Table of Contents
The ability to visualize the movement of rankings over time is a critical skill in the field of data analysis. While standard line charts are effective for showing absolute values, they often fail to emphasize the relative position of subjects when those values fluctuate significantly. This is where the bump chart becomes an invaluable tool. A bump chart is a specialized version of a line plot designed specifically to track changes in rank. By focusing on the order of items rather than their underlying magnitude, these charts provide a clear narrative of competition and progression. In the R programming language, the ggplot2 package offers a robust and flexible framework for constructing these visualizations with precision and aesthetic appeal.
Creating an effective bump chart requires a systematic approach to data visualization. The process involves transforming raw data into a structured format where ranks are explicitly defined for each time interval. Once the data is prepared, ggplot2 allows users to map these ranks to the vertical axis, typically in reverse order so that the top rank appears at the peak of the chart. This tutorial provides a comprehensive guide on how to leverage R and its powerful Tidyverse ecosystem to build, style, and refine bump charts that meet professional standards for clarity and insight.
The utility of ggplot2 lies in its implementation of the Grammar of Graphics, a theoretical framework that allows users to build plots layer by layer. For a bump chart, this means combining geometric lines and points to trace the path of different categories across a temporal data frame. By the end of this guide, you will understand not only the syntax required to generate these plots but also the design principles that make them effective for communication. Whether you are tracking sports team standings, market share, or demographic shifts, the bump chart is a sophisticated choice for your analytical repertoire.
Understanding the Fundamentals of Bump Charts
Before diving into the technical implementation, it is essential to understand the theoretical foundation of a bump chart. Unlike a standard time-series plot that measures quantitative data on a continuous scale, a bump chart focuses on ordinal data. It effectively “strips away” the noise of absolute numbers to show who is winning, losing, or maintaining their position. This makes it particularly useful in scenarios where the relative performance of groups is more important than the specific scores they achieved. For example, in a multi-year study of economic indicators across different nations, a bump chart can highlight which countries are climbing the global rankings regardless of the total global GDP growth.
The visual language of a bump chart is defined by intersecting lines that “bump” up or down as entities swap positions. This intersection is the most informative part of the graphic, as it signals a change in leadership or a shift in the status quo. To ensure these intersections remain readable, data visualization experts often recommend using distinct colors and sufficient line thickness. Furthermore, because humans naturally associate “Rank 1” with the highest position, it is standard practice to reverse the Y-axis so that the number one position is at the top of the grid. This intuitive mapping reduces the cognitive load on the viewer, allowing them to interpret the data analysis results almost instantaneously.
To achieve high-quality results in R, one must adhere to the principles of tidy data. This means each variable must have its own column, each observation must have its own row, and each value must have its own cell. For a bump chart, your dataset should typically include a time variable (like days, months, or years), a grouping variable (like team names or categories), and a rank variable. If your data only contains raw scores, you will need to perform data manipulation to calculate the ranks dynamically. This ensures that the visualization remains accurate even if the underlying data values are updated or expanded.
Setting Up the R Environment and Necessary Packages
To begin our journey in creating a professional bump chart, we must first initialize our R environment with the appropriate software libraries. The most critical package for our purposes is ggplot2, which serves as the industry standard for data visualization in the R community. Developed by Hadley Wickham, ggplot2 provides a consistent interface for creating complex plots from data in a data frame. In addition to the plotting engine, we will rely heavily on dplyr, a cornerstone of the Tidyverse designed for efficient data manipulation. Together, these packages allow us to clean, rank, and plot our data within a seamless workflow.
The installation and loading process is straightforward. Users should ensure they have the latest version of R installed from the Comprehensive R Archive Network (CRAN) to avoid compatibility issues with modern package versions. Once the environment is ready, the libraries can be called into the current session. By loading dplyr, we gain access to the “pipe” operator (%>%), which allows us to chain functions together, making our code more readable and maintainable. This functional programming approach is highly encouraged in modern data analysis as it clearly documents the steps taken to transform the data from its raw state to its final visual form.
The following code snippet demonstrates the initial step of loading these essential tools. Note that while ggplot2 handles the visual layers, dplyr handles the logical structuring of the numbers. This separation of concerns is a hallmark of a professional R workflow. By mastering these two packages, you gain the ability to handle almost any data visualization challenge, far beyond the scope of simple bump charts. Below is the code required to initialize your session:
library(ggplot2) #for creating bump chart library(dplyr) #for manipulating data
Generating and Structuring the Sample Dataset
In many real-world data analysis projects, the data you receive is rarely in the perfect format for a bump chart. To simulate a realistic scenario, we will generate a synthetic dataset representing the performance of five different teams over a ten-day period. This process involves using random number generation to create scores, which we will then convert into ranks. By using the set.seed() function, we ensure that the results are reproducible, meaning anyone who runs the code will see the exact same chart. This is a vital practice in computational science and professional reporting, as it ensures transparency and consistency.
