Table of Contents
In the realm of regression analysis, a field fundamental to statistics and machine learning, the regressor holds a central role. It is formally defined as any variable within a statistical regression model used specifically to predict, explain, or forecast changes in a designated response variable. Essentially, regressors are the inputs we utilize to understand the resulting output of a system or process.
Due to the interdisciplinary nature of quantitative analysis—spanning statistics, econometrics, epidemiology, and advanced machine learning—the term regressor often takes on several synonyms, used interchangeably depending on the specific domain or context. Understanding these alternative names is crucial for effective collaboration and research across quantitative fields.
A regressor is commonly referred to as:
- An Independent Variable (emphasizing its role as the factor being manipulated or observed independently of the outcome).
- An Explanatory Variable (highlighting its function in explaining the variance in the response).
- A Covariate (often used when the variable is controlled for or measured alongside the primary treatment).
- A Predictor Variable (emphasizing its utility in forecasting future outcomes).
- A Feature (the preferred terminology within modern machine learning and artificial intelligence disciplines).
All of these terms denote the set of input variables used to model the relationship with the output. Conversely, it is worth noting that the response variable (Y), which is the outcome being predicted, is sometimes called the regressand.
The Mathematical Foundation of Regressors
To fully appreciate the role of regressors, one must examine the standard mathematical representation of a linear regression model. This foundational structure allows researchers to quantify the strength and direction of the relationship between the independent variables (regressors) and the dependent variable (response). This model is not just descriptive; it is fundamentally predictive, allowing us to estimate the outcome based on a given set of input values.
The generic form for a model with multiple regressors, commonly known as a multiple linear regression, is typically written as follows:
Y = β0 + β1x1+ β2x2 + … + βnxn + ε
This equation serves as the blueprint for almost all linear regression methods, whether they are focused on classical statistical inference or modern predictive modeling. The inclusion of multiple terms (x1 through xn) highlights the complexity that can be handled when trying to model real-world phenomena influenced by numerous simultaneous factors.
Understanding the components of this formula is essential for interpreting the results of any regression analysis. Each element plays a specific role in accounting for the variance and relationships observed in the underlying data set.
Detailed Breakdown of the Regression Components
The various symbols in the regression equation represent distinct concepts, and correctly identifying the regressors and their associated parameters is paramount to successful model building and interpretation.
- Y: This is the Response Variable (or Regressand). It is the outcome we are attempting to predict or explain, making it the core subject of the statistical study.
- xi: These are the Regressors (x1, x2, x3, etc.). These are the independent or predictor variables whose measured values are used to influence the predicted value of Y. They can represent diverse factors, such as socioeconomic metrics, environmental conditions, or experimental dosages.
- βi: These represent the Regression Coefficients (β1, β2, β3, etc.). These estimated parameters quantify the strength and direction of the relationship between each specific regressor (xi) and the response variable (Y). They indicate the expected change in Y given a one-unit change in xi.
- β0: This is the Intercept. It represents the predicted value of the response variable (Y) when all of the regressors (xi) are equal to zero. This serves as the baseline prediction.
- ε: This is the Error Term (or Residual). This stochastic component accounts for the variability in Y that cannot be systematically explained by the included regressors. It captures all unobserved factors, measurement errors, and inherent randomness in the system.
The fundamental objective of constructing and analyzing a regression model is to rigorously understand how marginal changes in one or more regressors lead to corresponding, quantifiable changes in the response variable (or regressand). This understanding forms the basis for hypothesis testing and informed, evidence-based decision-making across statistical fields.
Simple vs. Multiple Regression: Quantifying Complexity
Regression models are systematically classified based on the number of predictor variables they incorporate. This distinction is crucial as it dictates the complexity of the interpretation, the mathematical fitting procedure, and the computational resources required.
