
Table of Contents
The Pearson Correlation Coefficient (r), often referred to as Pearson’s r, is one of the most fundamental statistics used in quantitative research. It provides a measure of the linear association between two continuous variables. However, merely calculating this coefficient is only the first step; to understand if this observed relationship is statistically meaningful or simply due to random chance, researchers rely on a crucial reference guide: the Pearson Correlation Table.
This authoritative resource, formally known as the Critical Values Table for Pearson’s r, acts as the gatekeeper for drawing statistical conclusions. It allows the researcher to compare their calculated correlation statistic against established benchmarks, known as critical values. The ultimate goal is to determine if the calculated correlation is strong enough, given the sample size and the accepted level of risk, to reject the null hypothesis (H0), which invariably posits that there is no true linear relationship between the two variables in the underlying population.
Mastering the use of this table transforms raw statistical output into actionable scientific inference. It is essential not just for academic researchers but also for data analysts and anyone involved in inferential statistics. This detailed guide will explore the mechanics of Pearson’s r, delve into the theoretical foundation of critical values, and provide an exhaustive, step-by-step methodology for correctly utilizing this powerful table in various hypothesis testing scenarios, ensuring rigorous and valid data interpretation.
Understanding the Pearson Correlation Coefficient (r)
Before engaging with the table, a thorough understanding of the Pearson Correlation Coefficient itself is mandatory. Pearson’s r is a parametric statistic, meaning it assumes the data is interval or ratio, and often assumes that the relationship is approximately linear and the data is normally distributed. The value of r always falls between -1.0 and +1.0. A value close to +1.0 indicates a strong positive linear relationship, where as one variable increases, the other also increases proportionally. Conversely, a value near -1.0 signifies a strong negative linear relationship, where an increase in one variable corresponds to a proportional decrease in the other.
The magnitude of r reflects the strength of the linear relationship. An r value close to 0 suggests a weak or nonexistent linear relationship. It is crucial to remember that Pearson’s r only captures linear associations; if the relationship between the variables is non-linear (e.g., curvilinear or quadratic), r may be misleadingly close to zero even if a strong relationship exists. Therefore, researchers must always visually inspect scatter plots of the data before relying solely on the numerical output of r.
The formal calculation of r involves dividing the covariance of the two variables by the product of their standard deviations. This normalization process ensures that the coefficient is unitless and standardized, allowing for comparisons across different datasets and variables measured on different scales. Once calculated, this sample statistic, denoted as r, needs to be evaluated against the known distribution of r under the null hypothesis. This comparison is precisely what the Critical Values Table facilitates, allowing the transition from descriptive statistics (the calculated r) to inferential statistics (determining its statistical significance).
The Purpose and Critical Value Concept
The fundamental purpose of the Pearson Correlation Table is to address sampling variability. When we draw a sample from a population, the correlation we observe (r) is unlikely to be exactly zero, even if the true correlation in the entire population (denoted as rho, $rho$) is zero. The critical value provides a threshold: the minimum absolute value that the calculated sample correlation (r) must attain in order to be considered sufficiently rare under the assumption that the null hypothesis ($rho = 0$) is true.
The concept of the critical value is intrinsically tied to the chosen significance level ($alpha$). Alpha represents the maximum probability the researcher is willing to accept of making a Type I Error—that is, incorrectly rejecting the null hypothesis when it is actually true (a false positive). Commonly used alpha levels are $alpha = 0.05$ (5%) or $alpha = 0.01$ (1%). When using the table, the critical value corresponding to, say, $alpha = 0.05$, defines the boundaries of the rejection region. If the absolute value of the calculated r falls outside these boundaries (i.e., is greater than the critical value), it is deemed significant at that 5% level of risk.
The critical values listed in the table are derived from the theoretical sampling distribution of the correlation coefficient, which is complex but often approximated by the t-distribution, especially when the sample size is small. For any given combination of sample size (or more accurately, the degrees of freedom) and alpha level, the critical value ensures that only correlations that occur in the extreme tails of the distribution—those that are statistically improbable if the population correlation were zero—will lead to the rejection of the null hypothesis. This rigorous standard helps maintain the integrity of statistical inference.
