Table of Contents
Introduction to the Dual Pillars of Statistical Analysis
In the contemporary landscape of data science and research, the terms statistical significance and practical significance frequently appear in academic journals, business reports, and clinical trial summaries. While these concepts are intrinsically linked through the process of statistical inference, they represent fundamentally different perspectives on data interpretation. Professionals often conflate the two, assuming that a mathematically significant result automatically translates into a meaningful real-world impact. However, understanding the nuance between these two metrics is critical for making informed decisions that transcend mere numerical patterns.
Statistical significance acts as a mathematical gatekeeper, primarily concerned with the reliability of a result and the probability that an observed effect occurred by something other than random chance. It relies heavily on rigorous mathematical frameworks and probability distributions to determine if a specific data set deviates enough from the expected norm to be considered “real.” In contrast, practical significance shifts the focus from the theoretical to the tangible. It asks whether the observed difference, regardless of its mathematical certainty, is large enough to justify changes in policy, investments in new technology, or modifications to medical treatments.
The tension between these two concepts often arises during large-scale studies where even the most minute differences can be labeled as “statistically significant.” Without a framework for assessing practical relevance, organizations risk allocating vast resources to implement changes that yield negligible improvements. Conversely, a failure to achieve statistical significance does not always mean an effect is absent; it may simply mean the study lacked the statistical power to detect it. Consequently, a comprehensive analysis requires a balanced evaluation of both the mathematical evidence and the contextual utility of the findings.
This article provides an in-depth exploration of the mechanisms driving both forms of significance. We will examine the foundational elements of hypothesis testing, the mathematical influence of variance and sample size, and the indispensable role of subject matter expertise in determining when a result truly matters. By the end of this discussion, readers will possess a structured understanding of how to interpret research findings with both mathematical precision and practical wisdom.
Defining the Statistical Hypothesis and Population Parameters
To grasp the difference between statistical and practical significance, one must first understand the building blocks of inferential statistics: the statistical hypothesis and the population parameter. A population parameter is a numerical value that describes a specific characteristic of an entire population. For instance, if a researcher is studying the average income of residents in a specific country, the true average income of every single citizen is the population parameter. Because it is rarely feasible to collect data from every individual, researchers must rely on sampling to estimate these parameters.
A statistical hypothesis is an educated assumption or a formal claim made about a population parameter. This hypothesis serves as the starting point for any rigorous investigation. For example, a nutritionist might hypothesize that the mean daily caloric intake for adults in a specific region is 2,000 calories. This statement is not yet a proven fact but a mathematical proposition that will be tested against empirical data collected from a representative sample. The goal of the research is to determine if the sample data provides enough evidence to support or refute this initial assumption.
In the framework of frequentist inference, hypotheses are typically divided into two categories: the null hypothesis (H0) and the alternative hypothesis (H1). The null hypothesis generally represents a state of “no effect” or “no difference”—it assumes that any observed variation in the data is purely the result of random sampling error. The alternative hypothesis, conversely, suggests that there is a genuine effect or a significant difference present in the population. The entire process of statistical significance testing is designed to evaluate the strength of the evidence against the null hypothesis.
Ultimately, the relationship between the sample and the population is the core of this endeavor. If the sample is truly random and representative, the statistics derived from it—such as the sample mean—can be used to make inferences about the population parameter. However, because samples are only snapshots of the whole, there is always a degree of uncertainty. Managing this uncertainty is what leads us into the formal mechanics of hypothesis testing and the subsequent determination of significance levels.
The Mechanics of the Hypothesis Test
A hypothesis test is a formal procedure that utilizes probability theory to decide whether to reject or fail to reject a statistical hypothesis. The process begins with the collection of data through a random sample. Once the data is gathered, researchers calculate a test statistic, which is a standardized value that measures how far the sample results deviate from what would be expected if the null hypothesis were true. This value is then used to determine the p-value, which is the cornerstone of statistical significance.
The p-value represents the probability of obtaining test results at least as extreme as the results actually observed, under the assumption that the null hypothesis is correct. A very high p-value suggests that the observed data is perfectly consistent with random chance, meaning there is no reason to abandon the null hypothesis. Conversely, a very low p-value indicates that the observed data is highly unlikely to have occurred by chance alone. In such cases, the researcher concludes that the null hypothesis is likely false and that a real effect exists in the population.
To make a final decision, researchers must pre-define a significance level, often denoted by the Greek letter alpha (α). Common thresholds for alpha include 0.05, 0.01, or 0.10. If the p-value is less than the chosen alpha, the result is declared to be statistically significant. This threshold acts as a risk management tool; for instance, setting alpha at 0.05 means the researcher is willing to accept a 5% risk of committing a Type I error, which is the mistake of rejecting a true null hypothesis (a “false positive”).
