Table of Contents
Understanding Multivariate Analysis of Variance (MANOVA)
Multivariate Analysis of Variance, commonly known by the acronym MANOVA, represents a sophisticated statistical procedure used by researchers to explore the relationships between one or more independent variables and multiple dependent variables simultaneously. Unlike simpler univariate models that assess outcomes in isolation, MANOVA evaluates the differences between group means across a combination of variables, providing a more comprehensive overview of the data’s underlying structure. This technique is particularly valuable in fields such as psychology, education, and medicine, where a single intervention or characteristic often influences a diverse array of outcomes that are likely to be correlated with one another.
The primary utility of a MANOVA lies in its ability to detect patterns and effects that might remain hidden during a series of separate univariate tests. When a researcher analyzes multiple response variables independently, they run the risk of inflating the Type I error rate—the probability of incorrectly rejecting a true null hypothesis. By utilizing a multivariate framework, the researcher can maintain a specific alpha level while accounting for the covariance between the outcomes. This leads to a more robust and statistically sound conclusion regarding the overall impact of the explanatory variables on the system as a whole.
Within the Stata software environment, performing a MANOVA is a streamlined process facilitated by the dedicated manova command. This command is highly versatile, allowing for the inclusion of various model specifications and the calculation of several distinct multivariate test statistics, such as Wilks’ Lambda and Pillai’s Trace. Furthermore, Stata offers a suite of post-estimation tools that enable researchers to interpret their results deeply, including post-hoc tests and contrast analyses. This combination of power and accessibility makes Stata a preferred choice for professionals conducting complex multivariate research.
Distinguishing Between ANOVA and MANOVA
To grasp the complexities of MANOVA, it is helpful to first consider the standard Analysis of Variance (ANOVA). An ANOVA is used to determine whether different levels of a single categorical explanatory variable lead to statistically significant differences in the mean of a single continuous response variable. For example, a social scientist might investigate whether three distinct levels of education—an Associate’s degree, a Bachelor’s degree, or a Master’s degree—result in significantly different annual incomes. In this univariate scenario, the focus is entirely on a single dimension of success: earnings.
In this classic ANOVA example, the components are defined as follows:
- Explanatory variable: Level of education (the factor being studied).
- Response variable: Annual income (the single outcome measure).
However, real-world phenomena are rarely so simple. A MANOVA serves as a direct extension of the one-way ANOVA, designed for situations where there is more than one response variable. In our education example, a researcher might find it insufficient to look only at income. They might also want to understand how education level affects the total amount of student loan debt an individual carries. Here, the research question evolves into a multivariate problem because we are interested in two outcomes simultaneously: income and debt.
By shifting to a MANOVA, the variables in our expanded study are categorized as follows:
- Explanatory variable: Level of education.
- Response variables: Annual income and total student loan debt.
Because these two outcomes (income and debt) are likely related—higher degrees often lead to higher salaries but also require more substantial financial investment—a MANOVA is the most appropriate tool. It allows the researcher to determine if education level has a significant effect on the “centroid” or the combined mean vector of both income and debt, rather than just looking at them as isolated, unrelated figures.
