Table of Contents
The ecdf() function in R is an indispensable tool for data analysis, providing a robust, non-parametric method for visualizing the probability distribution of a dataset. Specifically, it computes the empirical cumulative distribution function (ECDF), which graphically represents the proportion of observations that fall below or are equal to a specified value. This visual approach offers immediate insights into crucial data characteristics, such as central tendency, spread, and the presence of outliers, making it far more informative than simple histograms in many contexts. Through the use of ECDF, analysts can perform effective statistical analysis, easily comparing the underlying distributions of multiple datasets or checking for compliance with theoretical distributions. Utilizing the ecdf() function is a fundamental step toward gaining a comprehensive understanding of a dataset’s inherent structure and distribution.
Use ecdf() Function in R
The Theoretical Basis: What is the ECDF?
The Empirical Cumulative Distribution Function (ECDF) serves as an estimate of the true underlying cumulative distribution function (CDF) of the population from which the data sample was drawn. Unlike parametric distribution methods that require assumptions about the shape of the data (e.g., normality), the ECDF is derived directly from the observed data points. For any given value x, the ECDF represents the fraction of observations in the sample that are less than or equal to x. This function is defined as a step function, which increases only at the observed data points, making it a powerful non-parametric diagnostic tool.
In practice, the ECDF provides a complete summary of the dataset’s distribution, offering advantages over traditional summaries like histograms. While a histogram groups data into bins, potentially obscuring fine details, the ECDF maintains the integrity of every data point. This makes it particularly valuable when analyzing datasets that may be skewed, multimodal, or contain unusual observations that could bias parametric models. Understanding the ECDF is central to performing robust exploratory data analysis, particularly when the distributional assumptions required for other tests cannot be met or verified.
Syntax and Core Usage of ecdf() in R
The R programming language provides the dedicated ecdf() function for calculating the ECDF based on a numeric vector of data. The function takes the data vector as its sole argument and returns an object of class "ecdf", which is itself a function closure. This resulting function can then be called with specific values to determine the estimated cumulative probability at those points, or, more commonly, it is passed to the plot() function for immediate visualization.
When generating the ECDF, the process is straightforward: first, you calculate the function object, and second, you plot that object. This two-step process allows for maximum flexibility, enabling users to apply the calculated ECDF object to further statistical procedures, such as two-sample Kolmogorov–Smirnov tests, if required. Here is the fundamental method for calculating and plotting the ECDF using the ecdf() function in R:
# calculate empirical cumulative distribution function of data p = ecdf(data) # plot empirical cumulative distribution function plot(p)
Practical Example: Setting Up the Data
To demonstrate the utility of the ecdf() function, we will generate a synthetic dataset consisting of 1,000 observations. For illustrative purposes, we will ensure that these values follow a standard normal distribution, which is characterized by a mean of zero and a standard deviation of one. By using the rnorm() function, we can efficiently simulate this common data pattern, creating a suitable environment for applying the ECDF and comparing it against theoretical expectations.
It is best practice in R to utilize the set.seed() function before generating random numbers. This ensures that the generated sequence of random values is reproducible, meaning anyone running the exact same code will obtain identical results. This step is critical for ensuring the transparency and verifiability of statistical examples and analyses. We then create our data vector and inspect the initial values using the head() function to confirm successful generation.
# make this example reproducible set.seed(1)# create vector of 1,000 random values that follow standard normal distribution data = rnorm(1000) # view first six values in vector head(data) [1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078 -0.8204684
Step-by-Step Implementation and Visualization
Once the data vector is prepared, the visualization of the ECDF requires only two simple commands. We begin by invoking the ecdf() function, passing our data vector to it. The result is stored in an object named p. This object p is the actual empirical distribution function itself, ready to be plotted. Note that the object p is not merely a list of coordinates but a functional representation which can be evaluated at any arbitrary point within the domain of the data.