Key Components of the Critical Value Table
To accurately look up a critical value, a researcher must identify two primary variables that structure the Pearson Correlation Table. These components dictate the shape and spread of the sampling distribution and therefore determine the appropriate threshold for significance. The first crucial component is the degrees of freedom (df), which is directly related to the sample size (n). For Pearson’s r, the degrees of freedom are calculated as $df = n – 2$, where $n$ is the number of paired observations analyzed. Subtracting two accounts for the fact that two parameters (the means of the two variables) must be estimated from the sample data to calculate the correlation.
The second essential component is the predetermined significance level ($alpha$), which reflects the risk tolerance for Type I error. The table typically organizes critical values into columns corresponding to different $alpha$ levels, such as 0.10, 0.05, 0.02, and 0.01. Furthermore, these columns are usually split based on whether the researcher is conducting a one-tailed or a two-tailed test. In a two-tailed test, the $alpha$ value is split between both the positive and negative tails of the distribution (e.g., 0.025 in each tail for $alpha = 0.05$). The critical value found at the intersection of the appropriate df row and the chosen $alpha$ column represents the boundary line. Any calculated r (in absolute terms) exceeding this number is rare enough to warrant statistical attention.
Understanding the interplay between these two components is vital. As the degrees of freedom (and thus the sample size) increase, the distribution of r becomes narrower and more peaked, meaning smaller calculated correlation values are required to achieve significance. Conversely, as the chosen $alpha$ level decreases (e.g., moving from 0.05 to the stricter 0.01), the critical value increases, requiring a stronger observed correlation to reject the null hypothesis. This inverse relationship highlights the principle that larger samples provide greater statistical power, while lower alpha levels increase the confidence in the rejection decision but make the rejection itself harder to achieve.
- This table presents critical values for the Pearson correlation coefficient (r) based on two factors:
- Sample size (n) / Degrees of Freedom (df): The number of pairs of data points you analyzed, which determines the degrees of freedom ($df = n – 2$).
- Significance level ($alpha$): The probability of rejecting the null hypothesis (H0) when it’s actually true, typically set at 0.05 (5%) or 0.01 (1%).
Step-by-Step Guide: Utilizing the Critical Value Table
The process of determining statistical significance using the critical value table is systematic and follows a clear sequence of steps. Initially, the researcher must clearly define the null hypothesis ($H_0$: $rho = 0$) and the alternative hypothesis ($H_a$: $rho neq 0$ for a two-tailed test, or $H_a$: $rho > 0$ or $rho < 0$ for a one-tailed test). This forms the theoretical framework for the subsequent statistical calculations and comparisons.
The next critical step involves the calculation of the sample Pearson Correlation Coefficient, $r$, using the collected paired data points, $n$. Simultaneously, the degrees of freedom ($df = n – 2$) must be determined. This df value guides the researcher to the correct row in the critical value table. Once the df is located, the researcher selects the column corresponding to their pre-determined significance level ($alpha$), ensuring they use the appropriate set of values for either a one-tailed or two-tailed test, depending on the research question.
The final step is the comparison phase. The calculated value of $r$ is compared against the identified critical value from the table. If the absolute value of $r$ ($|r|$) is equal to or greater than the critical value, the researcher rejects the null hypothesis. This rejection implies that the observed linear relationship is unlikely to have occurred by chance alone, suggesting that the correlation is statistically significant. If $|r|$ is less than the critical value, the null hypothesis is retained, indicating insufficient evidence within the sample to claim a significant linear association at the chosen risk level.
Calculate your Pearson correlation coefficient (r): This statistic precisely measures the strength and direction of the linear relationship between your two variables. Ensure the underlying assumptions for parametric testing are reasonably met.
Determine Degrees of Freedom (df) and Significance Level ($alpha$): Locate the correct row using $df = n – 2$ and identify the appropriate column based on your chosen $alpha$ (e.g., 0.05 or 0.01) and whether the test is one-tailed or two-tailed.
Compare your calculated r to the critical value: The critical value acts as the threshold. If the absolute value of your calculated $r$ is greater than or equal to the critical value, the result is deemed statistically significant.
Navigating One-Tailed vs. Two-Tailed Hypothesis Testing
Hypothesis testing can be directional (one-tailed) or non-directional (two-tailed), and this choice dramatically affects how the critical value table is utilized. A two-tailed test is employed when the researcher is interested in detecting a significant correlation regardless of its direction—that is, whether it is significantly positive or significantly negative. The alternative hypothesis simply states that the correlation is not zero ($H_a: rho neq 0$). In this scenario, the total $alpha$ risk is split equally between the two tails of the sampling distribution, which means the critical value is drawn from the column labeled with the full $alpha$ (e.g., 0.05 for a standard test) under the two-tailed heading.