Preparing for MANOVA in Stata: Data Entry and Structure
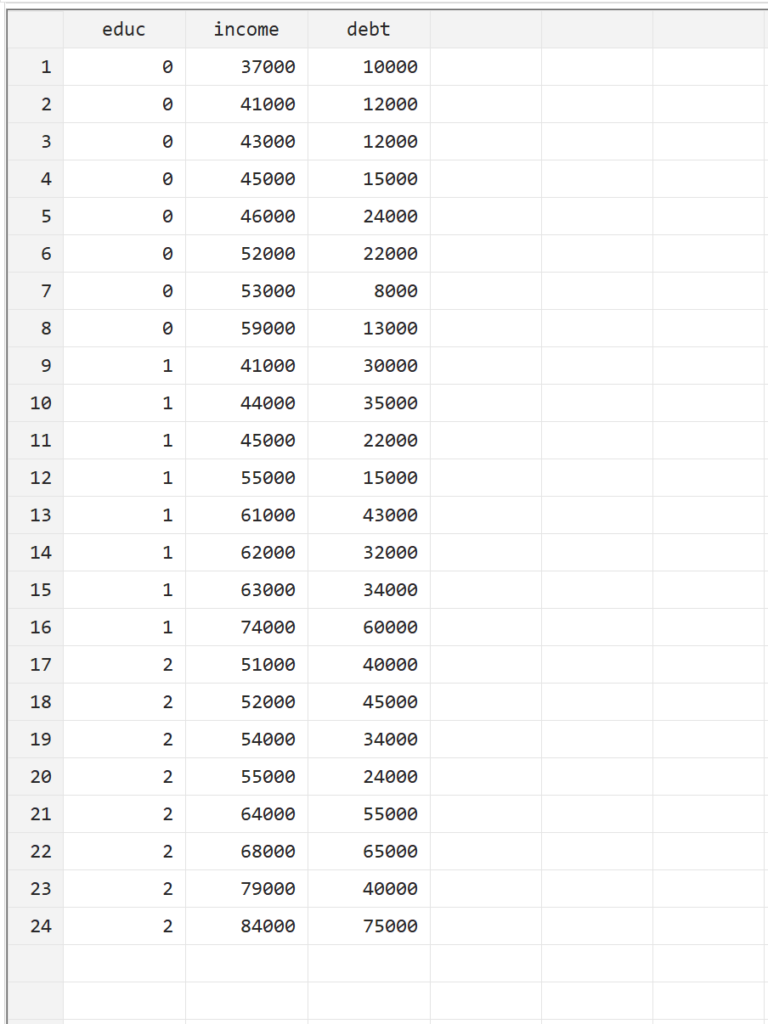
To demonstrate the practical application of MANOVA within Stata, we will examine a sample dataset involving 24 individuals. This dataset tracks three specific metrics: the level of education (labeled “educ” and coded as 0 for Associate, 1 for Bachelor, and 2 for Master), the individual’s annual income, and their total student loan debt. Before running any statistical test, it is vital to ensure that the data is organized in a “long” or “wide” format that the software can recognize, with each row representing an individual observation and each column representing a variable.

If you wish to follow along or replicate this analysis, you can enter the data manually into the Stata environment. This is accomplished by navigating to the Data menu at the top of the interface, selecting Data Editor, and then clicking on Data Editor (Edit). This spreadsheet-like interface allows for precise data entry and modification. Once the variables for education, income, and debt are populated, the dataset is ready for multivariate analysis.
Proper data preparation also involves checking the assumptions of the MANOVA model. These typically include multivariate normality, homogeneity of variance-covariance matrices, and the independence of observations. While MANOVA is relatively robust to minor violations, extreme outliers or significant differences in group sizes can affect the validity of the results. Stata provides various diagnostic commands to verify these assumptions before the final manova command is executed, ensuring that the resulting P-value is accurate and meaningful.
Executing the MANOVA Command in Stata
The syntax for performing a MANOVA in Stata is designed to be both powerful and user-friendly. To test the hypothesis that education level significantly influences the combined outcomes of income and debt, you would utilize the manova command followed by your dependent variables and then your independent variable. The specific command for our example is structured as follows:
manova income debt = educ
This command instructs Stata to perform a multivariate analysis where “income” and “debt” are treated as the outcomes, and “educ” is the categorical factor. The software then processes the linear algebra necessary to compare the mean vectors across the three groups defined by the education variable. The resulting output window will provide a detailed summary of the model, including the number of observations and the specific test statistics used to evaluate the null hypothesis.

One of the benefits of using Stata for this analysis is the clarity of its output. The software automatically calculates four distinct multivariate tests to ensure the findings are consistent. These include Wilks’ Lambda, Pillai’s Trace, the Hotelling-Lawley Trace, and Roy’s Largest Root. Having access to all four statistics allows researchers to cross-verify their results, as different tests have varying levels of sensitivity to violations of statistical assumptions.