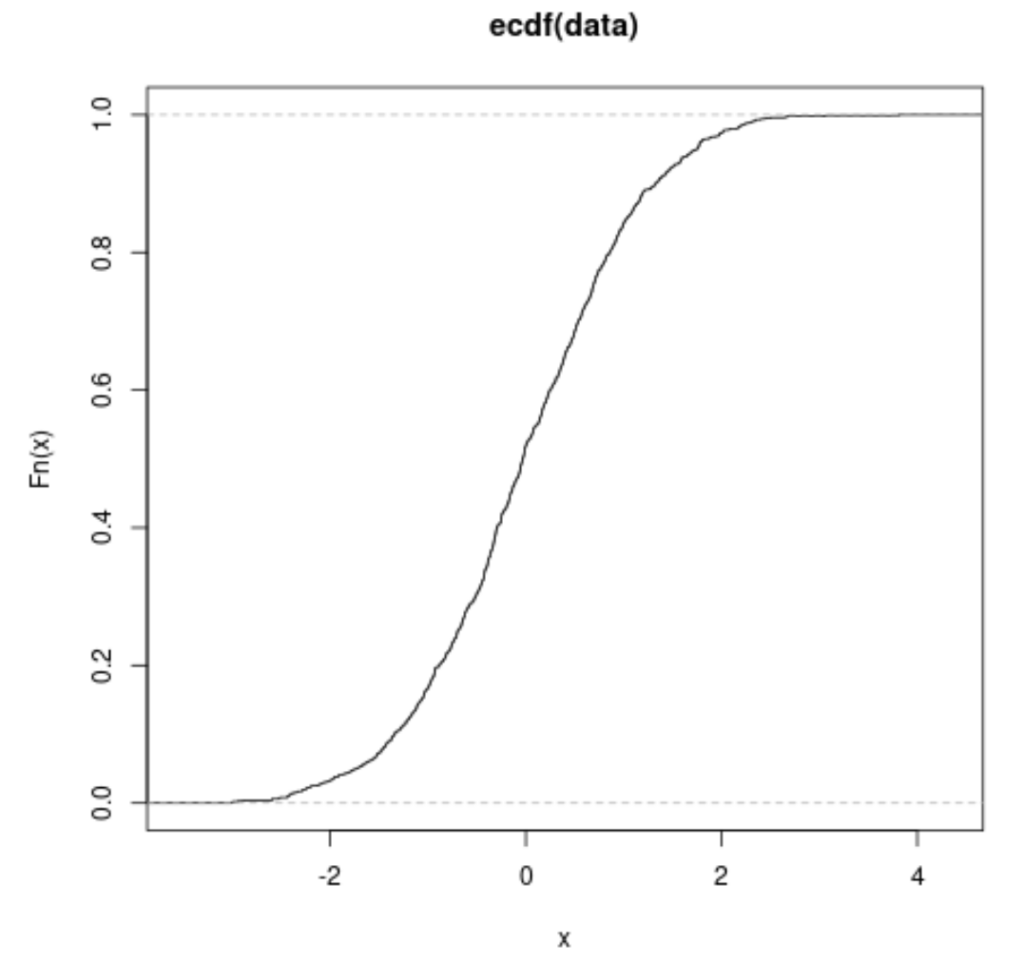
The subsequent step involves calling the generic plot() function, using the ECDF object p as the argument. R automatically recognizes the class of the object and generates the characteristic step-function plot associated with the ECDF. This visualization immediately presents the cumulative probability of the dataset, illustrating how the probability accumulates across the range of the observed values. The resulting plot clearly shows the shape and characteristics of the distribution, providing a visual assessment of centrality and spread.
# calculate empirical cumulative distribution function of data p = ecdf(data) # plot empirical cumulative distribution function plot(p)

Customizing the ECDF Plot for Clarity
While the basic ECDF plot generated by the plot(p) command is functional, customizing the visual output is crucial for producing presentation-quality graphics and ensuring the plot is easily understood by an audience. The plot() function in R allows for the inclusion of standard graphical parameters, such as axis labels and a main title, which significantly enhance the plot’s interpretability. These parameters are passed as additional arguments to the function call, overriding the default generic labels.
