Table of Contents
Comprehensive Introduction to ROC Curve Analysis in SPSS
The Receiver Operating Characteristic, or ROC curve, represents one of the most sophisticated tools available to researchers for evaluating the performance of a diagnostic test. Originally developed during World War II for analyzing radar signals, this statistical technique has since become a cornerstone in fields ranging from medical diagnostics to machine learning and sports analytics. In the context of SPSS, creating and interpreting an ROC curve allows users to visualize the trade-off between the true positive rate and the false positive rate across various threshold settings. This visualization is essential when a researcher needs to determine how effectively a model can distinguish between two distinct groups, such as diseased versus healthy patients or, in our specific example, drafted versus non-drafted basketball players.
The fundamental utility of the ROC curve lies in its ability to condense complex predictive accuracy into a single, intuitive graphical representation. By plotting Sensitivity against 1 minus Specificity, researchers can quickly ascertain the discriminatory power of their predictor variable. When utilizing SPSS for this analysis, the software automates the heavy mathematical lifting, providing not only the curve itself but also critical metrics such as the Area Under the Curve (AUC) and detailed coordinate tables. These outputs are vital for any rigorous empirical study that relies on classification accuracy to draw meaningful conclusions from a binary variable.
Before diving into the procedural steps within the software, it is important to understand that the quality of an ROC analysis is directly tied to the quality of the underlying data. The dependent variable must be dichotomous, meaning it has only two possible outcomes, while the test variable is typically continuous or ordinal. This structure ensures that the model can test various “cut-off” points to see which value best separates the two classes. Throughout this guide, we will explore how to navigate the SPSS interface to generate these results and, more importantly, how to translate those statistical outputs into actionable insights for your research or business decisions.
The Statistical Foundation: Logistic Regression and Binary Outcomes
To fully grasp the mechanics of an ROC curve, one must first understand the role of Logistic Regression. This specific statistical method is employed when we aim to model the relationship between one or more independent variables and a categorical response variable that has exactly two categories. Unlike linear regression, which predicts continuous values, logistic regression calculates the probability of an observation belonging to a specific group. This probability is then used as the basis for classification. In our tutorial, we look at the probability of a basketball player being drafted based on their scoring performance in college, a classic application of binary classification.
In any classification model, we are essentially trying to minimize error while maximizing the correct identification of cases. Because the output of a logistic regression model is a probability ranging from 0 to 1, a decision rule or cut-off point must be applied to classify individuals. For instance, if the predicted probability is greater than 0.5, we might classify the player as “Drafted.” However, 0.5 is not always the optimal threshold. The ROC curve is unique because it evaluates every possible threshold, providing a holistic view of the model’s performance rather than focusing on a single, potentially arbitrary, cut-off value. This makes it an indispensable tool for validating the robustness of your statistical models.
When you perform this analysis in SPSS, the software evaluates the relationship between the test variable and the state variable. It is crucial to identify which outcome represents the “positive” state—in our case, the event of being drafted. By accurately defining these parameters, SPSS can generate a model that reflects the real-world utility of your data. This process bridges the gap between raw statistical probability and practical classification, allowing researchers to refine their predictive strategies based on evidence-based metrics rather than mere intuition.
Core Metrics: Defining Sensitivity and Specificity
At the heart of ROC analysis are two critical metrics: Sensitivity and Specificity. These terms are used to describe the accuracy of a classification model in identifying different states. Sensitivity, also known as the True Positive Rate, measures the proportion of actual positive cases that are correctly identified by the model. In our basketball example, sensitivity refers to the probability that the model correctly predicts a player will be drafted when they actually are drafted. A high sensitivity is vital in scenarios where missing a positive case carries a high cost, such as in medical screenings for life-threatening conditions.
On the opposite side of the spectrum is Specificity, or the True Negative Rate. This metric measures the proportion of actual negative cases that are correctly identified. For our dataset, specificity represents the probability that the model correctly identifies a player who will not be drafted. In many practical applications, there is an inherent trade-off between these two values: as you adjust the model to be more sensitive (to catch more positive cases), you often decrease its specificity (increasing the number of false positives). The ROC curve plots these competing interests against each other, with the y-axis representing sensitivity and the x-axis representing 1 minus specificity (the False Positive Rate).
Understanding this relationship is paramount for any researcher. A perfect model would have 100% sensitivity and 100% specificity, appearing as a point in the extreme upper-left corner of the graph. However, real-world data is rarely that clean. Most models fall somewhere along a curve. By analyzing where your model sits on this curve, you can determine the “cost” of increasing sensitivity in terms of lost specificity. This balance is critical for establishing a cut-off point that aligns with the specific goals of your study or organizational requirements.
Data Preparation and Initial Setup in SPSS
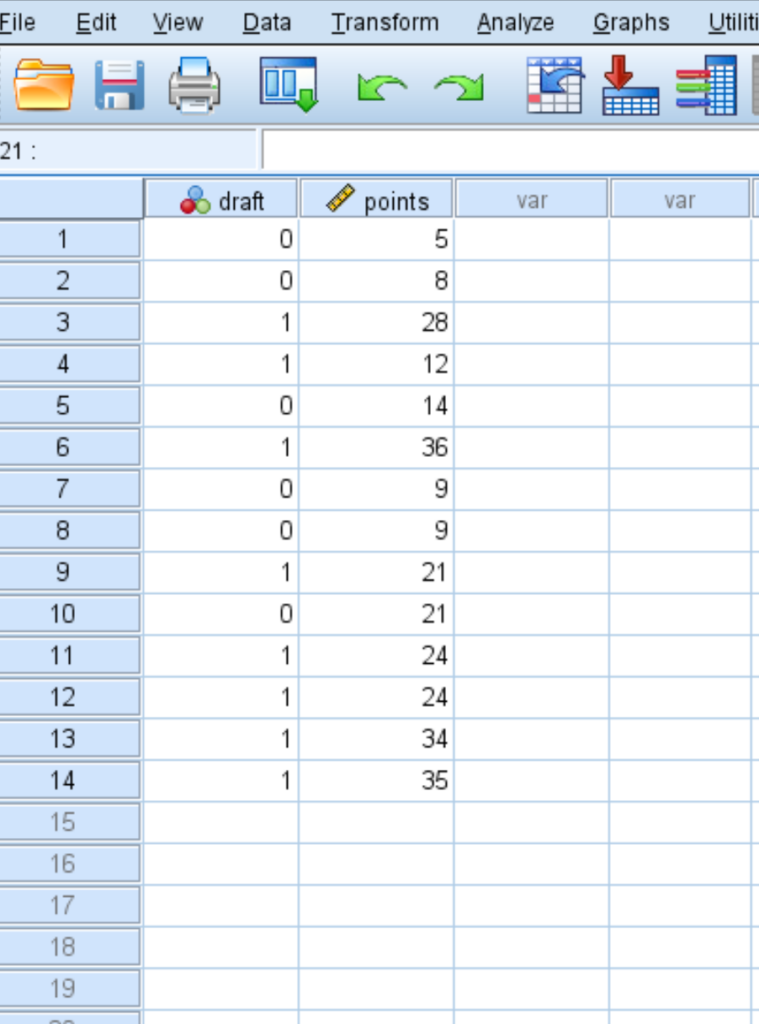
Before generating the curve, the data must be properly formatted within the SPSS environment. Consider a dataset where we track whether basketball players were drafted (the state variable, where 0 equals “no” and 1 equals “yes”) alongside their college points per game (the test variable). This data must be entered into the Data View such that each row represents a unique observation. It is essential that the state variable is coded numerically, as SPSS requires a specific value to define the “positive” outcome for the ROC curve calculation.