While the hypothesis test provides a clear mathematical binary—either significant or not significant—it does not inherently describe the importance of the finding. It merely confirms that the “signal” in the data is strong enough to be distinguished from the “noise.” A researcher might find that a new medication lowers blood pressure with a p-value of 0.001, which is highly significant. However, this does not tell us if the reduction is 1 mmHg or 20 mmHg. This distinction is where practical significance enters the conversation, ensuring that we do not lose sight of the qualitative impact amidst the quantitative calculations.
The Meaning and Limitations of Statistical Significance
When a study concludes that its results are statistically significant, it is essentially providing a statement about the confidence we have in the existence of an effect. It is a measure of evidence strength. In the context of statistical significance, “significant” does not mean “important” or “large”; it simply means “identifiable.” For example, in a massive dataset of millions of users, a difference in website click-through rates of 0.0001% might be statistically significant because the sheer volume of data makes the margin of error extremely small. Mathematical certainty, therefore, does not equate to commercial or clinical value.
One of the primary limitations of statistical significance is its sensitivity to sample size. As the number of observations increases, the standard error of the estimate decreases, which naturally drives down the p-value. This means that with a large enough sample, virtually any tiny difference can be made statistically significant. This phenomenon can be misleading for those who equate significance with magnitude. Relying solely on p-values can lead to the “p-hacking” problem, where researchers search for any combination of variables that yields a significant result, regardless of whether that result has any real utility.
Furthermore, statistical significance is a binary outcome based on an arbitrary threshold. If a study yields a p-value of 0.051, it is labeled “not significant,” while a p-value of 0.049 is “significant.” In reality, there is almost no difference in the strength of evidence between these two numbers. This “cliff-effect” can cause researchers to dismiss potentially valuable findings that just barely missed the cutoff or to over-promote findings that just barely made it. To combat this, modern statistical standards encourage the reporting of effect size and confidence intervals alongside p-values.
In summary, statistical significance is a necessary but insufficient condition for sound scientific or business conclusions. It tells us that something is happening, but it remains silent on whether that “something” is worth our attention. To bridge this gap, we must look at the effect size, which quantifies the magnitude of the difference, and evaluate the practical significance, which assesses the relevance of that magnitude within the specific field of study.
Exploring Practical Significance and Effect Size
Practical significance refers to the real-world importance of a finding. While statistics focus on the question “Is there an effect?”, practical significance asks “Does the effect matter?” This determination is subjective and contextual, depending heavily on the goals of the project and the costs involved in taking action. For instance, in an educational setting, a new teaching method that increases test scores by 0.5% might be statistically significant, but if the method costs millions of dollars to implement, it lacks practical significance.
To quantify practical significance, researchers often look at the effect size. Unlike a p-value, which is influenced by sample size, effect size provides a standardized measure of the magnitude of the observed phenomenon. Common measures of effect size include Cohen’s d for comparing means, Pearson’s r for correlations, and odds ratios for categorical data. By focusing on effect size, stakeholders can compare the relative impact of different interventions regardless of the sample sizes used in the studies. A large effect size suggests a powerful relationship that is likely to have practical significance.
The evaluation of practical significance requires a cost-benefit analysis. A small effect might be practically significant if it is easy and inexpensive to achieve. For example, a minor change in the wording of an email that increases open rates by 1% could be highly significant for a global corporation because the implementation cost is zero, but the cumulative gain is high. Conversely, a large effect might lack practical significance if it is accompanied by severe side effects or prohibitive costs. Thus, practical significance is not a purely mathematical calculation but a strategic decision based on values and constraints.
Ultimately, practical significance ensures that data-driven decisions lead to meaningful improvements in the real world. It serves as a reality check for the mathematical outputs of a hypothesis test. By requiring both statistical significance and practical significance, we ensure that our conclusions are both reliable (unlikely to be a fluke) and impactful (large enough to matter). In the following sections, we will look at specific scenarios where these two concepts diverge due to data variability and sample size issues.
How Low Variability Drives Statistical Significance
One of the most important factors influencing statistical significance is the variability within the data. When a dataset has very low standard deviation, the “noise” surrounding the mean is minimized. This allows the hypothesis test to detect even extremely subtle differences between groups. In these cases, the p-value can drop significantly, leading to a conclusion of statistical significance, even when the actual difference between the groups (the effect size) is tiny and potentially irrelevant in a practical sense.
