Table of Contents
Understanding the Theoretical Framework of Sampling Distributions
In the vast field of statistics, the concept of a sampling distribution serves as a foundational pillar for making logical deductions about a large group based on a smaller subset. Specifically, a sampling distribution is a theoretical probability distribution of a specific statistic, such as the mean or proportion, derived from a large number of samples drawn from a specific population. While researchers rarely collect every possible sample, understanding how these samples behave in aggregate is essential for validating the results of any empirical study.
The core utility of this concept lies in its ability to bridge the gap between observed sample data and actual population parameters. When we calculate a mean from a single group, that value is merely a point estimate. However, by conceptualizing the sampling distribution, we recognize that different samples would naturally yield slightly different means due to sampling error. This theoretical distribution maps out every possible outcome, allowing statisticians to quantify the likelihood of their observed results and determine the level of confidence they can place in their findings.
Furthermore, the characteristics of a sampling distribution—its center, spread, and shape—provide critical insights into the accuracy and precision of our statistical models. By analyzing these distributions, we can determine whether a sample is likely representative of the population or if it represents an extreme outlier. This process is the bedrock of statistical inference, enabling scientists to test hypotheses and construct confidence intervals with mathematical rigor and objective clarity.
The Mechanics of Sample Means: An Illustrative Example
To visualize how these theoretical concepts manifest in the real world, let us consider a hypothetical population of 10,000 dolphins. In this scenario, we assume the true average or mean weight of a dolphin in this population is exactly 300 pounds. If we were to perform a simple random sample consisting of 50 dolphins, the resulting average might be 305 pounds. This slight discrepancy from the true population mean is expected and illustrates the inherent variability present in any localized data collection effort.
The variability becomes even more apparent if we repeat the process. Suppose we take a second simple random sample of another 50 dolphins; this time, the calculated mean might be 295 pounds. Each subsequent sample will yield a unique value. While most of these sample means will cluster around the true population mean of 300 pounds, they will rarely match it perfectly. This phenomenon occurs because each sample captures a different slice of the population’s diversity, reflecting the natural fluctuations inherent in random selection.
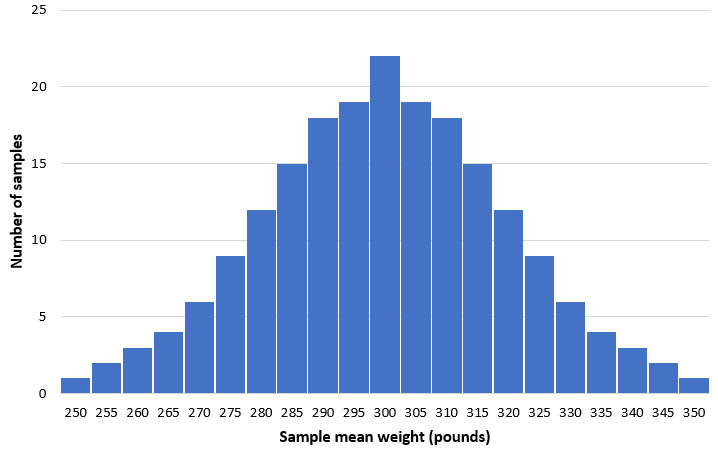
To fully grasp the sampling distribution, imagine extending this exercise to include 200 distinct samples, each with a size of 50 dolphins. By plotting the mean weight from each of these 200 samples on a histogram, a distinct pattern begins to emerge. This visual representation allows us to see the frequency of various outcomes and understand the probable range within which most sample means will fall.

As the histogram illustrates, the majority of samples produce means very close to the true population value of 300 pounds. While extreme scenarios exist—such as accidentally selecting a group of exceptionally small dolphins (resulting in a mean of 250 pounds) or exceptionally large dolphins (resulting in a mean of 350 pounds)—these instances are statistically rare. Generally, the distribution of these sample means will follow an approximately normal curve, centered precisely at the actual population mean.
