Table of Contents
Introduction to Data Integrity and Duplicate Management in Excel
In the modern era of data-driven decision-making, maintaining the accuracy and reliability of information within a spreadsheet is of paramount importance. When managing large datasets in Microsoft Excel, users frequently encounter the challenge of redundant information, which can lead to skewed results during data analysis. However, the immediate deletion of these duplicates is not always the most prudent course of action. Often, a researcher or analyst needs to identify these values for further investigation while keeping the original data integrity intact. Finding duplicate values without removing them allows for a comprehensive audit trail and ensures that no critical context is lost during the cleaning process.
The primary method for achieving this objective is through the use of the Conditional Formatting engine. This powerful utility within Excel provides a dynamic way to apply visual styles—such as fill colors or font changes—to cells that meet specific criteria. By leveraging this feature, users can create a high-contrast visual map of their data, instantly revealing where repetitions occur across thousands of rows. Unlike manual inspection, which is prone to human error, Conditional Formatting provides a systematic and repeatable approach to data validation. This ensures that every instance of a duplicate is accounted for based on the underlying logic of the software.
Beyond simple identification, keeping duplicates visible is essential for complex tasks like reconciliation or cross-referencing between multiple worksheets. For instance, in financial auditing or inventory management, a duplicate entry might not necessarily indicate an error; it could represent multiple transactions for the same client or recurring stock shipments. By highlighting these values instead of deleting them, professionals can investigate the metadata associated with each entry to determine its validity. This nuanced approach to data management transforms Excel from a basic storage tool into a sophisticated diagnostic platform for organizational efficiency.
The Logic of Identifying Redundant Information
To effectively manage duplicates, one must first understand how Excel defines a “duplicate value.” In technical terms, a duplicate is identified when the exact sequence of characters or numerical values in one cell matches another within a specified cell range. It is important to note that Excel is generally case-insensitive when performing this specific function, meaning “Mavs” and “mavs” would typically be flagged as duplicates. This logic is built into the core calculation engine of the software, allowing for rapid processing even when dealing with Big Data scenarios or complex CSV imports.
When you choose to highlight rather than delete, you are essentially creating a non-destructive layer of information. This layer acts as a Graphical User Interface (GUI) enhancement that guides the human eye toward outliers or patterns. For example, if you are looking at a list of unique identifiers like Social Security Numbers or Product SKUs, any highlight serves as an immediate red flag that requires attention. By preserving the original structure of the table, you maintain the relationship between the duplicate value and its surrounding attributes, such as timestamps, user IDs, or geographic locations, which would be lost if the row were simply purged.
Furthermore, the “Remove Duplicates” feature, while useful for final data cleaning, is a destructive process that can lead to accidental loss of unique information if the wrong columns are selected. By contrast, the Highlight Cell Rules approach is entirely reversible and adjustable. Users can clear the formatting at any time without affecting the underlying data values. This flexibility is critical during the exploratory phase of data science, where the goal is to understand the distribution and frequency of data points before making permanent modifications to the source file.
Utilizing Conditional Formatting for Visual Auditing
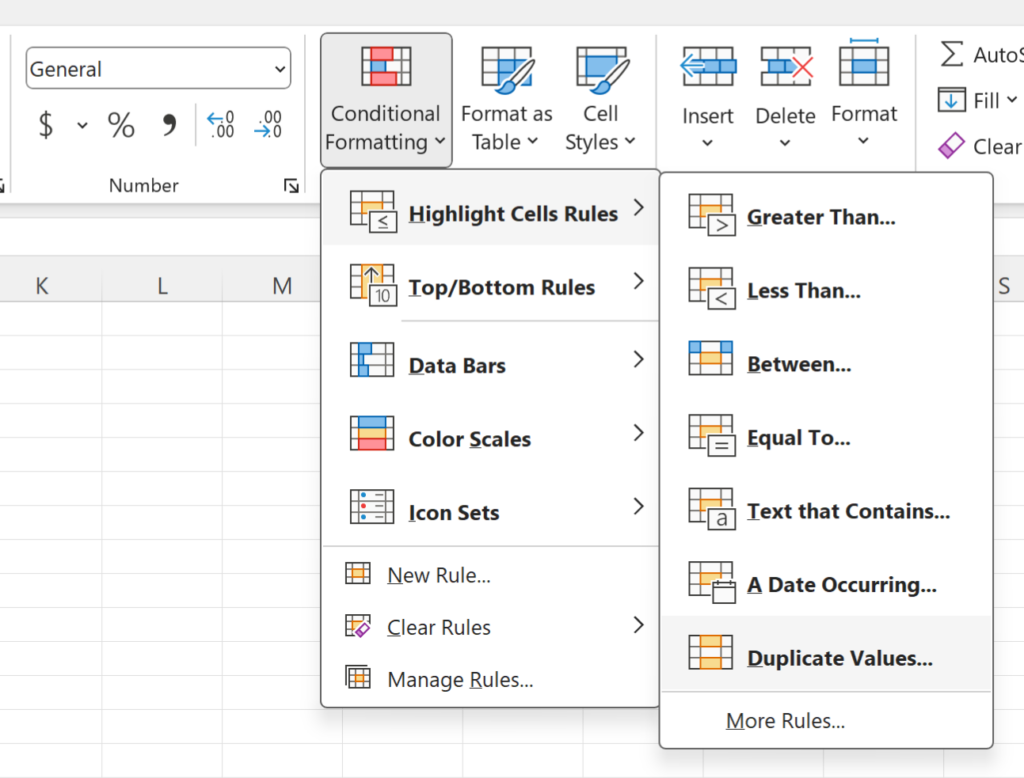
The Conditional Formatting tool is located within the Home tab of the Excel Ribbon, serving as a cornerstone for data visualization. To begin the process of finding duplicates, the user must first define the scope of the search by selecting the relevant cells. This selection can be a single column, a specific row, or an entire table. Once the range is active, navigating to the Highlight Cell Rules sub-menu opens a variety of logical tests, with Duplicate Values being the most direct solution for this specific task.
