Table of Contents
The method for finding the mean and standard deviation of grouped data involves first determining the class intervals and frequencies of the data. Then, the midpoints of each class interval are calculated and multiplied by their respective frequencies. The sum of these products is divided by the total frequency to find the mean. To find the standard deviation, the difference between each data point and the mean is squared, multiplied by their respective frequencies, and then added together. The sum is divided by the total frequency and the square root is taken to find the standard deviation. This method takes into account the grouping of data and provides a more accurate measure of central tendency and variability.
Find Mean & Standard Deviation of Grouped Data
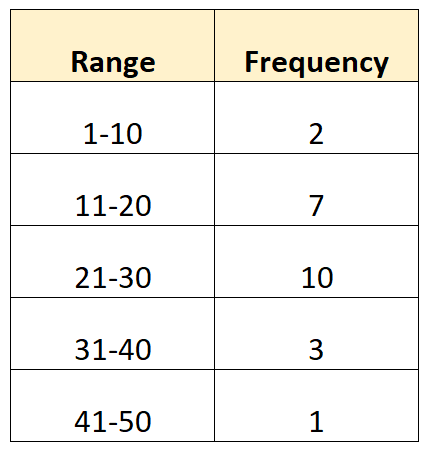
Often we may want to calculate the mean and standard deviation of data that is grouped in some way. For example, suppose we have the following grouped data:

While it’s not possible to calculate the exact mean and standard deviation since we don’t know the , it is possible to estimate the mean and standard deviation.
The following steps explain how to do so.
Calculate the Mean of Grouped Data
We can use the following formula to estimate the mean of grouped data:
Mean: Σmini / N
where:
- mi: The midpoint of the ith group
- ni: The frequency of the ith group
- N: The total sample size
Here’s how we would apply this formula to our dataset from earlier:

The mean of the dataset turns out to be 22.89.
Note: The for each group can be found by taking the average of the lower and upper value in the range. For example, the midpoint for the first group is calculated as: (1+10) / 2 = 5.5.
Calculate the Standard Deviation of Grouped Data
We can use the following formula to estimate the standard deviation of grouped data:
Standard Deviation: √Σni(mi-μ)2 / (N-1)
- ni: The frequency of the ith group
- mi: The midpoint of the ith group
- μ: The mean
- N: The total sample size
Here’s how we would apply this formula to our dataset:
 The standard deviation of the dataset turns out to be 9.6377.
The standard deviation of the dataset turns out to be 9.6377.
Cite this article
stats writer (2024). What is the method for finding the mean and standard deviation of grouped data?. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-the-method-for-finding-the-mean-and-standard-deviation-of-grouped-data/
stats writer. "What is the method for finding the mean and standard deviation of grouped data?." PSYCHOLOGICAL SCALES, 26 Apr. 2024, https://scales.arabpsychology.com/stats/what-is-the-method-for-finding-the-mean-and-standard-deviation-of-grouped-data/.
stats writer. "What is the method for finding the mean and standard deviation of grouped data?." PSYCHOLOGICAL SCALES, 2024. https://scales.arabpsychology.com/stats/what-is-the-method-for-finding-the-mean-and-standard-deviation-of-grouped-data/.
stats writer (2024) 'What is the method for finding the mean and standard deviation of grouped data?', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-the-method-for-finding-the-mean-and-standard-deviation-of-grouped-data/.
[1] stats writer, "What is the method for finding the mean and standard deviation of grouped data?," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, April, 2024.
stats writer. What is the method for finding the mean and standard deviation of grouped data?. PSYCHOLOGICAL SCALES. 2024;vol(issue):pages.