Analyzing the Multivariate Test Statistics
When the MANOVA is completed, Stata produces a table containing four unique test statistics, each accompanied by its own F-Statistic and P-value. Understanding these statistics is essential for a thorough interpretation of the study’s results:
- Wilks’ Lambda: This is perhaps the most commonly reported multivariate statistic. It measures the proportion of variance in the dependent variables that is not explained by the independent variable. In our example, the F-Statistic is 5.02 with a P-value of 0.0023.
- Pillai’s Trace: Often considered the most robust of the four tests, Pillai’s Trace is less sensitive to violations of the assumption of homogeneity of covariance matrices.
- Lawley-Hotelling Trace: Also known as the Hotelling-Lawley trace, this statistic assesses the total eigenvalues of the model. Here, the F-Statistic is 5.94 with a P-value of 0.0008.
- Roy’s Largest Root: This test focus exclusively on the first eigenvector and provides the maximum possible difference between groups. In our example, it yields an F-Statistic of 13.10 and a P-value of 0.0002.
For a more technical and in-depth explanation regarding the mathematical derivation of these values, researchers often refer to documentation provided by academic institutions like the Penn State Eberly College of Science. Each of these values contributes to a multifaceted understanding of how the independent variable impacts the dependent variables as a collective group.
Interpreting the Results and Conclusion
The primary goal of interpreting the MANOVA output is to determine whether to reject or fail to reject the null hypothesis. In this context, the null hypothesis posits that the level of education has no significant effect on the combined mean of income and student debt. To make this determination, we look at the P-value for each test statistic. Since all the P-values in our output (0.0023, 0.0008, and 0.0002) are substantially less than the standard significance threshold of 0.05, we have strong evidence to reject the null hypothesis.
The rejection of the null hypothesis indicates that there are statistically significant differences in annual income and total student debt based on an individual’s level of education. This confirms that education is a powerful predictor of financial outcomes, at least within the scope of this specific dataset. However, it is important to remember that a significant MANOVA result only tells us that a difference exists somewhere among the groups; it does not specify which groups are different or which dependent variables are driving the effect.
To pinpoint the exact nature of these differences, a researcher would typically perform post-hoc tests or separate univariate ANOVAs as a follow-up. This “protected” testing strategy ensures that the overall multivariate significance is established before exploring individual relationships, thereby maintaining the statistical significance and integrity of the entire analysis. Stata makes these follow-up steps easy to execute, providing a complete workflow for the modern researcher.
Understanding Stata’s P-value Notations
An interesting detail within the Stata output table is the presence of lowercase letters next to the P-values. These characters provide important information about the mathematical method used to calculate the F-statistic. Because the distributions of multivariate statistics can be complex, Stata employs different computational approaches depending on the data structure and the specific test being performed.
The notations are defined as follows:
- e: Represents an exact calculation of the probability distribution.
- a: Indicates an approximate calculation, which is often used when the exact distribution is computationally intensive or unavailable.
- u: Denotes an upper bound for the P-value, suggesting that the actual significance may be even stronger than indicated.
By paying attention to these details, researchers can gain a deeper appreciation for the precision of their findings. In conclusion, Stata offers a comprehensive and accessible platform for conducting MANOVA. From initial data entry to the interpretation of complex multivariate statistics, the software provides all the tools necessary to perform high-quality research and draw meaningful conclusions from multifaceted datasets.
Cite this article
stats writer (2026). How to Perform a MANOVA in Stata: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-a-manova-be-performed-in-stata/
stats writer. "How to Perform a MANOVA in Stata: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 9 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-a-manova-be-performed-in-stata/.
stats writer. "How to Perform a MANOVA in Stata: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-a-manova-be-performed-in-stata/.
stats writer (2026) 'How to Perform a MANOVA in Stata: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-a-manova-be-performed-in-stata/.
[1] stats writer, "How to Perform a MANOVA in Stata: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Perform a MANOVA in Stata: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.