Specifically, the xlab argument is used to define the label for the x-axis (typically representing the variable values), the ylab argument sets the label for the y-axis (representing the cumulative probability), and the main argument provides a descriptive title for the overall plot. Utilizing these options ensures that the graph communicates its content clearly and effectively, adhering to standards of rigorous data visualization practices, particularly when included in reports or academic papers.
# calculate empirical cumulative distribution function of data p = ecdf(data) # plot empirical cumulative distribution function with axis labels and title plot(p, xlab='x', ylab='CDF', main='CDF of Data')

Interpreting the Empirical Cumulative Distribution Function
Understanding the structure of the ECDF plot is essential for extracting meaningful insights from the data. The plot maps the observed values of the dataset against their corresponding cumulative probabilities. Specifically, the horizontal axis (x-axis) represents the actual data values, ranging from the minimum to the maximum observation in the sample. The vertical axis (y-axis) represents the cumulative probability, starting at 0 and rising monotonically to 1, as all probabilities must be non-negative and sum up to one.
The step function nature of the ECDF means that the height of the function at any point x indicates the proportion of data points that are less than or equal to x. For example, if the ECDF plot reaches 0.5 at an x-value of 0, this signifies that 50% of the data points are less than or equal to 0 (which is expected for a dataset following a centralized, symmetric distribution like the standard normal distribution). The steepness of the steps indicates the density of the data at that location; steeper rises suggest a higher concentration of values clustered around those points, while flatter regions indicate sparser data.
The x-axis displays the values from the dataset.
The y-axis displays the cumulative distribution function.
Advantages of Using ECDF for Data Analysis
The use of the ECDF in R provides several analytical advantages over other distributional summaries. Because it is non-parametric, the ECDF does not impose any rigid assumptions about the underlying population distribution, making it exceptionally robust when dealing with real-world data that often violate ideal theoretical conditions such as perfect normality. This capability allows researchers to rely on the observed sample characteristics directly, leading to more trustworthy exploratory results before committing to complex inferential models.
Furthermore, ECDF plots are exceptionally useful for comparing two or more samples, a core task in comparative statistical analysis. By plotting the ECDFs of different groups on the same graph, analysts can visually assess differences in location (e.g., median), scale (e.g., variance), and overall shape without complex statistical metrics. If one ECDF is consistently above another throughout the plot, it provides strong visual evidence that one dataset is stochastically smaller than the other. This visual comparison method is often clearer and more intuitive than comparing overlapping histograms or relying solely on summary statistics.
Further Resources for R Statistical Functions
To deepen your expertise in R and statistical visualization, exploring related functions, particularly those concerning the normal distribution and hypothesis testing, is highly recommended. These resources provide context for how the ECDF fits into a broader framework of data analysis tools, linking exploratory graphics to formal testing procedures.
Related:
How to Plot a Normal Distribution in R
A Guide to dnorm, pnorm, qnorm, and rnorm in R
How to Perform a Shapiro-Wilk Test for Normality in R
Cite this article
stats writer (2026). How to Plot and Interpret Data Distributions Using the ECDF Function in R. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-the-ecdf-function-be-used-in-r-to-analyze-data/
stats writer. "How to Plot and Interpret Data Distributions Using the ECDF Function in R." PSYCHOLOGICAL SCALES, 31 Jan. 2026, https://scales.arabpsychology.com/stats/how-can-the-ecdf-function-be-used-in-r-to-analyze-data/.
stats writer. "How to Plot and Interpret Data Distributions Using the ECDF Function in R." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-the-ecdf-function-be-used-in-r-to-analyze-data/.
stats writer (2026) 'How to Plot and Interpret Data Distributions Using the ECDF Function in R', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-the-ecdf-function-be-used-in-r-to-analyze-data/.
[1] stats writer, "How to Plot and Interpret Data Distributions Using the ECDF Function in R," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, January, 2026.
stats writer. How to Plot and Interpret Data Distributions Using the ECDF Function in R. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.