Consider an example where we compare the test scores of students from two different schools. If the scores in both schools are nearly identical for every student, the standard deviation will be very low. In such a controlled environment, a difference of less than one point on a 100-point scale could be enough to trigger a statistically significant result. However, from a pedagogical perspective, a one-point difference does not indicate that one school is “better” than the other in any meaningful way. Here, the low variability has amplified a trivial difference into a significant result.
sample 1: 85 85 86 86 85 86 86 86 86 85 85 85 86 85 86 85 86 86 85 86 sample 2: 87 86 87 86 86 86 86 86 87 86 86 87 86 86 87 87 87 86 87 86
In the data above, the mean for sample 1 is 85.55 and the mean for sample 2 is 86.40. Despite the difference being only 0.85 points, an independent two-sample t-test yields a p-value of less than 0.0001. This occurs because the standard deviation is only 0.51 for sample 1 and 0.50 for sample 2. Because the scores are so consistent, the test is mathematically certain that the 0.85-point difference is not a fluke. However, a teacher would likely argue that a sub-one-point difference has no practical significance for student placement or curriculum changes.
The mathematical reason for this lies in the formula for the test statistic t. As the variation (s²) in the denominator decreases, the resulting t-value increases. A larger t-value directly translates to a smaller p-value. This demonstrates how data consistency can lead to high mathematical confidence in differences that are effectively meaningless in the real world. Researchers must be wary of “precision without purpose” when dealing with highly uniform data.
test statistic t = [ (x1 – x2) – d ] / (√s21 / n1 + s22 / n2)
The Influence of Sample Size on Statistical Power
The second major driver of statistical significance is the sample size. In statistics, “power” refers to the ability of a test to detect an effect if one actually exists. As the sample size (n) increases, the statistical power of the test also increases. This is generally a positive attribute, as it reduces the likelihood of a Type II error (failing to detect a real effect). However, with very large samples, the test becomes so powerful that it can detect differences so small they are practically invisible to the human eye or of no consequence to business operations.
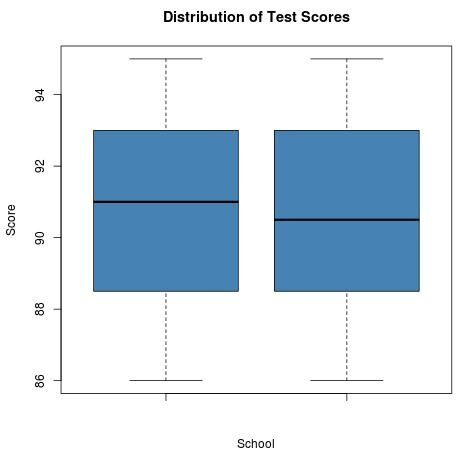
Let’s examine a scenario with higher variability where the initial test with a small sample size fails to reach significance. In this case, the noise in the data masks the signal. If we look at two schools where the test scores have a wider range, a small sample might show no significant difference. However, if we increase those same schools’ sample sizes from 20 to 200, the standard error shrinks, and the same small difference in means can suddenly become statistically significant.
Sample 1: 88 89 91 94 87 94 94 92 91 86 87 87 92 89 93 90 92 95 89 93 Sample 2: 95 88 93 87 89 90 86 90 95 89 91 92 91 88 94 93 94 87 93 90
With a sample size of 20, the means are 90.65 and 90.75, with standard deviations of roughly 2.77. The resulting p-value is 0.91, which is nowhere near the 0.05 threshold. The distributions look almost identical on a visual plot, as shown below:

However, if the sample size were increased to 200 for each group while maintaining the same means and variances, the p-value would drop to approximately 0.05. The difference in means is still only 0.1 points—a negligible amount in the context of grading—but the large sample size has forced the hypothesis test to declare it “statistically significant.” This highlights the danger of “Big Data” where everything is significant but nothing is necessarily important. It is vital to remember that statistical significance is a function of both effect size and sample size; as one grows, the requirement for the other to achieve significance shrinks.
The Necessity of Subject Matter Expertise
Because mathematical tests cannot distinguish between a “large” difference and an “important” one, subject matter expertise is the essential third component of data analysis. An expert in the field provides the necessary context to determine the threshold for practical significance. In the previous school examples, a statistician might report a significant p-value, but it takes an experienced educator to decide if a 1-point difference warrants a total overhaul of the curriculum.