Once your data is cleaned and imported, the process of generating the analysis is straightforward. You will need to navigate through the SPSS menu system. Begin by clicking on the Analyze tab located in the top toolbar. From the dropdown menu, hover over Classify and then select the ROC Curve option. This specific path is designed for models where you want to evaluate a single continuous variable’s ability to predict a binary outcome. It is a more direct route than running a full logistic regression if your primary goal is the visualization and validation of a diagnostic test.

After selecting the ROC Curve option, a dialogue box will appear. This is where you define the roles of your variables. You must drag your “points” variable into the box labeled Test Variable and your “draft” variable into the State Variable box. Crucially, you must specify the Value of State Variable. In this context, entering “1” tells SPSS that being drafted is the positive outcome we are attempting to predict. This step ensures that the resulting graph correctly displays the relationship between the predictor and the intended target state.
Configuring Options and Executing the Analysis
To ensure the output is as informative as possible, there are several display options within the ROC Curve dialogue box that should be selected. First, you should check the box for With diagonal reference line. This line represents a model with no predictive power—essentially a 50/50 guess. Comparing your model’s curve to this baseline is the fastest way to judge its effectiveness. Additionally, selecting Coordinate points of the ROC Curve is highly recommended, as it generates a table showing the specific sensitivity and specificity values for every possible threshold in your data.

