Table of Contents
Understanding the Role of Confidence Intervals and the F Distribution
In the field of statistics, a confidence interval serves as a fundamental tool for researchers and data analysts who seek to estimate the true value of a population parameter based on empirical evidence gathered from a sample. Unlike a point estimate, which provides a single numerical value, a confidence interval offers a range of plausible values, thereby accounting for the inherent sampling error and providing a clearer picture of the precision of the estimate. This method is particularly vital when we aim to generalize findings from a subset of data to a larger, unobserved population, ensuring that our conclusions are grounded in mathematical probability rather than mere conjecture.
The F distribution is a continuous probability distribution that arises frequently in the context of the analysis of variance (ANOVA) and linear regression models. Specifically, it is utilized to compare the variances of two distinct populations to determine if they are significantly different from one another. By constructing a confidence interval using the F distribution, statisticians can determine the range within which the ratio of two population variances likely resides. This process is essential for validating the assumptions of various parametric tests, such as the two-sample t-test, which often requires the assumption of equal variances, also known as homoscedasticity.
To successfully create a confidence interval using this distribution, one must meticulously determine the degrees of freedom associated with each sample. These values are derived from the sample sizes and directly influence the shape of the probability density function. Once the degrees of freedom are established, the next step involves identifying the critical values from an F distribution table or statistical software. These critical values act as the boundaries for the interval, allowing the researcher to calculate the upper and lower limits that encapsulate the true population parameter with a specific level of confidence, such as 95% or 99%. This systematic approach not only enhances the accuracy of the estimation but also quantifies the uncertainty inherent in the statistical inference process.
The Statistical Foundations of Comparing Population Variances
When conducting comparative research, it is often necessary to evaluate whether the variances of two independent populations are equal. This is achieved by calculating the variance ratio, expressed as σ²₁ / σ²₂. In this equation, σ²₁ represents the variance of the first population, while σ²₂ denotes the variance of the second. If the two populations have identical variances, the ratio will be equal to one. Deviations from this value suggest that one population exhibits more dispersion or “spread” than the other, which can have significant implications for how data is interpreted and which statistical models are applied.
In practice, we rarely have access to the entire population, so we rely on samples to estimate these parameters. By taking a random sample from each population, we calculate the sample variance ratio, denoted as s²₁ / s²₂. Here, s²₁ and s²₂ are the variances calculated from the sample data. This sample ratio serves as a point estimate for the true population variance ratio. However, because sample statistics vary from one sample to another, we must use the F distribution to build a confidence interval around this ratio, providing a robust statistical framework for our conclusions.
The F-test for equality of variances is built upon specific mathematical assumptions that must be satisfied for the results to be valid. Primarily, the test assumes that the two samples are independent of each other and that each sample is drawn from a normally distributed population. The sensitivity of the F distribution to departures from normality is a well-known characteristic; if the underlying populations are heavily skewed or have heavy tails, the resulting confidence interval may be misleading. Therefore, it is standard practice to perform normality tests or visual inspections, such as Q-Q plots, before proceeding with the creation of the confidence interval.
Defining the Mathematical Framework for the F-Interval
The construction of a (1-α)100% confidence interval for the ratio of two population variances, σ²₁ / σ²₂, requires a clear understanding of the significance level, denoted by α. This value represents the probability of rejecting the null hypothesis when it is actually true, or more simply, the risk of the true parameter falling outside the calculated interval. For a 95% confidence interval, α would be 0.05. The interval is mathematically defined as the range between the lower and upper bounds where the ratio is expected to lie. The formula utilizes the sample variances and the critical values of the F distribution corresponding to the degrees of freedom for both samples.
The structural formula for the confidence interval is expressed as follows: (s²₁ / s²₂) * F_lower ≤ σ²₁ / σ²₂ ≤ (s²₁ / s²₂) * F_upper. In this context, the critical values are determined based on the degrees of freedom for the numerator (n₁-1) and the denominator (n₂-1). Because the F distribution is not symmetrical, the calculation of the lower and upper bounds involves distinct values from the F-table. Specifically, the upper bound uses the critical value for F at α/2 with (n₂-1, n₁-1) degrees of freedom, while the lower bound often involves the reciprocal of an F-value to account for the skewness of the distribution.