Our data structure will consist of three primary columns: “team,” “random_num” (representing a performance score), and “day.” To transform these scores into ranks, we use the group_by() function from dplyr to isolate each day. Within each day, we arrange the teams by their scores in descending order and assign a row_number() to represent their rank for that specific period. This demonstrates the power of data manipulation in R: we are creating new, meaningful information (the rank) based on existing variables. This logic is essential because ggplot2 requires explicit coordinates to draw the lines and points of the bump chart.
After the ranking logic is applied, it is important to inspect the data to verify that the transformation was successful. Using the head() function allows us to view the top few rows of our newly created data frame. You should notice that for every day, there is a clear ranking from 1 to 5. This tidy format is exactly what the ggplot2 engine needs to map the “day” to the X-axis and the “rank” to the Y-axis. The following code block provides the full implementation of this data generation and ranking process:
#set the seed to make this example reproducible
set.seed(10)
data <- data.frame(team = rep(LETTERS[1:5], each = 10),
random_num = runif(50),
day = rep(1:10, 5))
data <- data %>%
group_by(day) %>%
arrange(day, desc(random_num), team) %>%
mutate(rank = row_number()) %>%
ungroup()
head(data)
# team random_num day rank
#1 C 0.865 1 1
#2 B 0.652 1 2
#3 D 0.536 1 3
#4 A 0.507 1 4
#5 E 0.275 1 5
#6 C 0.615 2 1Constructing the Basic Bump Chart Visualization
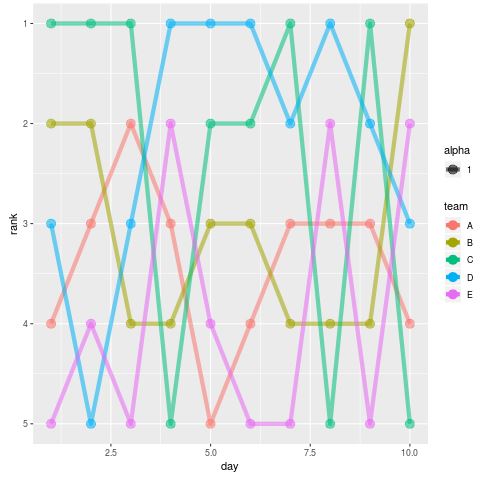
With our data correctly formatted, we can now move to the visualization phase. The core of a bump chart in ggplot2 is the combination of geom_line() and geom_point(). The geom_line() function draws the paths connecting the ranks across the time intervals, while geom_point() adds markers at each specific day to emphasize the discrete data points. In the aes() (aesthetic mapping) function, we define “day” as our X-axis and “rank” as our Y-axis. Crucially, we must include the group = team argument to ensure that R knows which points to connect with which lines. Without this, the plot would be a disorganized mess of lines rather than a coherent chart.
One of the most important steps in creating a bump chart is the axis transformation. Since the top rank is “1,” but the standard vertical axis starts at zero and increases upwards, a default plot would show the best team at the bottom. To fix this, we use the scale_y_reverse() function. This effectively flips the chart, placing the first-place team at the top. We also define the breaks on the Y-axis to match the number of ranks in our dataset, ensuring that every rank level is clearly labeled. This adjustment is a perfect example of how data visualization must be tailored to human intuition to be effective.
While the basic code produces a functional chart, it is often just the starting point for a more polished graphic. At this stage, the chart will use the default ggplot2 settings, which include a gray background and standard colors. While useful for quick data analysis, these defaults often lack the clarity required for presentations or publications. However, seeing the raw output is a necessary step to verify that the logic of our ranking and mapping is correct. The code below generates this initial, functional version of the bump chart:
ggplot(data, aes(x = day, y = rank, group = team)) + geom_line(aes(color = team, alpha = 1), size = 2) + geom_point(aes(color = team, alpha = 1), size = 4) + scale_y_reverse(breaks = 1:nrow(data))

Developing a Custom Professional Theme
To transition from a basic plot to a professional-grade data visualization, we must address the “aesthetic” of the chart. The default “gray grid” look of ggplot2 is often distracting. A clean, minimalist design allows the data—the lines and ranks—to take center stage. In R, we can achieve this by creating a custom theme function. This function encapsulates various theme() arguments, such as background color, grid line removal, and font styling. By defining this once, we can apply it to any chart, ensuring a consistent visual identity across our entire data analysis project.
