Table of Contents
Multivariate Analysis of Variance, commonly referred to as MANOVA, represents a sophisticated statistical framework designed to evaluate the influence of one or more categorical independent variables on multiple continuous dependent variables simultaneously. Unlike a standard univariate analysis, a MANOVA considers the correlations between the dependent variables, providing a more holistic view of the data structure. In the context of the SPSS (Statistical Package for the Social Sciences) environment, performing this analysis requires a systematic approach to data entry, model specification, and result interpretation to ensure that the findings are both statistically valid and practically meaningful for researchers in fields ranging from psychology to economics.
The primary advantage of utilizing a MANOVA over conducting several separate ANOVA (Analysis of Variance) tests is the protection it offers against Type I error inflation. When multiple tests are performed on the same dataset, the probability of incorrectly rejecting a true null hypothesis increases; MANOVA mitigates this by assessing all dependent variables in a single integrated procedure. To initiate this process in SPSS, users must first ensure their dataset is correctly formatted, with each row representing an individual observation and each column representing a distinct variable. Whether importing an existing file from Excel or manually entering data into the Data Editor, maintaining high levels of data integrity is the first step toward a successful multivariate investigation.
Once the data is securely situated within the software, the MANOVA function is accessed through the General Linear Model menu. This sophisticated tool allows researchers to define complex relationships and adjust for covariates if necessary. By selecting the appropriate multivariate options, such as descriptive statistics and effect size measures like Partial Eta Squared, the user can obtain a comprehensive output that details not only the statistical significance of the predictors but also the magnitude of the observed differences. This high level of detail is essential for interpreting the nuances of group differences across a suite of related outcomes.
Understanding the Core Concepts of MANOVA in SPSS
A standard ANOVA is a statistical tool employed by researchers to determine if different levels of a specific explanatory variable result in statistically significant variations within a single response variable. This method is highly effective when the researcher is focused on one primary outcome measure across various experimental or observational groups. For instance, an investigator might want to determine if different teaching methods lead to different average test scores among students. In this scenario, the teaching method serves as the factor, and the test score represents the metric being evaluated.
Consider a practical scenario where we examine whether three distinct levels of education—specifically an Associate’s degree, a Bachelor’s degree, and a Master’s degree—lead to statistically different annual incomes. In this univariate framework, we are dealing with a single independent variable (education level) and a single dependent variable (annual income). The analysis would tell us if at least one group mean differs from the others, but it remains limited because it cannot account for other related financial outcomes that might be influenced by the same educational background.
- Explanatory variable: Level of education (Categorical)
- Response variable: Annual income (Continuous)
A MANOVA serves as a powerful extension of the one-way ANOVA by incorporating more than one response variable into the mathematical model. This is particularly useful when the dependent variables are conceptually related or correlated. For example, a researcher might be interested in understanding not just how education levels affect annual income, but also how they influence the total amount of student loan debt an individual carries. By using a MANOVA, the researcher can evaluate the effect of education on a combined “financial profile” consisting of both income and debt.
- Explanatory variable: Level of education
- Response variables: Annual income and student loan debt
Because this research design involves multiple dependent variables, applying a MANOVA is the most robust choice. It allows for the detection of patterns that might be missed if each variable were analyzed in isolation. Furthermore, it accounts for the mathematical covariance between income and debt, providing a more accurate p-value for the overall model. In the following sections, we will provide a comprehensive, step-by-step tutorial on how to execute and interpret this analysis within the SPSS software environment.
Implementing a MANOVA: A Practical Dataset Example
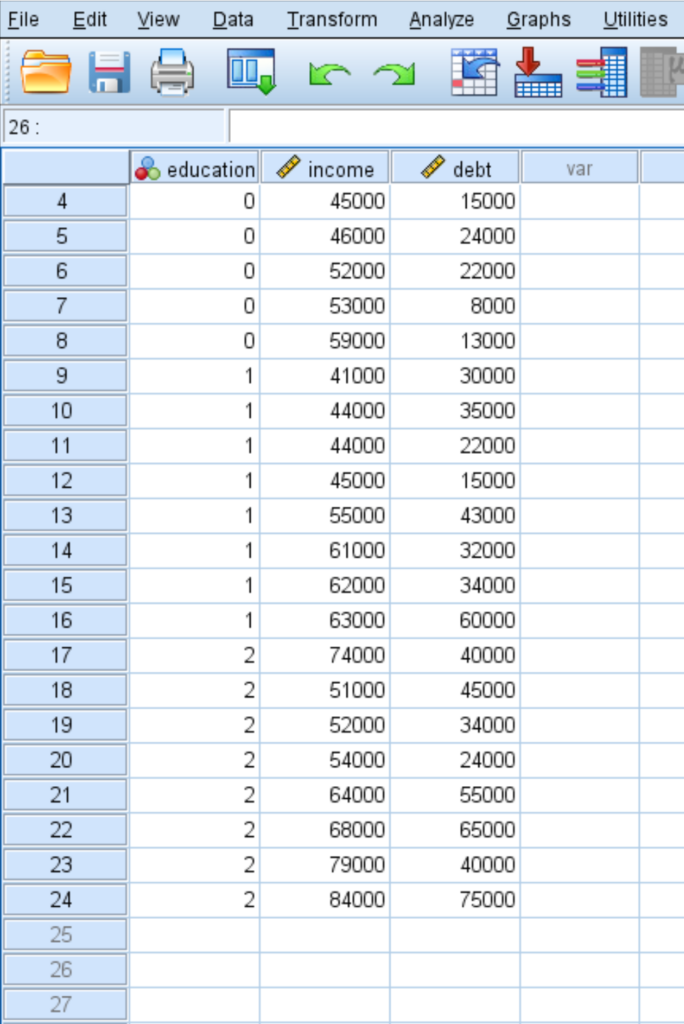
To demonstrate the practical application of a MANOVA within SPSS, we will utilize a sample dataset comprising 24 individual observations. Each entry in the dataset includes three specific variables that allow us to test the impact of academic attainment on financial status. The goal is to determine if the “centroid,” or the collective mean of the dependent variables, differs significantly across the various educational groups. This approach provides a much deeper level of insight than a series of independent tests.
The variables included in our demonstration dataset are defined as follows: educ, which represents the level of education (coded as 0 for Associate, 1 for Bachelor, and 2 for Master); income, representing the annual earnings of the individual; and debt, representing the total student loan debt. By analyzing these variables together, we can observe how the transition from a two-year degree to a graduate degree influences the broader financial landscape of the participants.
- educ: Level of education (Categorical Factor)
- income: Annual income (Continuous Dependent Variable)
- debt: Total student loan debt (Continuous Dependent Variable)