A one-tailed test, conversely, is used when the researcher has a strong theoretical or empirical reason to predict the specific direction of the relationship (e.g., $H_a: rho > 0$ or $H_a: rho < 0$). This approach is more statistically powerful because the entire $alpha$ risk is placed into only one tail of the distribution. When using the standard critical value table that is often indexed by two-tailed $alpha$ levels, the researcher must look up the critical value in the column corresponding to $2alpha$ of their chosen one-tailed risk. For instance, if a researcher selects $alpha = 0.05$ for a one-tailed test, they must look in the column labeled $alpha = 0.10$ (two-tailed) to find the correct, less stringent critical value.
The interpretation of the rejection criteria also differs based on the tail choice. For a two-tailed test, we reject $H_0$ if $r$ is outside the range defined by $pm$ the critical value. For a one-tailed test, the rejection rule is stricter regarding direction but easier regarding magnitude: we reject $H_0$ only if the sign of the calculated $r$ matches the predicted direction and its magnitude meets or exceeds the critical value obtained from the table. If the calculated $r$ has the wrong sign, $H_0$ is automatically retained, irrespective of the magnitude, because the data fails to support the specific directional hypothesis.
- Two-tailed test: If your calculated $r$ is greater than or equal to the critical value in absolute value ($|r| ge r_{critical}$), reject the null hypothesis ($H_0$) and conclude that there is a statistically significant correlation between the variables.
- One-tailed test: If you predict a positive correlation, reject $H_0$ if $r$ is greater than or equal to the adjusted critical value. If you predict a negative correlation, reject $H_0$ if $r$ is less than or equal to the negative adjusted critical value. The adjustment involves using the critical value corresponding to double your chosen $alpha$ in the two-tailed columns.
Interpreting Statistical Significance and Effect Size
Once the comparison against the critical value is complete and a decision is made to either reject or retain the null hypothesis, the researcher must shift focus to interpreting the results. If $H_0$ is rejected, the correlation is deemed to possess statistical significance, meaning there is strong evidence that a non-zero linear relationship exists in the population. However, it is fundamentally important to distinguish statistical significance from practical significance or effect size. A very large sample size ($n$) can make even a tiny, practically meaningless correlation coefficient achieve statistical significance, simply because large $n$ leads to very small critical values.
The calculated Pearson Correlation Coefficient ($r$) itself serves as the measure of effect size. Standard guidelines (often attributed to Cohen) suggest general benchmarks for interpreting the magnitude: $r = 0.10$ is considered a small effect, $r = 0.30$ a medium effect, and $r = 0.50$ or greater a large effect. A strong correlation (closer to $pm 1$) indicates that the data points closely cluster around the regression line, suggesting that the independent variable is a powerful linear predictor of the dependent variable. The interpretation should always include squaring the correlation coefficient ($r^2$), which represents the coefficient of determination—the proportion of variance in one variable that can be explained by the variance in the other variable.
Conversely, if the calculated $r$ falls within the non-rejection region (i.e., $|r| < r_{critical}$), the result is non-significant. This outcome does not definitively prove that no correlation exists ($rho = 0$), but rather suggests that the evidence gathered from the specific sample size was insufficient to confidently reject the null hypothesis at the chosen significance level. In this case, researchers might consider issues of statistical power or limitations related to sample size before concluding that no relationship exists. A careful analysis of both the r value and the p-value (which modern software often provides directly, bypassing the need for the table) is necessary for a robust conclusion.
- The closer your calculated $r$ is to 1 or -1, the stronger the positive or negative correlation, respectively, indicating a larger effect size and a greater proportion of shared variance ($r^2$).
- A non-significant result ($r$ falls within the range defined by the critical values) doesn’t necessarily mean no correlation exists. It suggests that the sample evidence is not strong enough (perhaps due to small sample size or high data variability) to statistically claim a relationship exists in the broader population at the chosen $alpha$ level.
