Table of Contents
Understanding the Theoretical Framework of Two-Way ANOVA
The Two-Way Analysis of Variance, commonly referred to as Two-Way ANOVA, is a sophisticated statistical method utilized to examine the influence of two distinct categorical independent variables on a single continuous dependent variable. Unlike a One-Way ANOVA, which evaluates only one factor, the two-way approach allows researchers to observe the individual impact of each factor—known as main effects—and, perhaps more importantly, the combined impact of these factors, referred to as the interaction effect. This interaction is critical because it reveals whether the effect of one independent variable changes depending on the level of the second independent variable, providing a more nuanced understanding of complex data relationships.
In the realm of quantitative research, SPSS (Statistical Package for the Social Sciences) serves as a primary tool for conducting these analyses due to its robust General Linear Model (GLM) engine. By employing SPSS, researchers can efficiently manage large datasets and generate comprehensive outputs that include F-statistics, p-values, and measures of effect size. Understanding the mechanics of this test is essential for professionals in fields such as psychology, medicine, and business, where multiple factors often converge to influence a specific outcome, necessitating a clear distinction between isolated and combined influences.
Before executing the test, it is imperative to ensure that the data meets certain statistical assumptions to maintain the validity of the results. These include the normality of the distribution within groups, the independence of observations, and the homogeneity of variances, often tested via Levene’s Test. If these assumptions are violated, the resulting statistical significance may be misleading. Consequently, the ANOVA process in SPSS is not merely about clicking buttons but involves a rigorous preparatory phase where data is screened for outliers and structural integrity.
Core Objectives and the Importance of Interaction Effects
The primary objective of a Two-Way ANOVA is to dissect the variability within a dataset and attribute it to specific sources. By partitioning the total variance into components related to each factor and their interaction, the test helps in determining if the observed differences in group means are likely due to chance or represent actual patterns in the population. The null hypothesis for each main effect posits that there is no difference between the levels of that specific factor, while the interaction null hypothesis suggests that the effect of one factor is consistent across all levels of the other.
Interaction effects represent the “it depends” scenario in research. For instance, if a researcher is studying the effect of a drug dosage and the patient’s age on recovery time, a significant interaction would indicate that the drug’s effectiveness varies significantly between younger and older patients. Without the Two-Way ANOVA, such critical insights would be lost in a simpler ANOVA design. Identifying these interactions allows for more targeted interventions and a deeper theoretical understanding of the response variable under investigation.
Furthermore, this statistical test provides a foundation for predictive modeling and decision-making. By identifying which factors are the most influential and how they behave in tandem, organizations can optimize processes, such as determining the best combination of marketing channels and demographic targeting or identifying the most effective environmental conditions for biological growth. The clarity provided by the Two-Way ANOVA output in SPSS is therefore invaluable for translating raw data into actionable intelligence.
The Experimental Scenario: A Botanist’s Case Study
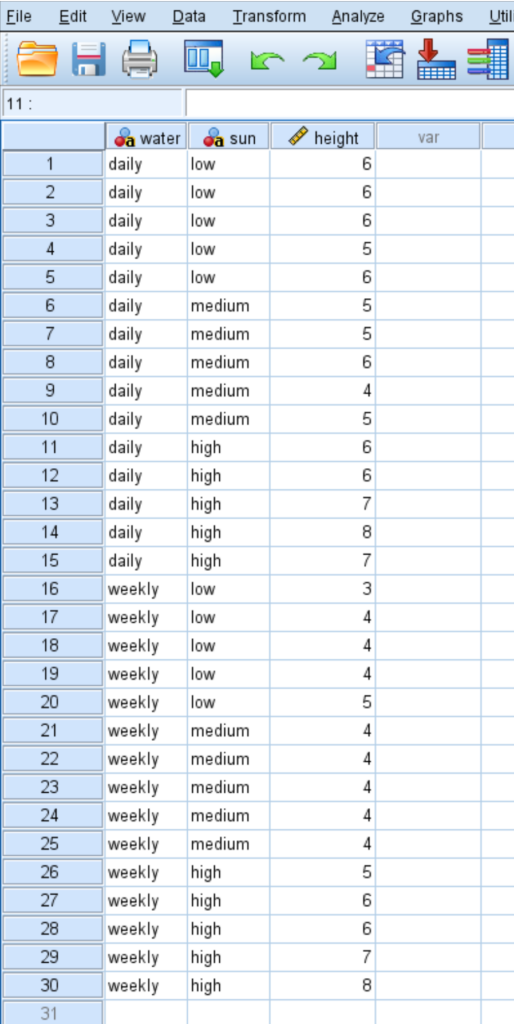
To illustrate the practical application of this test, let us consider a controlled experiment conducted by a botanist. The researcher is interested in determining whether plant growth, measured in inches, is significantly influenced by two primary environmental factors: sunlight exposure and watering frequency. In this study, sunlight exposure is categorized into three levels (Low, Medium, and High), while watering frequency is split into two levels (Daily and Weekly). This creates a 3×2 factorial design, resulting in six distinct treatment groups.
The botanist plants 30 seeds, ensuring they are distributed across these six conditions to maintain a balanced design. Over a period of two months, the plants are carefully monitored, and their final heights are recorded as the dependent variable. This experimental setup is ideal for Two-Way ANOVA because it allows the researcher to ask three distinct questions: Does watering frequency affect growth? Does sunlight exposure affect growth? And does the effect of watering frequency depend on the level of sunlight exposure?
The raw data collected from this experiment serves as the input for our analysis. The following image displays how this data is typically structured within the SPSS Data View, with each row representing an individual plant and each column representing one of the variables (Height, Water, and Sun).