Once you have configured these settings, clicking OK will prompt SPSS to process the data and generate the output viewer. The software performs a series of calculations, evaluating the cumulative distribution of the test variable for both the positive and negative states. This involves sorting the test variable and calculating the true positive and false positive rates at each unique value. The result is a comprehensive set of tables and a graph that together provide a complete picture of your model’s diagnostic accuracy.
The beauty of the SPSS output is its structured approach to data presentation. By providing the Case Processing Summary, the ROC Curve plot, and the Area Under the Curve table, the software allows for both a visual and a quantitative assessment. This dual approach is essential for modern statistical reporting, as it provides the visual evidence needed for presentations while offering the rigorous numerical backing required for academic publication or technical reports. Ensuring you have checked the correct boxes during setup is the key to unlocking these detailed insights.
Interpreting the Case Processing Summary
The first table you will encounter in the SPSS output is the Case Processing Summary. While it may seem like a simple formality, this table is vital for verifying the integrity of your analysis. It provides the total count of positive and negative cases identified by the software based on the “Value of State Variable” you provided. For our basketball dataset, the table indicates that 8 players were drafted (positive cases) and 6 players were not (negative cases), totaling 14 observations.

Reviewing this summary allows you to ensure that no data was excluded due to missing values and that the group sizes are sufficient for a meaningful analysis. If the number of cases in either the positive or negative group is extremely small, the ROC curve may appear jagged or unstable, which would limit the reliability of your conclusions. In clinical or professional research, checking the N-values in this table is a fundamental step in data validation before proceeding to the more complex parts of the output.
Furthermore, the Case Processing Summary confirms that SPSS has correctly identified the groups. If you see that the counts are reversed, it usually indicates an error in how the “Value of State Variable” was defined in the previous step. Validating these numbers ensures that all subsequent interpretations regarding sensitivity and specificity are anchored in the correct reality. Once the counts are confirmed, you can move forward to the visual analysis of the curve itself with confidence in your underlying data structure.
Visual Analysis of the ROC Curve Plot
The ROC Curve plot is the visual centerpiece of this analysis. It illustrates the performance of the model across all possible thresholds by plotting the True Positive Rate (Sensitivity) on the vertical axis and the False Positive Rate (1 – Specificity) on the horizontal axis. A diagonal line from the bottom-left to the top-right corner represents the “line of no discrimination.” Any curve that follows this diagonal indicates a model that is no better than random chance. Conversely, a curve that bows significantly toward the top-left corner indicates a model with high discriminatory power.

In our basketball example, the blue line represents the performance of college points as a predictor for being drafted. We can observe that the curve “hugs” the upper-left corner of the plot. This visual cue tells us immediately that college points are an excellent predictor; the model achieves a high sensitivity while maintaining a very low false positive rate. The closer the curve gets to that top-left coordinate (0,1), the more “perfect” the test is considered to be. This visual assessment is often the first thing a researcher looks at to determine if the variable being tested has any real-world utility.
When presenting these results, the visual curve serves as an accessible way to communicate model quality to non-technical stakeholders. It clearly shows that by choosing a specific scoring average, a scout can successfully identify most future NBA players without incorrectly labeling too many non-prospects. However, while the visual is helpful for an initial impression, it must be supported by the quantitative data provided in the Area Under the Curve (AUC) table to provide a truly rigorous scientific evaluation.
Quantifying Accuracy: The Area Under the Curve (AUC)
The Area Under the Curve, commonly referred to as the AUC, provides a single numerical value that summarizes the overall performance of the diagnostic test. The AUC value ranges from 0.5 to 1.0. An AUC of 0.5 suggests that the model has no discriminative ability (equivalent to the diagonal reference line), whereas an AUC of 1.0 represents a perfect test that correctly classifies every single case. Generally, an AUC above 0.8 is considered “good,” and a value above 0.9 is considered “excellent.”