The custom theme we are building focuses on removing unnecessary clutter. We eliminate the background color, remove the vertical and horizontal grid lines that don’t contribute to the rank interpretation, and adjust the margins to give the plot “room to breathe.” We also focus on typography, ensuring that axis titles and text are bold and appropriately sized for readability. This level of detail distinguishes a casual plot from one suitable for an academic journal or a corporate boardroom. It demonstrates a commitment to information design, where every element on the screen serves a specific purpose.
By using a custom function, we also make our code more modular and easier to read. Instead of repeating twenty lines of theme code for every plot, we simply call my_theme() at the end of our ggplot2 chain. This is a best practice in software engineering applied to data science. The following block of code defines this comprehensive theme, which we will use to transform our “ugly” basic chart into a sophisticated visualization:
my_theme <- function() {
# Colors
color.background = "white"
color.text = "#22211d"
# Begin construction of chart
theme_bw(base_size=15) +
# Format background colors
theme(panel.background = element_rect(fill=color.background,
color=color.background)) +
theme(plot.background = element_rect(fill=color.background,
color=color.background)) +
theme(panel.border = element_rect(color=color.background)) +
theme(strip.background = element_rect(fill=color.background,
color=color.background)) +
# Format the grid
theme(panel.grid.major.y = element_blank()) +
theme(panel.grid.minor.y = element_blank()) +
theme(axis.ticks = element_blank()) +
# Format the legend
theme(legend.position = "none") +
# Format title and axis labels
theme(plot.title = element_text(color=color.text, size=20, face = "bold")) +
theme(axis.title.x = element_text(size=14, color="black", face = "bold")) +
theme(axis.title.y = element_text(size=14, color="black", face = "bold",
vjust=1.25)) +
theme(axis.text.x = element_text(size=10, vjust=0.5, hjust=0.5,
color = color.text)) +
theme(axis.text.y = element_text(size=10, color = color.text)) +
theme(strip.text = element_text(face = "bold")) +
# Plot margins
theme(plot.margin = unit(c(0.35, 0.2, 0.3, 0.35), "cm"))
}Enhancing Clarity with Direct Labels and Clean Layouts
One common pitfall in data visualization is over-reliance on a legend. When a viewer has to constantly look back and forth between a legend and the lines, it increases cognitive fatigue. To make our bump chart more intuitive, we can use direct labeling. This involves placing the team names directly at the start and end of the lines. By doing so, the viewer immediately knows which line belongs to which team. In ggplot2, we achieve this by using the geom_text() function and filtering our data to only include the first and last time points (Day 1 and Day 10).
In addition to labeling, we can further improve the “look and feel” of the chart by adding white centers to our data points. This “donut” effect makes the points pop against the colored lines, creating a more modern and high-end aesthetic. We also use labs() to provide clear, descriptive titles and axis labels. A well-titled chart is essential for data analysis communication, as it provides context and tells the viewer exactly what they should be looking at. By combining these labeling techniques with our custom theme, we create a visualization that is both beautiful and highly functional.
The code below demonstrates how to integrate all these elements. We convert “day” to a factor to ensure discrete spacing on the X-axis and apply the geom_text() layers specifically at the boundaries of the plot. Note how the use of hjust (horizontal adjustment) ensures the text is perfectly aligned outside the main plotting area. This meticulous attention to placement is what makes a bump chart truly effective. Here is the implementation of the styled chart:
ggplot(data, aes(x = as.factor(day), y = rank, group = team)) +
geom_line(aes(color = team, alpha = 1), size = 2) +
geom_point(aes(color = team, alpha = 1), size = 4) +
geom_point(color = "#FFFFFF", size = 1) +
scale_y_reverse(breaks = 1:nrow(data)) +
scale_x_discrete(breaks = 1:10) +
theme(legend.position = 'none') +
geom_text(data = data %>% filter(day == "1"),
aes(label = team, x = 0.5) , hjust = .5,
fontface = "bold", color = "#888888", size = 4) +
geom_text(data = data %>% filter(day == "10"),
aes(label = team, x = 10.5) , hjust = 0.5,
fontface = "bold", color = "#888888", size = 4) +
labs(x = 'Day', y = 'Rank', title = 'Team Ranking by Day') +
my_theme() 
Using Manual Color Scales to Highlight Key Insights
In advanced data analysis, you often want to draw the viewer’s attention to a specific trend or a particular subject of interest. This is known as “focal point” design. Instead of using a different color for every line, which can result in a “spaghetti chart” effect, you can use a manual color scale to highlight one or two lines while muting the others in gray. This technique is incredibly powerful for storytelling with data, as it allows the analyst to say, “Look at Team A’s remarkable recovery,” without the viewer getting lost in the data for Teams B, C, and D.
