
Table of Contents
The study of quantitative data is fundamental in statistics. When analyzing a dataset, researchers must first understand how the values are organized—their distribution. To ensure comprehensive description and analysis, the acronym SOCS is widely employed as a mnemonic device. SOCS represents the four critical characteristics necessary for fully describing any data distribution: Shape, Outliers, Center, and Spread.
By systematically addressing these four components, analysts can gain profound insight into the underlying dataset, moving beyond simple numerical summaries to a richer qualitative and quantitative understanding. Utilizing the SOCS framework ensures that no crucial aspect of the data’s structure is overlooked, providing a standardized method for communicating statistical findings effectively.
The Four Pillars of Data Description: S-O-C-S
Understanding a statistical distribution requires a multi-faceted approach. These four key elements—Shape, Outliers, Center, and Spread—are intrinsically linked and provide a complete picture of the data’s behavior. Before diving into an application, it is beneficial to detail exactly what each component demands of the statistical analyst.
We must address the structure of the data, the presence of unusual observations, the typical value, and the variability present within the sample. These comprehensive details allow for informed hypothesis testing and accurate predictive modeling.
S: Shape. The shape describes the pattern of the distribution when visualized, often using a histogram or box plot. Key considerations involve symmetry and modality.
- Does the distribution appear roughly symmetrical, or is it skewed (leaning) towards the positive or negative end?
- How many distinct peaks (modes) are visible? Is the distribution unimodal (one peak) or bimodal (two peaks)?
O: Outliers. Outliers are data points that significantly deviate from other observations. Identifying them is crucial because they can disproportionately influence measures of center, such as the mean, and measures of spread, such as the standard deviation.
- Are there any unusually large or small values present in the distribution that warrant further investigation or specialized treatment?
C: Center. The center refers to the typical, middle, or central value of the dataset. This measure provides a summary statistic that best represents the distribution as a whole.
- The three primary measures of central tendency typically assessed are the mean (average), median (middle value), and mode (most frequent value).
S: Spread. Spread, or variability, describes how dispersed or tightly clustered the data points are relative to the center. A larger spread indicates greater heterogeneity in the dataset.
- WCrucial measures of dispersion include the range, the interquartile range (IQR), the standard deviation, and the variance of the distribution.
The SOCS acronym serves as a robust framework for descriptive statistics. We will now apply this systematic approach to a practical example involving plant height data to demonstrate its utility in real-world statistical analysis.
Applying the SOCS Framework to a Sample Dataset
To illustrate the practical application of the SOCS methodology, consider a dataset collected from an agricultural study. This dataset represents the height, measured in centimeters, of a sample of 20 distinct plant specimens. Thoroughly describing this distribution is the first step in determining the efficacy of the growth conditions or identifying genetic uniformity within the sample.
The raw data values are presented below. Our goal is to systematically analyze these 20 observations using the four components of SOCS to generate a complete statistical profile.

We proceed sequentially through the acronym, beginning with an assessment of the visual structure of the dataset.
S: Analyzing the Distribution Shape
The first step in describing the distribution is to visualize and characterize its shape. Graphical representations, such as the histogram below, are indispensable tools for this assessment, allowing us to immediately identify patterns of frequency across the range of plant heights.

When assessing symmetry, we determine if the distribution could be folded in half, resulting in mirror images. Observing the histogram, the data points show a relatively balanced spread around the central peak. Although there is a slight extension to the right due to the high values, the bulk of the data suggests that the distribution is generally roughly symmetrical. This implies that the frequencies decrease similarly on both sides of the center, meaning the values are not heavily concentrated or skewed towards either the lower or upper tails.
Next, we analyze modality, which relates to the number of prominent peaks present. A unimodal distribution has one clear frequency maximum. In this case, the distribution clearly exhibits a single, dominant peak occurring around the height of 7 cm. Therefore, we classify this distribution as unimodal. The identification of a single mode suggests a homogeneous population in terms of plant height, without evidence of two separate, distinct subgroups.
O: Identifying Potential Outliers
The second component of SOCS requires us to investigate the presence of outliers—extreme values that may skew the interpretation of the dataset. A preliminary visual inspection of the plant height histogram immediately reveals a single data point significantly separated from the main cluster of observations. This value is 22 cm, which visually appears far removed from the general concentration between 4 cm and 11 cm.