By utilizing the steps outlined in the following sections, we will perform a Two-Way ANOVA to determine the statistical significance of these environmental factors on plant development and identify any underlying interaction patterns that might guide future agricultural practices.
Step 1: Initiating the Univariate Analysis in SPSS
The first step in performing the ANOVA is to navigate the SPSS menu system to access the correct statistical module. Users should click on the Analyze tab located at the top of the interface. From the dropdown menu, select General Linear Model and then choose Univariate. This module is specifically designed for analyzing a single dependent variable across one or more factors, making it the standard choice for the Two-Way ANOVA procedure.
Once the Univariate dialog box opens, the researcher must define the roles of each variable. The continuous measurement—in this case, height—should be dragged into the box labeled Dependent Variable. This is the outcome we are trying to explain. The categorical variables, water and sun, should be moved into the Fixed Factor(s) box. Factors are considered “fixed” when the levels chosen for the study are the only ones of interest to the researcher, which is typical for most experimental designs.
The following screenshots provide a visual guide to navigating these menus and correctly assigning variables within the SPSS environment:


Correct variable assignment is paramount. If a categorical factor is accidentally placed in the Covariate box, SPSS will treat it as a continuous predictor, fundamentally changing the nature of the analysis to an ANCOVA and yielding incorrect results for a factorial experiment. Therefore, double-checking the variable types in the Variable View tab before starting the analysis is a best practice for all statisticians.
Step 2: Visualizing Trends with Profile Plots
While the numerical output of an ANOVA provides the definitive statistical proof, Profile Plots (also known as interaction plots) offer a vital visual representation of how the factors behave together. To generate these, click the Plots button within the Univariate dialog. In the subsequent window, move one factor (e.g., water) to the Horizontal Axis box and the other factor (e.g., sun) to the Separate Lines box. After clicking Add, the term water*sun will appear in the Plots list.
These plots are particularly useful for identifying the presence of an interaction effect. If the lines in the resulting graph are parallel, it suggests that there is no interaction; however, if the lines cross or diverge significantly, it indicates that the impact of watering frequency varies depending on the amount of sunlight. This visual aid simplifies the interpretation for stakeholders who may not be well-versed in p-values or degrees of freedom.
Refer to the image below for the specific configuration required to produce these helpful visualizations:

Once the plot configuration is complete, click Continue to return to the main Univariate window. It is worth noting that while plots are excellent for visualization, they do not replace formal statistical testing. They should always be used in conjunction with the Tests of Between-Subjects Effects table to confirm whether any observed visual patterns are statistically significant.
Step 3: Conducting Post Hoc Analysis with Tukey’s Test
An ANOVA only tells you that at least one group mean is different from the others; it does not specify which groups are different. This is known as an omnibus test. To pinpoint the exact differences between levels of a factor with more than two groups (like sun, which has low, medium, and high levels), we must perform Post Hoc Analysis. The most common and reliable method for this is Tukey’s Honestly Significant Difference (HSD) test.
To set this up in SPSS, click the Post Hoc button. Select the variable sun and move it to the Post Hoc Tests for box. Under the Equal Variances Assumed section, check the box for Tukey. It is important to note that post hoc tests are generally not needed for factors with only two levels (like water), as any significant result for that factor automatically implies a difference between those two specific groups.
The following images illustrate the selection process for post hoc tests and the estimation of marginal means, which provide the adjusted group averages for the final report:


