Table of Contents
The Uniform Distribution in the R programming environment represents a fundamental concept in probability theory where every possible outcome within a specific range is equally likely to occur. Often referred to as the rectangular distribution due to the shape of its probability density function, this distribution serves as a critical baseline for statistical modeling and randomness testing. In practice, when we describe a variable as being uniformly distributed, we are asserting that there is no bias toward any particular value between the defined minimum and maximum bounds, making it an ideal model for processes like fair gaming or certain physical phenomena.
The Uniform Distribution in R
Understanding the Fundamentals of the Uniform Distribution
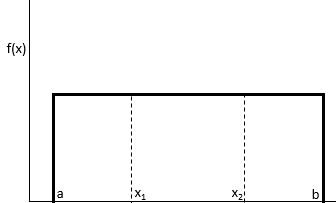
A Continuous Uniform Distribution is a statistical distribution where every real value within a specific interval, defined by a lower bound a and an upper bound b, has an identical probability of being selected. This characteristic distinguishes it from other distributions, such as the normal distribution, where values cluster around a central mean. In the context of a random variable, the uniform distribution implies a state of maximum uncertainty or lack of information regarding where a value might fall within the range, provided the range is known. This makes it a cornerstone of Bayesian statistics when identifying non-informative priors.
The mathematical representation of this distribution is straightforward yet powerful. The probability that a value will be obtained within a sub-interval between x1 and x2, where both values reside within the larger interval [a, b], is proportional to the length of that sub-interval relative to the total range. This linear relationship ensures that the total area under the density curve remains equal to one, satisfying the core axioms of probability. In R, users can simulate these scenarios to analyze the behavior of variables that do not exhibit a central tendency but rather spread across a spectrum.
The formula to calculate the probability of obtaining a value within a specific range [x1, x2] on the total interval from a to b is expressed as follows: P(obtain value between x1 and x2) = (x2 – x1) / (b – a). This formula highlights the simplicity of the distribution; the probability is merely the ratio of the sub-range to the total range. By utilizing this formula, statisticians can quickly estimate the likelihood of events in systems where the boundaries are strict and the density is constant, such as in timing mechanisms or hardware sampling frequencies.

Statistical Properties of the Continuous Uniform Distribution
To fully grasp the behavior of the Uniform Distribution, one must examine its primary descriptive statistics, which include the mean, variance, and standard deviation. The mean (denoted by μ) represents the expected value of the distribution. For a uniform distribution, the mean is simply the arithmetic average of the two endpoints: μ = (a + b) / 2. This indicates that the “balance point” of the distribution is exactly in the center of the defined range, reflecting the symmetrical nature of the rectangular density.
The variance (denoted by σ2) provides a measure of how spread out the values are from the center. Unlike the normal distribution where variance is an independent parameter, the variance of a uniform distribution is derived directly from the length of the interval: σ2 = (b – a)2 / 12. This specific divisor of 12 arises from the integration of the squared deviations over a constant density. This mathematical consistency allows researchers to predict the volatility or dispersion of a random variable simply by knowing its range boundaries.
Finally, the standard deviation (denoted by σ) is the square root of the variance: σ = √σ2. This metric is particularly useful for comparing the spread of a uniform distribution to other distributions in the same units as the original data. In R, understanding these properties is essential when validating simulations. For instance, if you generate a large sample using uniform functions, the sample mean and sample variance should closely approximate these theoretical values as the sample size increases, in accordance with the Law of Large Numbers.
Navigating the R Syntax for Uniform Distributions
The R programming language provides a suite of built-in functions specifically designed to handle the Uniform Distribution. These functions allow users to calculate densities, cumulative probabilities, and generate random samples with minimal code. The two primary functions for probability calculations are dunif() and punif(). Each function requires the user to specify the value of interest and the boundaries of the distribution, ensuring that the software can accurately map the request to the mathematical model.
The dunif(x, min, max) function calculates the probability density function (pdf) for a given value x. Since the uniform distribution is continuous, the density is constant at 1/(max – min) for any value within the range and zero otherwise. While the density at a single point in a continuous distribution isn’t a probability in itself, dunif is vital for plotting the distribution curve or calculating likelihoods in complex statistical models. It ensures that the height of the rectangular distribution is correctly computed based on the width provided by the min and max parameters.
The punif(q, min, max) function is used to calculate the cumulative distribution function (cdf). This is often more practical for real-world problem-solving, as it determines the probability that a random variable is less than or equal to a specific value q. By integrating the density from the minimum value up to q, punif provides the area under the curve to the left of the point. This is the standard tool for answering “less than” or “within” type questions in statistical analysis and hypothesis testing within the R environment.
Beyond these, the runif(n, min, max) function is perhaps the most frequently used in data science. It allows for the generation of n random observations from a uniform distribution. This is indispensable for Monte Carlo simulations, where repeated random sampling is used to obtain numerical results for complex problems. By default, runif uses a range of 0 to 1, which is the standard uniform distribution, but it can be easily adjusted to fit any interval required by the researcher’s specific use case.
Practical Implementation: Solving Real-World Bus Timing Scenarios
To illustrate the utility of the punif() function, consider a common urban planning problem involving transit wait times. Imagine a scenario where a bus is scheduled to arrive at a stop exactly every 20 minutes. If a passenger arrives at the stop at a random time, their wait time follows a Uniform Distribution with a minimum of 0 minutes and a maximum of 20 minutes. A logical question for the passenger might be: “What is the probability that the bus will show up in 8 minutes or less?”