When the model contains only a single regressor, the analysis is significantly streamlined, allowing for clear visualization in two dimensions and direct interpretation of the bivariate relationship. This structure is formally known as Simple Linear Regression. The corresponding equation simplifies to Y = β0 + β1x1 + ε, where only x1 is employed to predict Y. This model is often used when preliminary analysis suggests one dominant factor influences the outcome, or when the goal is introductory demonstration.
Conversely, when the model incorporates two or more regressors (x1, x2, …, xn where n ≥ 2), it is termed Multiple Linear Regression. This is the far more common scenario in professional data analysis, as most real-world outcomes are influenced by a complex, interacting interplay of various factors. The use of multiple regressors provides a richer, more accurate picture of the underlying mechanisms influencing the response variable, as it allows the model to statistically control for confounding variables.
Interpreting the Regressor Coefficients
The true utility of a regressor lies in the precise interpretation of its corresponding coefficient (βi). This coefficient represents the estimated marginal effect of that regressor on the response variable. Precise interpretation requires adherence to the crucial statistical assumption of “ceteris paribus”—meaning all other input variables are held constant.
Specifically, the coefficient βi associated with regressor xi signifies the average change in the predicted value of Y (the response variable) for every one-unit increase in xi, provided that the values of all other regressors (xj, where j ≠ i) remain fixed at their current levels. If the coefficient is positive, the relationship is positive and direct: increasing the regressor increases the predicted response. If the coefficient is negative, the relationship is inverse: increasing the regressor decreases the predicted response.
It is essential to remember that regression coefficients indicate association, not necessarily direct causality, unless the data originated from a rigorously controlled randomized experiment. Furthermore, comparing the magnitude of coefficients across different regressors is often misleading if they are measured on vastly different scales; standardized coefficients are typically required when comparing the relative importance of varying regressors.
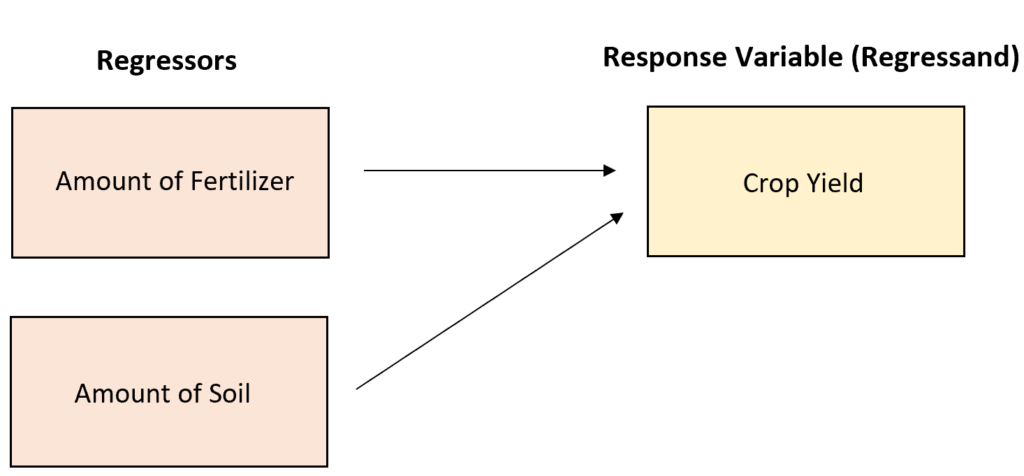
Example 1: Analyzing Crop Yield with Multiple Regressors
Consider a scenario in agricultural science where a farmer seeks to maximize total crop yield. Yield is likely influenced by several interacting environmental and management factors, necessitating a Multiple Linear Regression approach. The farmer collects data on fertilizer usage and soil quality, modeling the relationship between these inputs and the total output (Crop Yield, measured in pounds).