One of the most significant advantages of this tool is its real-time responsiveness. If the data within the selected range changes—for example, if a user corrects a typo that was causing a duplicate—the highlight will automatically disappear. Conversely, if a new entry is added that matches an existing record, both instances will instantly change color. This dynamic feedback loop is invaluable for collaborative environments where multiple stakeholders may be entering data into a shared Excel workbook simultaneously.
The following example demonstrates the practical application of these steps in a real-world scenario, focusing on a list of basketball teams. By following this structured approach, you can ensure that your Excel workbooks remain organized and that any instances of data redundancy are clearly marked for review.

Practical Demonstration: Highlighting Basketball Team Records
Consider a scenario where an administrator is managing a list of basketball team names in Excel. The objective is to identify which teams appear more than once in the list to ensure the schedule is balanced or to check for registration errors. In this example, the data is housed in a simple vertical list, but the same principles apply regardless of the complexity of the software framework or the size of the dataset.

To identify all duplicate team names without removing them from the spreadsheet, the first step involves highlighting the specific cell range from A2 to A13. This tells Excel exactly where to perform its comparison. After the selection is made, the user should navigate to the Home tab on the top ribbon and select the Conditional Formatting icon. From the resulting dropdown menu, hover over Highlight Cell Rules and then select Duplicate Values. This sequence of commands triggers the software’s internal logic to scan the selected area for identical strings of text.
Once the Duplicate Values option is selected, a new dialog box will appear on the screen. This interface allows the user to fine-tune how the duplicates are displayed. It is important to note that the tool also offers an option to highlight “Unique” values instead, which can be useful in different analytical contexts. For our purposes, we remain focused on the “Duplicate” setting to ensure all recurring team names are brought to the forefront of our visual field.
Configuring Visual Styles and Custom Formatting Rules
In the Duplicate Values window, Excel provides several pre-defined styles to use for the conditional formatting. These styles are designed to provide high contrast, making the flagged data points stand out against the standard white background of the spreadsheet. The default option is typically a Light Red Fill with Dark Red Text, which is the industry standard for indicating items that require attention or potential correction.
Choosing a style is a critical step in the data visualization process. While the default red is effective, users can also choose green or yellow fills, or even create a Custom Format. Custom formatting allows for more granular control, such as changing the border style, bolding the text, or using specific hex codes to match a corporate branding guide. This level of customization ensures that the audit process is not only functional but also aligned with the aesthetic requirements of professional reports.

After selecting the preferred style—in this case, the default light red fill—clicking the OK button applies the rule to the selected range. Excel immediately executes the comparison and updates the User Interface. This instantaneous transformation is one of the reasons why Excel remains the gold standard for information management across various industries.
Analyzing the Outcome and Interpreting Cell Highlights
Once the Conditional Formatting has been applied, the results are immediately visible within the worksheet. The highlighted cells serve as a clear indicator of which data points are repeated. In our basketball team example, we can observe the following results based on the entries in column A:

The visual analysis reveals the following specific insights about our dataset:
- The team name Mavs appears multiple times in the list; consequently, every instance of this name is highlighted in red, allowing the user to see exactly where these repetitions occur.