Using Tukey’s test is essential because it controls for the Type I error rate (false positives) when performing multiple pairwise comparisons. Without such a correction, the probability of incorrectly finding a statistically significant result would increase with every additional comparison made. After configuring these settings, click Continue and then OK to run the full analysis.
Step 4: Interpreting the Tests of Between-Subjects Effects
The most critical component of the SPSS output is the Tests of Between-Subjects Effects table. This table summarizes the entire Two-Way ANOVA by providing the sum of squares, mean square, and the F-statistic for each source of variance. However, most researchers focus primarily on the Sig. column, which contains the p-values for the main effects and the interaction.
In our botanist’s example, the output reveals the following p-values:
- Water: p-value = .000
- Sun: p-value = .000
- Water*Sun (Interaction): p-value = .201
By comparing these p-values to a standard alpha level of .05, we can draw significant conclusions. Since the p-value for both water and sun is less than .05, we reject the null hypothesis for both factors, concluding that watering frequency and sunlight exposure each have a statistically significant effect on plant growth. However, because the interaction p-value (.201) is greater than .05, we fail to reject the null hypothesis for the interaction, meaning the effect of sunlight does not significantly depend on the watering schedule.
Review the primary output table below to see where these values are located:

This hierarchy of interpretation is vital: always check the interaction effect first. If the interaction were significant, interpreting the main effects would become more complex, as the impact of one variable would be conditional. Since our interaction is non-significant, we can safely discuss the main effects of water and sunlight as independent drivers of plant height.
Step 5: Analyzing Group Means and Pairwise Comparisons
After establishing that significant differences exist, the next step is to examine the Estimated Marginal Means. This table provides the average height for each level of the independent variables. These means allow the researcher to describe the direction and magnitude of the effects. For example, by looking at the means, we can determine which watering schedule produced the tallest plants and exactly how much taller they were on average compared to the other group.
In the botanist’s study, the following descriptive data was observed:
- The average height for plants watered daily was 5.893 inches.
- The average height for plants with high sunlight exposure was 6.62 inches.
- The specific combination of daily watering and high sunlight resulted in an average height of 6.32 inches.
The detailed breakdown of these means can be seen in the following table from the SPSS output:

While these means provide a good overview, the Post Hoc Test table (specifically the Multiple Comparisons table) is required to determine which levels of sunlight exposure differ from one another. According to the Tukey HSD results, there was a significant difference between High and Low sunlight (p = .000) and between High and Medium sunlight (p = .000). Interestingly, there was no significant difference between Low and Medium sunlight (p = .447), suggesting that a certain threshold of light is required before growth improves significantly.
The image below displays the results of the Tukey post hoc comparisons, which are essential for a detailed results section:

Step 6: Synthesizing and Reporting the Final Results
The final stage of any statistical analysis is the professional reporting of the findings. A well-structured report should include the type of test performed, the variables involved, the statistical significance (including F-statistics and p-values), and a clear interpretation of the results in the context of the research question. It is standard practice to report results using APA style or another relevant academic format.
For the botanist’s study, a comprehensive report might be phrased as follows:
A Two-Way ANOVA was conducted to evaluate the effects of watering frequency (daily vs. weekly) and sunlight exposure (low, medium, high) on plant growth. The analysis utilized a sample of 30 plants. The results indicated that both watering frequency (p < .001) and sunlight exposure (p < .001) had a statistically significant main effect on plant height. Specifically, plants that received daily watering showed significantly greater growth compared to those watered weekly.
Furthermore, Tukey’s HSD post hoc comparisons revealed that plants in the high sunlight condition achieved significantly greater heights than those in both the medium and low sunlight conditions. However, the difference in growth between the medium and low sunlight groups did not reach statistical significance. Crucially, the interaction effect between watering frequency and sunlight exposure was not significant (p = .201), suggesting that the benefits of daily watering are consistent regardless of the level of sunlight provided.
By following this structured approach—from initial data entry in SPSS to the final interpretation of post hoc tests—researchers can ensure their findings are both accurate and easy to communicate. The Two-Way ANOVA remains a cornerstone of experimental research, providing the depth of analysis required to understand the multi-faceted nature of the real world.
Cite this article
stats writer (2026). How to Perform and Interpret a Two-Way ANOVA in SPSS. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-you-perform-a-two-way-anova-in-spss/
stats writer. "How to Perform and Interpret a Two-Way ANOVA in SPSS." PSYCHOLOGICAL SCALES, 15 Mar. 2026, https://scales.arabpsychology.com/stats/how-do-you-perform-a-two-way-anova-in-spss/.
stats writer. "How to Perform and Interpret a Two-Way ANOVA in SPSS." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-do-you-perform-a-two-way-anova-in-spss/.
stats writer (2026) 'How to Perform and Interpret a Two-Way ANOVA in SPSS', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-you-perform-a-two-way-anova-in-spss/.
[1] stats writer, "How to Perform and Interpret a Two-Way ANOVA in SPSS," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Perform and Interpret a Two-Way ANOVA in SPSS. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.