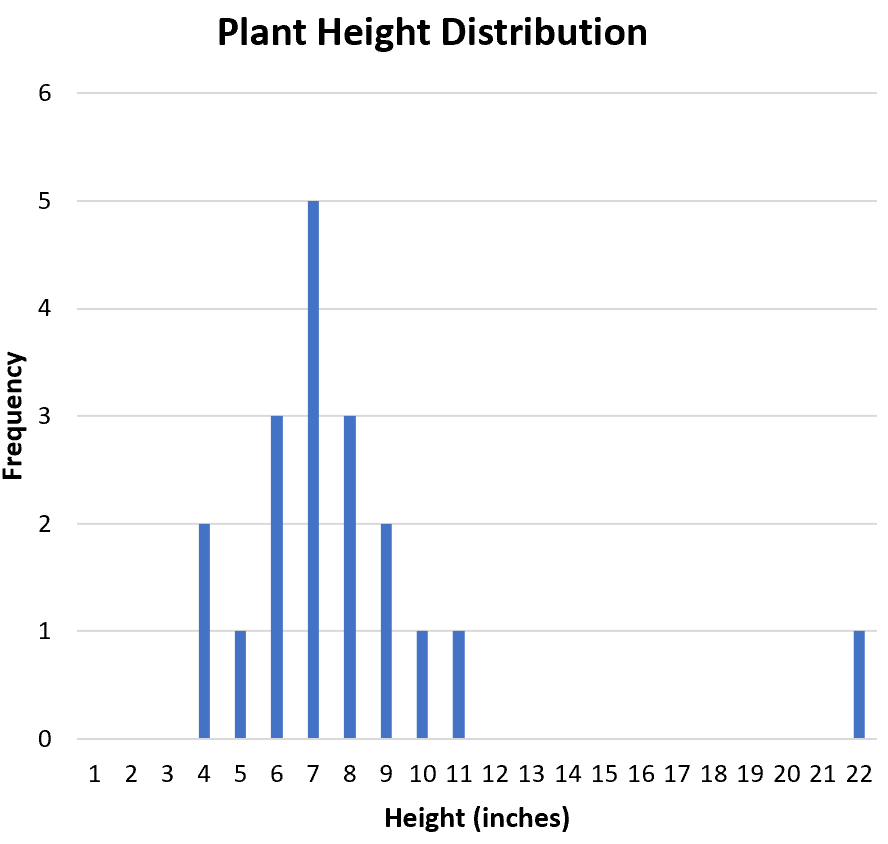
To formally confirm if 22 is an outlier, we employ the standard statistical criterion based on the Interquartile Range (IQR). The IQR method defines an outlier as any value falling outside the calculated fences: $Q_1 – 1.5 times IQR$ (lower fence) or $Q_3 + 1.5 times IQR$ (upper fence). Calculating the quartiles for our 20 data points, we find that the first quartile ($Q_1$) is 6 and the third quartile ($Q_3$) is 9. This results in an Interquartile Range of $9 – 6 = 3.
We calculate the upper fence: $Q_3 + 1.5 times IQR = 9 + (1.5 times 3) = 9 + 4.5 = 13.5$. Since the observed height of 22 cm is significantly greater than the upper fence of 13.5 cm, we confidently declare that 22 is a statistically defined outlier. Recognizing and addressing outliers is critical, as their inclusion often compromises the representativeness of summary statistics like the mean.
C: Locating the Measures of Central Tendency
Describing the center involves identifying the typical or representative value of the dataset. For this plant height distribution, we calculate three standard measures of central tendency: the mean, the median, and the mode. Analyzing all three provides a more nuanced understanding, especially when dealing with distributions that are not perfectly symmetrical.
Calculating the Mean: The mean is the arithmetic average, calculated by summing all 20 observations and dividing by the count (N=20). The sum of all plant heights is 157. Therefore, the Mean = (8+4+6+7+7+6+7+8+6+11+8+22+10+9+9+7+5+7+6+4) / 20 = 7.85. It is important to note that the mean is highly sensitive to the outlier (22), which tends to pull the mean towards the higher end of the scale.