For the model we generated in SPSS, the AUC is calculated at .948. This is an exceptionally high value, indicating that the model is extremely effective at distinguishing between players who will be drafted and those who will not. Specifically, an AUC of .948 means that if you randomly select one drafted player and one non-drafted player, there is a 94.8% probability that the drafted player will have a higher collegiate scoring average than the non-drafted player. This statistic provides the mathematical “proof” of the model’s validity that the visual curve suggests.
In academic and professional reporting, the AUC is the primary metric cited when comparing different models. For instance, if you were testing multiple predictors—such as points per game, rebounds per game, and assists per game—you would compare the AUC of each resulting ROC curve to determine which statistic is the most reliable predictor of success. SPSS also provides asymptotic 95% confidence intervals and p-values for the AUC, allowing you to determine if the result is statistically significant and not merely the product of a small or biased sample.
Analyzing Coordinates and Identifying the Optimal Cut-off Point
The final stage of the analysis involves examining the Coordinates of the Curve table. This detailed report lists the sensitivity and (1 – specificity) for every observed value of the test variable. This table is where the abstract curve becomes a practical tool. By looking at these coordinates, a researcher can identify the exact cut-off point that provides the best balance of sensitivity and specificity for their specific needs. In some cases, high sensitivity is more important, while in others, high specificity is the priority.

Let’s analyze a specific threshold from our output: a cut-off of 8.50 points per game. At this threshold, the model predicts that any player scoring 8.50 points or more will be drafted, while those scoring less will not. According to the table, this cut-off yields a sensitivity of 1.000 (100%). This means the model correctly identifies every single player who was actually drafted. However, the 1 – specificity at this point is .667, meaning the specificity is only 33.3%. This suggests that while we caught all the pros, we also “falsely” predicted that many others would be drafted who actually were not.
Choosing the “optimal” cut-off point often involves a method like Youden’s J statistic (Sensitivity + Specificity – 1) or simply finding the point on the curve closest to the top-left corner. If the goal of a scout is to never miss a potential star, they might accept the 8.50 threshold despite the false positives. If the goal is to be highly selective with limited resources, they might choose a higher scoring threshold that improves specificity even at the cost of some sensitivity. SPSS provides the data necessary to make these nuanced, high-stakes decisions with mathematical precision.
Conclusion and Practical Applications
Mastering the creation and interpretation of ROC curves in SPSS is a transformative skill for any data analyst or researcher. It moves the conversation from simple correlations to a sophisticated understanding of diagnostic accuracy and classification thresholds. By following the steps outlined in this guide—preparing your binary and continuous variables, navigating the Classify menu, and analyzing the resulting visual and quantitative outputs—you can provide deep, evidence-based insights into your data’s predictive capabilities.
The practical applications of this analysis are vast. In healthcare, it is used to determine the effectiveness of new medical tests; in finance, it helps in credit scoring and fraud detection; and in sports, as we have seen, it can help identify the most significant metrics for future success. The ROC curve provides a universal language for model evaluation that transcends specific industries, making it one of the most versatile tools in the SPSS suite. Its ability to handle the inherent trade-offs between sensitivity and specificity ensures that decisions are made based on a full understanding of potential errors and successes.
As you continue to use SPSS for your statistical needs, remember that the ROC curve is more than just a graph; it is a comprehensive framework for model validation. Whether you are aiming for a high AUC to prove your model’s dominance or digging into the coordinates table to find the perfect cut-off point, the insights gained from this analysis are invaluable. By integrating these techniques into your workflow, you ensure that your conclusions are robust, your classifications are optimized, and your research stands up to the highest levels of scrutiny.
Cite this article
stats writer (2026). How to Create and Interpret a ROC Curve in SPSS for Accurate Diagnostic Test Evaluation. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-create-and-interpret-a-roc-curve-in-spss/
stats writer. "How to Create and Interpret a ROC Curve in SPSS for Accurate Diagnostic Test Evaluation." PSYCHOLOGICAL SCALES, 15 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-i-create-and-interpret-a-roc-curve-in-spss/.
stats writer. "How to Create and Interpret a ROC Curve in SPSS for Accurate Diagnostic Test Evaluation." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-create-and-interpret-a-roc-curve-in-spss/.
stats writer (2026) 'How to Create and Interpret a ROC Curve in SPSS for Accurate Diagnostic Test Evaluation', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-create-and-interpret-a-roc-curve-in-spss/.
[1] stats writer, "How to Create and Interpret a ROC Curve in SPSS for Accurate Diagnostic Test Evaluation," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Create and Interpret a ROC Curve in SPSS for Accurate Diagnostic Test Evaluation. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.