To demonstrate this process, we will utilize a consistent set of data across three different computational methods: manual calculation, Microsoft Excel, and the R programming language. By using the same parameters, we can verify the consistency and accuracy of each approach. The parameters for our examples are as follows:
- Significance level (α) = 0.05
- Sample size 1 (n₁) = 16
- Sample size 2 (n₂) = 11
- Sample variance 1 (s²₁) = 28.2
- Sample variance 2 (s²₂) = 19.3
Manual Calculation of the Confidence Interval
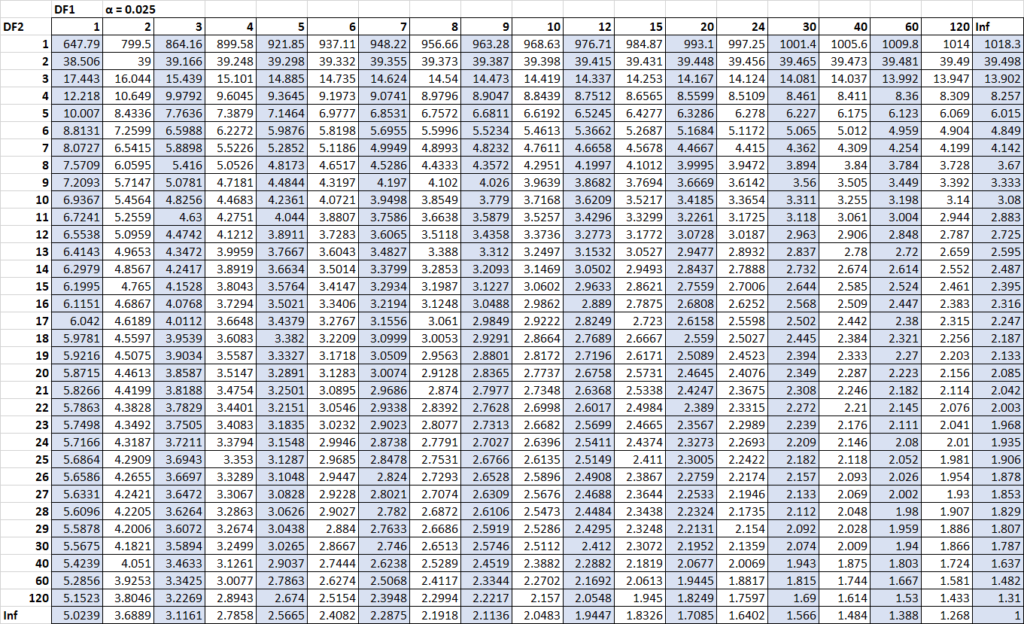
Calculating the confidence interval by hand is an excellent way to grasp the underlying mechanics of the F-test. The first step in this manual process is to determine the degrees of freedom for both samples. For our first sample (n₁ = 16), the degrees of freedom are df₁ = 16 – 1 = 15. For the second sample (n₂ = 11), the degrees of freedom are df₂ = 11 – 1 = 10. These values are necessary to locate the correct critical values in a standard F distribution table for a two-tailed test at the α/2 = 0.025 level.
Using the F distribution table, we find the critical value for F with 10 and 15 degrees of freedom at the 0.025 significance level, which is 3.0602. This value will be used for our upper bound. For the lower bound, we need the critical value for F with 15 and 10 degrees of freedom. However, since many tables only provide values for the upper tail, we apply the reciprocal property of the F distribution: F(15, 10, 0.975) = 1 / F(15, 10, 0.025). The table value for F(15, 10, 0.025) is 3.5217, making our lower critical factor 1 / 3.5217, which equals 0.2839.

With these critical values in hand, we can proceed to the final calculation. The ratio of our sample variances is 28.2 / 19.3, which is approximately 1.4611. Multiplying this ratio by our lower critical factor (1.4611 * 0.2839) gives us a lower bound of 0.4148. Multiplying the ratio by our upper critical value (1.4611 * 3.0602) gives us an upper bound of 4.4714. Thus, we can state with 95% confidence that the true ratio of the population variances falls between 0.4148 and 4.4714. This range includes the value of 1.0, suggesting that there is not enough evidence to conclude the variances are significantly different.
Streamlining the Process Using Microsoft Excel
For those who prefer a more automated approach, Microsoft Excel offers powerful built-in functions to calculate the confidence interval for the variance ratio efficiently. Excel eliminates the need to manually consult F distribution tables, reducing the risk of human error in looking up values. The primary functions used for this purpose are F.INV and F.INV.RT, which return the inverse of the F probability distribution for the left and right tails, respectively.