Mathematical Properties of the Sampling Distribution of the Mean
The behavior of the sampling distribution of the mean is governed by specific mathematical properties that allow for precise calculations. One of the most significant properties is that the mean of the sampling distribution is equal to the mean of the population. This relationship is expressed through the following formula, which underscores the unbiased nature of the sample mean as an estimator:
- μx = μ
In this equation, μx represents the mean of the sample means, while μ signifies the true population mean. This indicates that if we were to take an infinite number of samples, the average of those sample averages would perfectly align with the population’s actual value. In our dolphin example, because the true mean is 300 pounds, the center of our sampling distribution is also 300 pounds.
The second critical property involves the spread or variability of the distribution, known as the standard error. The standard error measures how much the sample mean is expected to vary from the true population mean. It is calculated by dividing the population standard deviation by the square root of the sample size, as shown below:
- σx = σ / √n
Where σx is the standard deviation of the sampling distribution (standard error), σ is the population standard deviation, and n is the sample size. This formula reveals an important truth in statistics: as the sample size increases, the standard error decreases. Larger samples provide more reliable estimates and result in a narrower, more “pointed” sampling distribution. Applying this to our dolphins, if the population standard deviation is 18 pounds and our sample size is 50, the standard error is calculated as 18 / √50, which equals 2.546.
Exploring the Sampling Distribution of the Proportion
Sampling distributions are not limited to averages; they are equally vital when dealing with categorical data and proportions. Consider the same population of 10,000 dolphins, but instead of weight, we are interested in a specific trait: skin color. Suppose that exactly 10% of the dolphins are black, while the remaining 90% are gray. In this context, the parameter we are investigating is the population proportion (P), which is 0.10.
If we extract a simple random sample of 50 dolphins, we might find that 14% of the individuals in that specific group are black. A second sample might show a proportion of only 8%. Just as with means, the sample proportion will fluctuate from one group to the next. By taking 200 such samples and recording the proportion of black dolphins in each, we can construct a sampling distribution of the proportion, visualized through another histogram.

The resulting distribution will typically exhibit a bell-shaped curve. Most samples will yield proportions hovering near the 10% mark. The center of this distribution will be located at the true population proportion. This allows us to apply similar mathematical logic to categorical data, identifying how likely we are to observe a specific percentage within a random sample. This is particularly useful in fields like sociology, epidemiology, and market research.
The properties for the sampling distribution of the proportion are defined as follows:
- μp = P (The mean of the sample proportions is equal to the population proportion).
- σp = √[(P)(1-P) / n] (The standard error of the proportion).
For our dolphin population, the mean of the distribution is 0.1. Using the standard deviation formula for proportions with our sample size of 50, we calculate the standard error as √[(0.1)(0.9) / 50], which results in 0.042. This value quantifies the expected deviation of our sample proportions from the actual 10% population figure.
Conditions for Normality and the Central Limit Theorem
For the mathematical formulas and probability calculations to be valid, the sampling distribution must approximate a normal distribution. The most critical tool for establishing this is the central limit theorem (CLT). The CLT states that as long as the sample size is sufficiently large, the sampling distribution of the mean will be normal, regardless of whether the underlying population distribution is skewed, uniform, or otherwise non-normal.
In most statistical practices, a sample size (n) of 30 or greater is considered the standard threshold for the central limit theorem to take effect. If the population is already normally distributed, the sampling distribution will be normal even for very small samples. However, the CLT is particularly powerful because it allows us to perform complex statistics on real-world data that often fail to follow a perfect bell curve in its raw state.
When dealing with the sampling distribution of a proportion, the criteria for normality differ slightly. Instead of a fixed sample size of 30, we look at the expected number of “successes” and “failures.” A distribution of proportions is generally considered normal if both np ≥ 10 and n(1-p) ≥ 10. This ensures that the sample size is large enough relative to the proportion to prevent the distribution from being cut off at the 0% or 100% boundaries, maintaining the integrity of the bell curve.