Before proceeding with the analysis, it is important to ensure that the data meets certain assumptions, such as multivariate normality and the absence of multicollinearity. Once the data is entered into the SPSS spreadsheet as shown above, we can move forward with the statistical procedures. Following these structured steps will ensure that the General Linear Model is applied correctly, yielding results that are both reliable and easy to communicate in a research report or academic paper.
Step 1: Navigating the Multivariate Analysis Menus
The process begins by directing your attention to the top navigation bar in SPSS. Click on the Analyze tab, which houses the majority of the software’s statistical procedures. From the resulting dropdown menu, hover over General Linear Model and then select Multivariate. This path is specifically designed for models where multiple continuous dependent variables are predicted by one or more categorical factors, making it the standard route for performing a MANOVA.

Upon selecting Multivariate, a new dialog box will appear on your screen. This interface is where you define the roles of your variables. You must identify the outcomes you wish to measure and the groups you wish to compare. In our specific example, you will drag the income and debt variables from the list on the left and place them into the box labeled Dependent Variables. These are the metrics we expect will change based on the participant’s educational background.
Next, locate the education variable and drag it into the box labeled Fixed Factors. The “Fixed Factor” designation is used for independent variables that represent discrete categories or groups. At this stage, you may also choose to click on the “Options” button to select additional output features such as “Descriptive statistics” or “Estimates of effect size,” which are invaluable for a thorough interpretation of the data. Once the variables are correctly assigned, the dialog box should reflect the structure of your specific research hypothesis.


After finalizing your variable selections and ensuring all necessary options are checked, click the OK button to execute the analysis. SPSS will then process the data using the General Linear Model framework and generate an output viewer window containing several tables. These tables provide the mathematical evidence needed to support or reject your null hypothesis regarding the relationship between education, income, and debt.
Step 2: Interpreting the Multivariate Test Results
The first critical table to examine in your output is the Multivariate Tests table. This table provides an “omnibus” test of the model, which tells you whether education levels have a statistically significant effect on the combined dependent variables (income and debt). Rather than looking at each outcome individually, this test looks at the group differences across the entire multivariate space. It is the definitive starting point for any MANOVA interpretation, as it determines whether further analysis of individual variables is warranted.
Within this table, researchers typically focus on the row labeled Wilks’ Lambda. This is one of the most widely reported statistics in multivariate research because of its reliability and ease of interpretation. Wilks’ Lambda represents the proportion of variance in the dependent variables that is not explained by the independent variable. A smaller value for Wilks’ Lambda indicates a greater effect of the independent variable on the dependent variables, leading to a higher likelihood of statistical significance.