In our Excel model, we input the sample variances and sizes into designated cells. To find the lower bound, we multiply the sample variance ratio by the inverse F-value for the left tail. To find the upper bound, we multiply the ratio by the inverse F-value for the right tail. This method is highly scalable, allowing researchers to quickly update their results if sample data changes. The image below illustrates the specific cell configurations and formulas used to achieve the same result we found manually.

As demonstrated in the spreadsheet, the 95% confidence interval for the ratio of the population variances is (0.4148, 4.4714). This perfect alignment with our manual calculations confirms the reliability of using Microsoft Excel for statistical inference. By leveraging these computational tools, analysts can focus more on the interpretation of the data rather than the nuances of arithmetic, leading to more efficient and accurate research outcomes.
Advanced Implementation with the R Programming Language
The R programming language is widely considered the gold standard for statistical computing and graphics. It provides a flexible environment for performing complex calculations, including the construction of confidence intervals for the F distribution. Using R is particularly advantageous when dealing with large datasets or when the analysis needs to be integrated into a larger data science pipeline. The `qf()` function in R is used to calculate the quantiles of the F distribution, which serve as our critical values.
To implement this in R, we define our variables for the significance level, sample sizes, and variances. We then use the `qf()` function to find the upper and lower critical values. Note that in R, the `qf()` function typically calculates the lower tail, so we adjust the arguments to obtain the correct values for our two-tailed interval. The following script demonstrates how to execute these commands and print the resulting confidence interval to the console.
#define significance level, sample sizes, and sample variances alpha <- .05 n1 <- 16 n2 <- 11 var1 <- 28.2 var2 <- 19.3 #define F critical values upper_crit <- 1/qf(alpha/2, n1-1, n2-1) lower_crit <- qf(alpha/2, n2-1, n1-1) #find confidence interval lower_bound <- (var1/var2) * lower_crit upper_bound <- (var1/var2) * upper_crit #output confidence interval paste0("(", lower_bound, ", ", upper_bound, " )") #[1] "(0.414899337980266, 4.47137571035219 )"
The output from R confirms the 95% confidence interval as (0.4148, 4.4714). This consistency across manual, Excel, and R-based methods underscores the mathematical robustness of the F distribution approach. Using R also allows for the easy visualization of the distribution, which can help in explaining the results to stakeholders who may not have a deep background in statistics.
Interpreting the Results and Practical Implications
Once the confidence interval has been calculated, the final and most crucial step is the interpretation of the results. In our example, the 95% confidence interval for the ratio of population variances (σ²₁ / σ²₂) was found to be (0.4148, 4.4714). The primary question usually asked is whether the variances of the two populations are equal. If the variances were equal, the ratio σ²₁ / σ²₂ would be exactly 1. Because the value 1.0 falls comfortably within our calculated interval, we do not have sufficient evidence to reject the null hypothesis that the variances are equal.
This finding has significant practical implications for subsequent statistical testing. Since we cannot conclude that the variances are different, we can proceed with standard parametric tests that assume equal variances, such as the standard two-sample t-test. If the interval had not included 1.0 (for example, if the interval was 1.5 to 5.0), we would have concluded that the variances are significantly different, necessitating the use of Welch’s t-test, which does not assume equal variances.
Ultimately, the use of the F distribution to create confidence intervals provides a mathematically sound way to quantify the relationship between the dispersions of two groups. Whether performed by hand or through advanced software like Excel or R, this process is a cornerstone of rigorous data analysis. By understanding the range of possible values for the variance ratio, researchers can make more informed decisions about their models, leading to more reliable and reproducible scientific conclusions.
Cite this article
stats writer (2026). How to Calculate a Confidence Interval Using the F Distribution. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-a-confidence-interval-be-created-using-the-f-distribution/
stats writer. "How to Calculate a Confidence Interval Using the F Distribution." PSYCHOLOGICAL SCALES, 4 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-a-confidence-interval-be-created-using-the-f-distribution/.
stats writer. "How to Calculate a Confidence Interval Using the F Distribution." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-a-confidence-interval-be-created-using-the-f-distribution/.
stats writer (2026) 'How to Calculate a Confidence Interval Using the F Distribution', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-a-confidence-interval-be-created-using-the-f-distribution/.
[1] stats writer, "How to Calculate a Confidence Interval Using the F Distribution," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Calculate a Confidence Interval Using the F Distribution. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.