Subject matter experts must define the Minimum Clinically Important Difference (MCID) or a similar benchmark before the study begins. This benchmark serves as the “goalpost” for practical significance. If a new manufacturing process is statistically significant in reducing waste by 0.01%, an operations manager must decide if that reduction offsets the cost of retooling the factory. Without this expert lens, data analysis remains a theoretical exercise disconnected from organizational goals and economic realities.
Furthermore, experts can help identify confounding variables that might be driving statistical significance without providing real value. They can interpret the effect size in the context of historical data and industry standards. For example, in the pharmaceutical industry, a drug that is statistically significant in reducing symptoms might still be rejected if the effect size is smaller than existing, cheaper generics. Ultimately, the partnership between the statistician and the subject matter expert ensures that the results are not only true but also useful.
In many cases, the lack of practical significance is a reason to halt further investment. If a statistically significant result does not meet the pre-defined threshold for practical importance, it should be treated as a “minor effect” that does not justify action. This disciplined approach prevents “feature creep” in product development and “over-treatment” in medicine. By integrating expertise, we transform raw data into actionable intelligence.
Confidence Intervals as a Practical Decision-Making Tool
While p-values provide a “yes/no” answer regarding significance, a confidence interval (CI) offers a much more informative view for assessing practical significance. A confidence interval provides a range of plausible values for the true population parameter. For example, instead of just saying the mean difference is 5 points, a 95% confidence interval might say the difference is likely between 2 and 8 points. This range gives decision-makers a sense of the “best-case” and “worst-case” scenarios.
Confidence intervals are particularly useful because they are expressed in the same units as the data itself (e.g., dollars, points, or milligrams). This allows for a direct comparison with the practical thresholds defined by experts. If a principal decides that a 5-point improvement is the minimum required to change the curriculum, and the confidence interval for the study is [6, 10], then even the lowest probable value (6) exceeds the threshold. In this case, the result is both statistically significant and highly likely to be practically significant.
Conversely, if the confidence interval is [1, 9], the result might be statistically significant (since the interval does not contain zero), but it is not practically significant with certainty. Because the range includes values as low as 1—which is below our 5-point threshold—there is a substantial risk that the real-world impact will be disappointing. Intervals provide a measure of precision and risk that a single p-value simply cannot convey. They allow stakeholders to visualize the uncertainty and make more nuanced choices.
By shifting the focus from “Is the p-value less than 0.05?” to “Does the confidence interval overlap with our practical threshold?”, researchers can provide much more value to their organizations. This approach encourages a move away from binary thinking and toward a more sophisticated understanding of data. It highlights that the goal of statistics is not just to find “significance,” but to estimate the true nature of the world with a known degree of confidence.
Conclusion
Navigating the relationship between statistical significance and practical significance is a hallmark of an advanced researcher or analyst. Throughout this article, we have explored how these two concepts interact and where they diverge. To summarize the key takeaways:
- Statistical significance is a mathematical determination that an effect is unlikely to have occurred by random chance, based on a specific significance level.
- Practical significance evaluates whether the magnitude of that effect is large enough to be meaningful in a real-world context, often requiring a high effect size.
- The p-value is highly sensitive to sample size and variability; large samples or very low variability can make even tiny, trivial differences statistically significant.
- Subject matter expertise is essential for setting the benchmarks of what constitutes a “significant” change in any specific field, from education to medicine.
- A confidence interval is often a superior tool for decision-making compared to a p-value, as it provides a range of likely values that can be directly compared to practical requirements.
- Effective data analysis requires the integration of both mathematical rigor and contextual judgment to ensure that findings are both reliable and actionable.
By applying these principles, one can avoid the pitfalls of over-interpreting minor numerical shifts and ensure that data-driven insights lead to truly impactful outcomes. Whether you are conducting a hypothesis test for a small business or a large-scale clinical trial, keeping the distinction between the “statistically significant” and the “practically significant” at the forefront of your analysis will lead to more robust and responsible conclusions.
Cite this article
stats writer (2026). How to Tell the Difference Between Statistical and Practical Significance. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-the-difference-between-statistical-significance-and-practical-significance/
stats writer. "How to Tell the Difference Between Statistical and Practical Significance." PSYCHOLOGICAL SCALES, 4 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-the-difference-between-statistical-significance-and-practical-significance/.
stats writer. "How to Tell the Difference Between Statistical and Practical Significance." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-the-difference-between-statistical-significance-and-practical-significance/.
stats writer (2026) 'How to Tell the Difference Between Statistical and Practical Significance', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-the-difference-between-statistical-significance-and-practical-significance/.
[1] stats writer, "How to Tell the Difference Between Statistical and Practical Significance," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Tell the Difference Between Statistical and Practical Significance. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.