In ggplot2, the scale_color_manual() function is the primary tool for this task. It allows you to pass a vector of color names or hex codes that correspond to the levels of your grouping variable. By setting most values to “grey” and one to a vibrant color like “purple” or “steelblue,” you instantly transform the chart into a targeted narrative tool. This approach is highly recommended for business intelligence dashboards and presentations where the goal is to drive a specific decision or highlight a specific performance metric.
You can even highlight multiple lines if your analysis requires a comparison between two specific entities. For instance, highlighting both the leader and the most improved team provides a dual narrative. The flexibility of R and ggplot2 makes it trivial to experiment with different color combinations until you find the one that best communicates your findings. Below are the examples of how to apply these manual color scales to your bump chart to create a focused and impactful visualization:
ggplot(data, aes(x = as.factor(day), y = rank, group = team)) +
geom_line(aes(color = team, alpha = 1), size = 2) +
geom_point(aes(color = team, alpha = 1), size = 4) +
geom_point(color = "#FFFFFF", size = 1) +
scale_y_reverse(breaks = 1:nrow(data)) +
scale_x_discrete(breaks = 1:10) +
theme(legend.position = 'none') +
geom_text(data = data %>% filter(day == "1"),
aes(label = team, x = 0.5) , hjust = .5,
fontface = "bold", color = "#888888", size = 4) +
geom_text(data = data %>% filter(day == "10"),
aes(label = team, x = 10.5) , hjust = 0.5,
fontface = "bold", color = "#888888", size = 4) +
labs(x = 'Day', y = 'Rank', title = 'Team Ranking by Day') +
my_theme() +
scale_color_manual(values = c('purple', 'grey', 'grey', 'grey', 'grey'))
ggplot(data, aes(x = as.factor(day), y = rank, group = team)) +
geom_line(aes(color = team, alpha = 1), size = 2) +
geom_point(aes(color = team, alpha = 1), size = 4) +
geom_point(color = "#FFFFFF", size = 1) +
scale_y_reverse(breaks = 1:nrow(data)) +
scale_x_discrete(breaks = 1:10) +
theme(legend.position = 'none') +
geom_text(data = data %>% filter(day == "1"),
aes(label = team, x = 0.5) , hjust = .5,
fontface = "bold", color = "#888888", size = 4) +
geom_text(data = data %>% filter(day == "10"),
aes(label = team, x = 10.5) , hjust = 0.5,
fontface = "bold", color = "#888888", size = 4) +
labs(x = 'Day', y = 'Rank', title = 'Team Ranking by Day') +
my_theme() +
scale_color_manual(values = c('purple', 'steelblue', 'grey', 'grey', 'grey'))
Conclusion: Mastering Bump Charts for Better Data Storytelling
Mastering the creation of bump charts in R using ggplot2 is a significant milestone for any data professional. Through this tutorial, we have explored the entire lifecycle of a visualization project: from initial data manipulation with dplyr to the final aesthetic refinements using custom themes and manual color scales. The result is a highly effective graphic that clarifies the complex dynamics of ranking and competition. By focusing on rank rather than magnitude, you provide your audience with a unique perspective that standard charts often obscure.
The versatility of ggplot2 ensures that the techniques learned here can be applied to a wide variety of datasets and industries. Whether you are visualizing sports statistics, political changes, or market trends, the principles of tidy data and clean design remain the same. As you continue to develop your skills in R, remember that the goal of data visualization is not just to show data, but to provide clarity and insight. A well-constructed bump chart does exactly that, turning a table of numbers into a compelling visual narrative.
In summary, the combination of R and ggplot2 provides an unparalleled environment for creating sophisticated charts. By automating the ranking process and customizing the visual output, you can create professional, reproducible, and beautiful visualizations that stand out in any report or analysis. We encourage you to take these code snippets, apply them to your own datasets, and experiment with the vast array of options available in the Tidyverse to further enhance your data storytelling capabilities.
Cite this article
stats writer (2026). How to Create a Bump Chart in R with ggplot2. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-easily-create-a-bump-chart-in-r-using-ggplot2/
stats writer. "How to Create a Bump Chart in R with ggplot2." PSYCHOLOGICAL SCALES, 2 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-i-easily-create-a-bump-chart-in-r-using-ggplot2/.
stats writer. "How to Create a Bump Chart in R with ggplot2." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-easily-create-a-bump-chart-in-r-using-ggplot2/.
stats writer (2026) 'How to Create a Bump Chart in R with ggplot2', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-easily-create-a-bump-chart-in-r-using-ggplot2/.
[1] stats writer, "How to Create a Bump Chart in R with ggplot2," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Create a Bump Chart in R with ggplot2. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.