Practical Application: Calculating Probabilities for Continuous Variables
Understanding sampling distributions allows us to solve practical problems involving probability. Consider a manufacturing example: a specific industrial machine produces cookies. The weights of these cookies are skewed to the right, with a population mean (μ) of 10 ounces and a standard deviation (σ) of 2 ounces. If we select a simple random sample of 100 cookies, what is the probability that the average weight of this sample is less than 9.8 ounces?
First, we must establish normality. Although the population is skewed, our sample size of 100 is well above the threshold of 30. Therefore, the central limit theorem guarantees that our sampling distribution of the mean will be approximately normal. Next, we determine the parameters of this distribution. The mean μx remains 10 ounces, while the standard error (σx) is calculated as 2 / √100, which equals 0.2 ounces.
Finally, we utilize a Z-score or a cumulative distribution function calculator to find the specific probability. By comparing our target value of 9.8 ounces against the distribution centered at 10 with a spread of 0.2, we can determine how many standard deviations away the target lies. This process translates raw data into actionable insights, helping manufacturers maintain quality control and understand the likelihood of production variances.

By examining the area to the left of 9.8 on the normal distribution curve, we find that the probability of the sample mean being less than 9.8 ounces is approximately 0.15866. This indicates there is roughly a 15.87% chance that a random batch of 100 cookies will have an average weight that low, providing a clear mathematical basis for operational decision-making.
Practical Application: Calculating Probabilities for Categorical Proportions
We can apply the same logic to categorical data, such as student preferences. Suppose a study indicates that 87% of students at a large university prefer pizza over ice cream. If we take a simple random sample of 200 students, we might want to know the probability that the proportion of pizza lovers in that sample is less than 85%.
To begin, we verify the conditions for normality for proportions. We calculate the expected successes (0.87 * 200 = 174) and expected failures (0.13 * 200 = 26). Since both values exceed 10, we can safely proceed using the normal model. The mean of our sampling distribution (μp) is 0.87, and the standard error (σp) is calculated as √[(0.87 * 0.13) / 200], which is approximately 0.024.
Using these parameters, we look for the probability of a sample proportion falling below 0.85. This involves calculating the Z-score for 0.85 within our established distribution. This type of analysis is crucial for researchers who need to determine if their sample results are consistent with known population data or if they suggest a significant change in trends.

The calculation reveals that the area to the left of 0.85 on our curve corresponds to a probability of 0.20233. Consequently, there is about a 20.23% chance that a random sample of 200 students will yield a pizza preference proportion of 85% or lower, even if the true population preference remains at 87%.
The Significance of Sampling Distributions in Statistical Inference
The concept of the sampling distribution is not merely an academic exercise; it is the engine that drives modern statistics. Without it, we would have no way to determine the significance of our findings. By understanding how samples behave, we can distinguish between a result that occurred by pure chance and one that reflects a genuine characteristic of the population.
This framework is essential for hypothesis testing. When we calculate a p-value, we are essentially asking: “Assuming the null hypothesis is true, how likely is it to obtain a sample statistic as extreme as the one we observed?” The sampling distribution provides the answer by mapping out the expected variation under the null hypothesis. This allows researchers to make objective decisions about rejecting or failing to reject their theories.
In conclusion, the sampling distribution provides the necessary context for interpreting any piece of data. Whether analyzing dolphin weights, manufacturing consistency, or student opinions, this concept ensures that our conclusions are based on mathematical probability rather than guesswork. It transforms isolated sample observations into powerful tools for understanding the broader world.
Bonus: Video Explanation of Sampling Distributions
Cite this article
stats writer (2026). How to Understand Sampling Distributions in Statistics. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-a-sampling-distribution/
stats writer. "How to Understand Sampling Distributions in Statistics." PSYCHOLOGICAL SCALES, 28 Feb. 2026, https://scales.arabpsychology.com/stats/what-is-a-sampling-distribution/.
stats writer. "How to Understand Sampling Distributions in Statistics." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-a-sampling-distribution/.
stats writer (2026) 'How to Understand Sampling Distributions in Statistics', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-a-sampling-distribution/.
[1] stats writer, "How to Understand Sampling Distributions in Statistics," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Understand Sampling Distributions in Statistics. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.