- Similarly, the team name Warriors is found in more than one cell, triggering the conditional format for each occurrence.
- Conversely, the team name Nuggets appears only once in the entire range, so it remains without any fill color, indicating its status as a unique entry.
By applying this methodology, we have successfully identified every duplicate value in column A without deleting a single row. This allows the user to investigate why the Mavs and Warriors are listed multiple times. Perhaps they have multiple games scheduled, or perhaps there was a clerical error during the data entry phase. Regardless of the reason, the data remains intact for further analysis.
Advanced Filtering and Sorting of Highlighted Data
Identifying duplicates is often just the first step in a more complex workflow. Once the values are highlighted, Excel offers advanced ways to interact with them. For instance, you can use the Filter by Color feature to isolate only the highlighted cells. By clicking the filter arrow in the header row, you can choose to display only the rows with the red fill, effectively creating a temporary view of just the duplicates.
This technique is far superior to manual scrolling, especially in datasets containing tens of thousands of records. Once filtered, you can perform bulk actions on the duplicates, such as adding a note in an adjacent column or assigning them to a specific category. This demonstrates the power of combining Conditional Formatting with Excel’s filtering engine to manage complex data structures efficiently. It provides a level of precision that is essential for high-stakes business intelligence tasks.
Additionally, you can Sort by Color to move all duplicate values to the top of your sheet. This reorganization makes it easier to compare the duplicate rows side-by-side to see if other columns (like dates or amounts) are also identical. This “side-by-side” comparison is a critical part of data cleansing, helping you decide whether a duplicate is a legitimate recurring entry or a mistake that eventually needs to be removed.
Preserving Original Datasets for Comprehensive Reporting
The philosophy of “find but don’t delete” is deeply rooted in the principles of auditable data management. In professional settings, transparency is key. If a supervisor or a client asks why certain data was modified, having a version of the spreadsheet where duplicates are merely highlighted provides a clear visual explanation of the issues found within the original source. It serves as “proof of work” for the data analyst.
Furthermore, keeping the original data allows for the use of Pivot Tables to summarize the frequency of duplicates. Instead of losing the data, you can create a report that shows exactly how many times each team name appears. This type of frequency analysis can reveal underlying patterns, such as system glitches that cause double-posting of transactions or seasonal trends in customer behavior. By retaining the duplicates, you turn a potential data “problem” into a valuable source of business insight.
In conclusion, mastering the Duplicate Values tool within Conditional Formatting is an essential skill for anyone working with Excel. It provides a safe, efficient, and highly visual way to audit information while maintaining the integrity of the original dataset. Whether you are managing sports teams, financial records, or scientific observations, this technique ensures that you remain in full control of your data throughout the entire analytical process.
Further Learning and Excel Optimization Tutorials
The ability to find and highlight duplicates is just one aspect of spreadsheet proficiency. To become truly adept at managing information, it is helpful to explore related functions and features that complement Conditional Formatting. For example, learning how to use the COUNTIF function can provide a numerical count of duplicates, which can then be used to trigger even more complex formatting rules.
The following tutorials and resources provide additional depth into the world of Excel operations and data management. Expanding your knowledge in these areas will help you build more robust, error-free workbooks that can handle the demands of modern data processing. Continuous learning is the key to leveraging the full power of Microsoft 365 and ensuring your data tells a clear, accurate story.
- Advanced Data Validation techniques to prevent duplicates before they are entered.
- Using Power Query for more sophisticated data cleaning and deduplication workflows.
- Mastering Excel Formulas to automate the identification of duplicates across multiple worksheets.
- Creating dynamic dashboards that visually represent data quality metrics.
Cite this article
stats writer (2026). How to Find Duplicate Values in Excel Without Deleting Them. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-find-duplicate-values-in-excel-without-deleting-them/
stats writer. "How to Find Duplicate Values in Excel Without Deleting Them." PSYCHOLOGICAL SCALES, 13 Feb. 2026, https://scales.arabpsychology.com/stats/how-can-i-find-duplicate-values-in-excel-without-deleting-them/.
stats writer. "How to Find Duplicate Values in Excel Without Deleting Them." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-find-duplicate-values-in-excel-without-deleting-them/.
stats writer (2026) 'How to Find Duplicate Values in Excel Without Deleting Them', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-find-duplicate-values-in-excel-without-deleting-them/.
[1] stats writer, "How to Find Duplicate Values in Excel Without Deleting Them," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Find Duplicate Values in Excel Without Deleting Them. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.