Calculating the Median: The median is the value that separates the upper half of the data from the lower half. Since we have an even number of data points (20), the median is the average of the 10th and 11th values after sorting the data:
4, 4, 5, 6, 6, 6, 6, 7, 7, 7, 7, 7, 8, 8, 8, 9, 9, 10, 11, 22
The 10th and 11th values are both 7, thus the Median = (7 + 7) / 2 = 7. Because the median relies only on the positional order of the data, it is a robust statistic that is less affected by the presence of the outlier compared to the mean.
Identifying the Mode: The mode is the value that appears most frequently in the distribution. By inspecting the raw data or the histogram, we observe that the value 7 occurs five times, more than any other height measurement. Thus, the Mode is 7. The closeness of the median (7) and the mode (7) supports the earlier observation that the distribution is relatively symmetrical, even though the mean (7.85) is slightly elevated due to the extreme value.
S: Quantifying the Spread and Variability
The final component of SOCS is Spread, which quantifies the variability or dispersion within the plant height measurements. We utilize several measures of dispersion to understand how tightly or loosely the data points are clustered around the center.
Range: The range is the simplest measure, calculated as the difference between the maximum and minimum values in the dataset. Maximum value (22) minus Minimum value (4) yields a Range of $22 – 4 = 18$. While easy to calculate, the range is highly susceptible to the influence of outliers, as demonstrated here where the single outlier of 22 drastically increases the overall range.
Interquartile Range (IQR): The Interquartile Range (IQR) provides a robust measure of spread, focusing solely on the middle 50% of the data. Since we calculated $Q_3 = 9$ and $Q_1 = 6$, the IQR is $9 – 6 = 3$. This value of 3 indicates that the central half of the plant heights spans a relatively small interval, suggesting good uniformity among the majority of the plants.
Standard Deviation (SD) and Variance: The Standard Deviation is perhaps the most critical measure of spread, representing the typical distance of any given observation from the mean. Calculated across the entire sample, the standard deviation is found to be 3.69. Closely related is the Variance, which is simply the square of the standard deviation. Variance is equal to $3.69^2 approx 13.63$. Both the SD and Variance, like the mean, are sensitive to the outlier of 22, which contributes significantly to their magnitudes.
Synthesis of Findings: The Complete SOCS Profile
By diligently applying the SOCS framework, we have successfully generated a comprehensive descriptive summary of the plant height distribution. This systematic documentation moves beyond simple data lists to provide critical insights necessary for advanced statistical inference.
The key findings regarding the distribution of the 20 plant heights are summarized below:
- Shape: The distribution is characterized as unimodal and roughly symmetrical, indicating a single population whose values are distributed fairly evenly around the central tendency.
- Outliers: A single, high-leverage outlier was formally identified at the value of 22 cm, significantly distant from the majority of observations.
- Center: The primary measures of center were found to be Mean = 7.85, Median = 7, and Mode = 7. The difference between the mean and the median (0.85) highlights the influential effect of the outlier.
- Spread: Measures of variability include the Range = 18, the robust Interquartile Range (IQR) = 3, the Standard Deviation (SD) = 3.69, and the Variance = 13.63.
The SOCS mnemonic proves invaluable as a checklist for describing any quantitative data distribution. Whether dealing with test scores, economic indicators, or biological measurements, this standardized approach ensures all essential descriptive components—structure, extreme values, typical location, and variability—are fully addressed, leading to clear, reproducible, and authoritative statistical reporting.
Cite this article
stats writer (2025). How to Describe Data Distributions Using the SOCS Acronym. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/socs-a-helpful-acronym-for-describing-distributions/
stats writer. "How to Describe Data Distributions Using the SOCS Acronym." PSYCHOLOGICAL SCALES, 29 Dec. 2025, https://scales.arabpsychology.com/stats/socs-a-helpful-acronym-for-describing-distributions/.
stats writer. "How to Describe Data Distributions Using the SOCS Acronym." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/socs-a-helpful-acronym-for-describing-distributions/.
stats writer (2025) 'How to Describe Data Distributions Using the SOCS Acronym', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/socs-a-helpful-acronym-for-describing-distributions/.
[1] stats writer, "How to Describe Data Distributions Using the SOCS Acronym," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Describe Data Distributions Using the SOCS Acronym. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.