Table of Contents
R and R-Squared are both statistical measures used to evaluate the performance and accuracy of a regression model. However, they serve different purposes. R, also known as the correlation coefficient, measures the strength and direction of the relationship between two variables in the model. It ranges from -1 to 1, where a value closer to 1 indicates a strong positive relationship and a value closer to -1 indicates a strong negative relationship. On the other hand, R-Squared, also known as the coefficient of determination, measures the proportion of variation in the dependent variable that can be explained by the independent variables in the model. It ranges from 0 to 1, where a value closer to 1 indicates that the model fits the data well. In summary, R measures the strength of the relationship between variables, while R-Squared measures the overall performance of the regression model.
R vs. R-Squared: What’s the Difference?
Two terms that students often get confused in statistics are R and R-squared, often written R2.
In the context of :
- R: The correlation between the predictor variable, x, and the response variable, y.
- R2: The proportion of the variance in the response variable that can be explained by the predictor variable in the regression model.
And in the context of :
- R: The correlation between the observed values of the response variable and the predicted values of the response variable made by the model.
- R2: The proportion of the variance in the response variable that can be explained by the predictor variables in the regression model.
Note that the value for R2 ranges between 0 and 1. The closer the value is to 1, the stronger the relationship between the predictor variable(s) and the response variable.
The following examples show how to interpret the R and R-squared values in both simple linear regression and multiple linear regression models.
Example 1: Simple Linear Regression
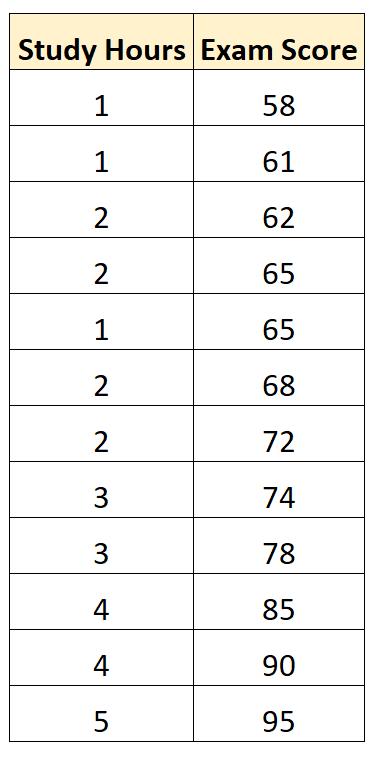
Suppose we have the following dataset that shows the hours studied and exam score received by 12 students in a certain math class:

Using statistical software (like Excel, R, Python, SPSS, etc.), we can fit a simple linear regression model using “study hours” as the predictor variable and “exam score” as the .
We can find the following output for this model:

Here’s how to interpret the R and R-squared values of this model:
- R: The correlation between hours studied and exam score is 0.959.
- R2: The R-squared for this regression model is 0.920. This tells us that 92.0% of the variation in the exam scores can be explained by the number of hours studied.
Also note that the R2 value is simply equal to the R value, squared:
R2 = R * R = 0.959 * 0.959 = 0.920
Example 2: Multiple Linear Regression
Suppose we have the following dataset that shows the hours studied, current student grade, and exam score received by 12 students in a certain math class:

Using statistical software, we can fit a multiple linear regression model using “study hours” and “current grade” as the predictor variables and “exam score” as the response variable.
We can find the following output for this model:

Here’s how to interpret the R and R-squared values of this model:
- R: The correlation between the actual exam scores and the predicted exam scores made by the model is 0.978.
- R2: The R-squared for this regression model is 0.956. This tells us that 95.6% of the variation in the exam scores can be explained by the number of hours studied and the student’s current grade in the class.
Also note that the R2 value is simply equal to the R value, squared:
R2 = R * R = 0.978 * 0.978 = 0.956
Cite this article
stats writer (2024). What is the difference between R and R-Squared?. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-the-difference-between-r-and-r-squared/
stats writer. "What is the difference between R and R-Squared?." PSYCHOLOGICAL SCALES, 29 Apr. 2024, https://scales.arabpsychology.com/stats/what-is-the-difference-between-r-and-r-squared/.
stats writer. "What is the difference between R and R-Squared?." PSYCHOLOGICAL SCALES, 2024. https://scales.arabpsychology.com/stats/what-is-the-difference-between-r-and-r-squared/.
stats writer (2024) 'What is the difference between R and R-Squared?', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-the-difference-between-r-and-r-squared/.
[1] stats writer, "What is the difference between R and R-Squared?," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, April, 2024.
stats writer. What is the difference between R and R-Squared?. PSYCHOLOGICAL SCALES. 2024;vol(issue):pages.