D chart, valuable insights can still be gained through strategic visualization.
One effective visualization technique is plotting the actual response values (Y) against the predicted response values (Ŷ). In an ideal, perfectly fitted model, these points would lie perfectly along a 45-degree line. By creating a scatter plot of Y vs. Ŷ, users can visually assess the goodness of fit. Clusters of points far from this diagonal line indicate areas where the model performs poorly, suggesting potential outliers or non-linear relationships that the current model fails to capture.
Furthermore, analyzing residuals—the differences between the actual Y values and the predicted Ŷ values—is crucial. Plotting the residuals against the predicted values helps check key assumptions of linear regression, particularly homoscedasticity (uniform variance of errors). If the residual plot shows a random scatter around zero, the assumption is likely met. If it displays a pattern (e.g., a funnel shape), it indicates heteroscedasticity, suggesting the model may need transformation or reevaluation. Utilizing Excel’s charting tools for these diagnostic plots ensures a thorough model assessment.
Conclusion: Leveraging Excel for Robust Predictive Modeling
Excel provides a surprisingly powerful and accessible platform for executing and utilizing multiple linear regression models for forecasting. By mastering the organization of input data and the application of the LINEST array function, users can derive the precise regression coefficients necessary to build a reliable predictive equation.
The methods outlined—from fitting the model to performing single and scalable predictions—demonstrate how easily complex statistical concepts can be operationalized within a familiar spreadsheet environment. This capability empowers analysts and business professionals to move beyond descriptive statistics and engage in proactive forecasting.
Ultimately, the successful application of multiple linear regression in Excel requires both technical proficiency in using functions like LINEST and a foundational understanding of the statistical theory underlying the model. By combining these skills, Excel users can generate robust and insightful predictions crucial for strategic planning and informed decision-making.
Cite this article
stats writer (2025). How to Easily Perform Predictive Analysis with Multiple Linear Regression in Excel. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-use-excel-for-predictive-analysis-with-multiple-linear-regression/
stats writer. "How to Easily Perform Predictive Analysis with Multiple Linear Regression in Excel." PSYCHOLOGICAL SCALES, 6 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-use-excel-for-predictive-analysis-with-multiple-linear-regression/.
stats writer. "How to Easily Perform Predictive Analysis with Multiple Linear Regression in Excel." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-use-excel-for-predictive-analysis-with-multiple-linear-regression/.
stats writer (2025) 'How to Easily Perform Predictive Analysis with Multiple Linear Regression in Excel', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-use-excel-for-predictive-analysis-with-multiple-linear-regression/.
[1] stats writer, "How to Easily Perform Predictive Analysis with Multiple Linear Regression in Excel," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Perform Predictive Analysis with Multiple Linear Regression in Excel. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.