In our example output, the F-statistic associated with Wilks’ Lambda is 6.138, and the corresponding p-value is .001. Standard practice in social science research uses a significance threshold (alpha) of .05. Because our p-value of .001 is considerably lower than .05, we can conclude that education level does indeed have a significant impact on the combined financial outcomes of annual income and student debt. This result justifies moving forward to examine which specific variables are being influenced.
Analyzing the Tests of Between-Subjects Effects
While the multivariate test confirms that there is an overall effect, it does not specify which dependent variable is responsible for that effect. To find this out, we look at the Tests of Between-Subjects Effects table. This table effectively provides a separate ANOVA for each of the dependent variables included in the model. It allows us to pinpoint whether education affects income, debt, or both, thereby providing a more granular understanding of the data’s behavior.

Upon reviewing the table, we observe that the p-value for income is .003 and the p-value for debt is .000 (which indicates a value less than .001). Since both of these values are significantly lower than the .05 alpha level, we can confidently state that the level of education has a statistically significant effect on both annual income and total student loan debt individually. This confirms that the educational background is a strong predictor of multiple financial metrics within our sample population.
It is important to note that when interpreting these between-subjects effects following a significant MANOVA, some researchers apply a Bonferroni correction to the alpha level to further control for the risk of Type I errors. However, even with a more conservative threshold, our results for both income and debt remain highly significant. This consistency reinforces the reliability of the findings and suggests a robust relationship between academic achievement and financial status.
Utilizing Post Hoc Tests for Multiple Comparisons
Knowing that education level has a significant effect is valuable, but it does not tell us which specific education groups differ from one another. For instance, is the income of a Bachelor’s degree holder significantly higher than that of an Associate’s degree holder, or is the significant difference only found when comparing Associate’s degrees to Master’s degrees? To answer these specific questions, we must perform a post-hoc test. The Tukey HSD (Honestly Significant Difference) is the most common choice for this purpose.

The Tukey post hoc table displays pairwise comparisons for every possible combination of education levels across all dependent variables. By examining the “Sig.” column for each pair, we can identify exactly where the differences lie. This step is crucial for transitioning from a general “there is a difference” statement to a specific “Group A is different from Group B” conclusion, which is often the primary goal of the research study.
Based on the output table provided, we can derive the following conclusions regarding income levels:
- The annual income for individuals with an Associate’s degree (Group 0) is significantly different from those with a Master’s degree (Group 2), with a p-value of .000.
- The income for Bachelor’s degree holders (Group 1) also differs significantly from Master’s degree holders (Group 2), showing a p-value of .029.
- The comparison between Associate’s degree holders (Group 0) and Bachelor’s degree holders (Group 1) yields a p-value of .018, indicating another significant gap in earnings.
- Similar significant differences are observed across the debt variable, suggesting that as the level of education increases, both the earning potential and the debt burden change in a statistically measurable way.
Conclusion and Best Practices for Reporting MANOVA
Performing a MANOVA in SPSS is a multi-layered process that requires careful attention to detail, from the initial data entry to the final post-hoc interpretation. By following the General Linear Model procedure, researchers can account for the complexities of real-world data where outcomes are often interrelated. The use of statistics like Wilks’ Lambda ensures that the overall model is sound before moving on to the more specific univariate and pairwise comparisons that define the nuances of the study.
When reporting these results in a formal research paper, it is essential to include the F-statistic, the degrees of freedom, the p-value, and the effect size for the multivariate test. Furthermore, clearly presenting the results of the between-subjects effects and the Tukey HSD comparisons allows readers to see the full scope of the findings. This transparency is key to the scientific method, allowing others to verify and potentially replicate the study’s results in different contexts or with larger populations.
Ultimately, the power of MANOVA lies in its ability to synthesize multiple streams of information into a single, cohesive statistical narrative. Whether you are investigating the impact of education on financial health or the effect of a new medical treatment on various physiological markers, SPSS provides the tools necessary to perform this high-level analysis with precision. As you continue to explore multivariate statistics, always remember to verify your assumptions and choose the most authoritative sources to guide your methodological decisions.
Further Reading: For those interested in expanding their statistical knowledge, exploring topics such as Discriminant Function Analysis or Factorial MANOVA can provide even deeper insights into how complex variables interact within different experimental designs.
Cite this article
stats writer (2026). How to Perform a MANOVA Analysis in SPSS: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-you-perform-a-manova-analysis-in-spss/
stats writer. "How to Perform a MANOVA Analysis in SPSS: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 15 Mar. 2026, https://scales.arabpsychology.com/stats/how-do-you-perform-a-manova-analysis-in-spss/.
stats writer. "How to Perform a MANOVA Analysis in SPSS: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-do-you-perform-a-manova-analysis-in-spss/.
stats writer (2026) 'How to Perform a MANOVA Analysis in SPSS: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-you-perform-a-manova-analysis-in-spss/.
[1] stats writer, "How to Perform a MANOVA Analysis in SPSS: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Perform a MANOVA Analysis in SPSS: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.