To solve this in R, we utilize the cumulative distribution function. Since we are looking for the probability of an event occurring within the first 8 minutes of a 20-minute window, we pass the value 8 to punif() along with our interval boundaries. The function calculates the proportion of the total interval represented by the first 8 minutes, effectively performing the calculation 8 / 20. The formal R syntax for this operation is as follows:
punif(8, min=0, max=20)
## [1] 0.4
The result of 0.4 indicates that there is a 40% chance the bus will arrive within the first 8 minutes of the passenger’s wait. This practical application demonstrates how the Uniform Distribution helps quantify uncertainty in daily life. By modeling wait times this way, transit authorities can assess service efficiency and passenger satisfaction levels using robust statistical methods rather than simple guesswork.
Advanced Probability Calculations: Analyzing Biological Measurements
Statistical distributions are frequently used in biology to model variables that exhibit uniform traits within specific ecological niches. Suppose a study finds that the weight of a particular species of frog is uniformly distributed between 15 and 25 grams. If a researcher captures a frog at random, they might need to determine the probability that the specimen weighs between 17 and 19 grams. This requires calculating the probability within a specific sub-interval of the total distribution.
In R, finding the probability for an interval [x1, x2] involves calculating the cumulative distribution function at the upper bound and subtracting the cumulative probability at the lower bound. This effectively isolates the area under the density curve between 17 and 19. By subtracting the probability of weighing less than 17 from the probability of weighing less than 19, we are left with the probability of falling exactly within that two-gram range. The code to execute this is shown below:
punif(19, 15, 25) - punif(17, 15, 25)
## [1] 0.2
The output of 0.2 reveals that there is a 20% probability that a randomly selected frog will weigh between 17 and 19 grams. This method of subtracting cumulative probabilities is a standard technique in statistics for any continuous random variable. It allows for precise estimation of outcomes in biological research, where understanding the distribution of physical traits is essential for population health assessments and environmental monitoring.
Evaluating Tail Probabilities in Professional Sports Durations
The Uniform Distribution is also applicable in the world of sports analytics, particularly for modeling the duration of events that are constrained by specific rules but vary due to play stoppages. For example, the total length of an NBA basketball game might be modeled as being uniformly distributed between 120 and 170 minutes. An analyst might want to know the probability that a game lasts significantly longer than average—for instance, more than 150 minutes.
To calculate “greater than” probabilities in R, we apply the complement rule. Since the total probability of all possible outcomes is 1, the probability of a game lasting more than 150 minutes is equal to 1 minus the probability that it lasts 150 minutes or less. We can use the punif() function to find the cumulative probability up to 150 and then subtract that value from 1. This approach is highly efficient for tail-end analysis in distribution modeling.
1 - punif(150, 120, 170)
## [1] 0.4
The resulting value of 0.4 shows that there is a 40% chance a game will exceed 150 minutes in length. Alternatively, R allows users to specify the argument lower.tail = FALSE within the punif() function to achieve the same result directly. Understanding these different syntax options provides flexibility for data scientists when performing survival analysis or time-to-event modeling in various professional fields, ranging from sports to industrial engineering.
Generating Random Samples and Simulations in R
One of the most powerful features of R is its ability to generate pseudorandom numbers that follow a specific distribution. The runif() function is the primary tool for this task. By generating thousands or even millions of data points from a Uniform Distribution, researchers can build simulations to test the robustness of their statistical models. This is especially important in fields like finance and cryptography, where the quality and distribution of random inputs can significantly impact the outcome of a risk assessment or security protocol.
When using runif(n, min, max), the n parameter determines the number of observations to generate. For instance, creating a sample of 1,000 observations between 0 and 100 allows a user to visualize the distribution using a histogram. In a perfectly uniform sample, the histogram would show roughly equal bar heights across the entire range. This visual verification is a crucial step in exploratory data analysis, helping to confirm that the random generation process is behaving as expected according to theoretical parameters.
Moreover, random number generation is the basis for many other statistical techniques, such as bootstrapping and resampling. By drawing samples from a uniform distribution and using them to index an existing dataset, data scientists can create multiple variations of their data to estimate the standard error of their statistics. The flexibility of runif() makes it one of the most versatile functions in the R toolkit, supporting both simple experiments and complex computational research projects.
Conclusion and Theoretical Significance
The Uniform Distribution in R is more than just a simple mathematical curiosity; it is a foundational building block for advanced statistical computing. By providing a clear, rectangular density where all outcomes are equally probable, it allows for the clear modeling of scenarios where no prior bias exists. Whether you are calculating the probability of a bus arrival, the weight of biological specimens, or the length of a professional sports game, the functions punif, dunif, and runif provide the necessary precision and ease of use.
As we have explored, the properties of this distribution—including its mean, variance, and standard deviation—are easily derived from the interval boundaries. This predictability makes it an excellent choice for educational purposes, helping students grasp the transition from discrete to continuous probability. In the professional realm, the uniform distribution remains a staple for simulation and modeling, providing a reliable baseline against which more complex distributions can be compared.
Mastering these tools within R empowers analysts to handle randomness with confidence. By leveraging the software’s built-in capabilities to solve real-world problems and generate large-scale simulations, users can derive deeper insights from their data. The uniform distribution’s simplicity is its greatest strength, offering a transparent and effective way to quantify the equal likelihood of events in an unpredictable world.
Cite this article
stats writer (2026). How to Generate and Use the Uniform Distribution in R. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-the-uniform-distribution-in-r/
stats writer. "How to Generate and Use the Uniform Distribution in R." PSYCHOLOGICAL SCALES, 2 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-the-uniform-distribution-in-r/.
stats writer. "How to Generate and Use the Uniform Distribution in R." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-the-uniform-distribution-in-r/.
stats writer (2026) 'How to Generate and Use the Uniform Distribution in R', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-the-uniform-distribution-in-r/.
[1] stats writer, "How to Generate and Use the Uniform Distribution in R," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Generate and Use the Uniform Distribution in R. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.