Suppose statistical fitting results in the following regression equation:
Crop Yield = 154.34 + 3.56*(Pounds of Fertilizer) + 1.89*(Pounds of Soil)
In this specific model, “Pounds of Fertilizer” and “Pounds of Soil” are the two critical regressors, and Crop Yield is the response variable. The coefficients associated with these regressors provide direct, actionable insights based on the ceteris paribus assumption:
- Fertilizer Regressor (Coefficient: +3.56): For each additional pound of fertilizer applied, the expected crop yield increases by an average of 3.56 pounds. This interpretation holds true only if the amount of soil quality is assumed to be held constant, allowing us to isolate the specific contribution of fertilizer.
- Soil Regressor (Coefficient: +1.89): For each additional pound of soil (or standardized unit of soil quality measurement) utilized, the crop yield increases by an average of 1.89 pounds, assuming the amount of fertilizer applied is held constant.
The intercept (154.34) suggests a baseline yield in the absence of the measured inputs. This example clearly demonstrates how the use of multiple regressors allows for the simultaneous assessment and disentanglement of individual factor contributions to the observed outcome.

Example 2: Analyzing Exam Scores with a Simple Regressor
In an academic setting, a professor might investigate the relationship between student effort and academic performance. The professor hypothesizes that the number of hours a student spends studying is the primary determinant of their final exam score. This leads to the construction of a Simple Linear Regression model, which utilizes only one predictor variable.
After collecting and analyzing the student data, the resulting model is calculated as:
Exam Score = 68.34 + 3.44*(Hours Studied)
This model features a single regressor: “Hours Studied.” The response variable is the “Exam Score.” Since there is only one input variable, the interpretation is straightforward; we are measuring the direct, unconditional linear relationship between study time and score. Any unobserved or unmeasured factors (like prior knowledge or test anxiety) are collectively summarized in the model’s error term.
The interpretation of the coefficient (3.44) for this sole regressor means that for every additional hour a student spends studying, their predicted exam score increases by an average of 3.44 points. The intercept of 68.34 suggests that a student who studies zero hours is still predicted to achieve a baseline score of 68.34. This simple model provides a clear, quantitative measure of the impact of the targeted input variable.

Challenges in Regressor Selection and Model Building
Choosing the appropriate set of regressors is arguably the most critical and challenging step in the entire regression model construction process. The quality and predictive validity of the final model depend heavily on this initial selection, often requiring a deep understanding of the subject matter, not just statistical expertise.
A major statistical challenge is omitted variable bias (OVB), which occurs when a statistically significant and theoretically relevant regressor is inadvertently left out of the model specification. This omission forces the effect of the missing variable to be absorbed into the coefficients of the included regressors, leading to biased, inconsistent, and often misleading coefficient estimates. Conversely, including too many irrelevant regressors can unnecessarily complicate the model, increasing the variance and risk of overfitting the sample data.
Another crucial concern in Multiple Linear Regression is multicollinearity, the phenomenon where two or more regressors are highly correlated with each other. When regressors move in near-perfect tandem, it becomes statistically impossible for the model to reliably isolate the individual, unique effect of each variable on the response. High multicollinearity inflates the standard errors of the coefficients, making their estimates unstable, often resulting in coefficients with the wrong sign or implausible magnitudes. Analysts must use diagnostic tools, such as the Variance Inflation Factor (VIF), to detect and mitigate this dependency among input variables.
Conclusion: The Importance of the Input Variable
The regressor, or predictor variable, is the cornerstone of any statistical or machine learning regression task. By quantifying how changes in these input variables systematically affect the outcome, regression analysis provides invaluable tools for prediction, causality assessment (in appropriate experimental contexts), and descriptive statistical inference across virtually all scientific and business disciplines.
Whether analysts are dealing with the straightforward structure of a Simple Linear Regression or navigating the intricate network of relationships found in complex Multiple Linear Regression, the careful selection, proper measurement, and accurate interpretation of the regressors determine the ultimate success and reliability of the entire modeling effort. Mastery of the regressor’s functional role is therefore absolutely fundamental for anyone working with quantitative data analysis and predictive analytics.