Limitations and Caveats of the Pearson Correlation Coefficient
While the Pearson Correlation Table and the associated hypothesis test provide a powerful framework for assessing linear relationships, researchers must remain cognizant of the inherent limitations of the statistic. First and foremost, Pearson’s r is highly sensitive to outliers. A single extreme data point can dramatically inflate or deflate the calculated coefficient, potentially leading to an incorrect conclusion regarding significance or strength. Researchers should always conduct exploratory data analysis, including scatter plots and descriptive statistics, to identify and properly handle such anomalies before relying on the numerical output.
Furthermore, reliance on the Pearson test assumes that the relationship being modeled is fundamentally linear. If the underlying data exhibits a curvilinear pattern—for example, a relationship that increases up to a point and then decreases—the calculated r value may be near zero, misleadingly suggesting no relationship, when in fact a very strong non-linear association exists. In such cases, non-parametric measures like Spearman’s rho, or advanced modeling techniques, are more appropriate. The hypothesis test facilitated by the critical value table only addresses the presence of a linear component.
The most crucial caveat in correlation analysis is the principle that correlation does not imply causation. Even if a correlation is statistically significant and represents a large effect size (e.g., $r = 0.90$), it only confirms that the two variables change together in a predictable pattern. It provides no information about which variable, if either, is causing the change in the other, or if both variables are being influenced by a third, unmeasured confounding variable. A statistically significant correlation merely justifies further, more sophisticated causal inference studies, but should never be presented as proof of a causal link in isolation.
Summary of Critical Values for Pearson’s r
The following image provides a classic example of what a Critical Values Table for Pearson’s r typically presents. Researchers use this structure to match their degrees of freedom ($n-2$) against their desired two-tailed significance level ($alpha$) to find the threshold necessary to reject the null hypothesis in their study. Understanding how to navigate this table is a cornerstone of applying inferential statistics correctly to correlation analysis.
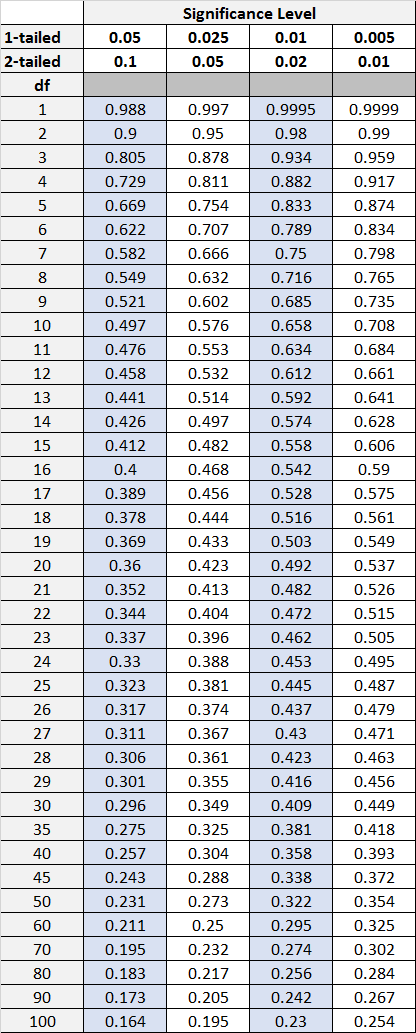
In conclusion, the Pearson Correlation Table remains an indispensable tool in statistics, offering a structured, reliable method for moving beyond mere descriptive data toward robust inferential claims. By carefully considering sample size, degrees of freedom, the chosen hypothesis testing approach (one-tailed or two-tailed), and the acceptable risk level ($alpha$), analysts can confidently determine whether an observed linear correlation possesses the requisite statistical significance to be reported as a genuine finding.
Cite this article
Mohammed looti (2026). How to Use a Pearson Correlation Table to Determine Statistical Significance. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/pearson-correlation-table/
Mohammed looti. "How to Use a Pearson Correlation Table to Determine Statistical Significance." PSYCHOLOGICAL SCALES, 4 Jan. 2026, https://scales.arabpsychology.com/stats/pearson-correlation-table/.
Mohammed looti. "How to Use a Pearson Correlation Table to Determine Statistical Significance." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/pearson-correlation-table/.
Mohammed looti (2026) 'How to Use a Pearson Correlation Table to Determine Statistical Significance', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/pearson-correlation-table/.
[1] Mohammed looti, "How to Use a Pearson Correlation Table to Determine Statistical Significance," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, January, 2026.
Mohammed looti. How to Use a Pearson Correlation Table to Determine Statistical Significance. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.