Table of Contents
An influential observation in statistics refers to a data point that has a significant impact on the results of statistical analysis. This observation holds a high degree of leverage and can greatly affect the overall conclusions and outcomes of a study. Influential observations can arise due to extreme values, outliers, or influential data points that do not follow the expected pattern of the data. It is important to identify and properly handle influential observations in statistics to ensure accurate and reliable results.
What is an Influential Observation in Statistics?
In statistics, an influential observation is an observation in a dataset that, when removed, dramatically changes the of a regression model.
The most common way to measure the influence of observations is to use Cook’s distance, which quantifies how much all of the fitted values in a regression model change when the ith observation is deleted.
As a rule of thumb, any observation with a Cook’s distance greater than 1 is considered to be an observation with high leverage.
The following example shows how to calculate and interpret Cook’s distance for a given dataset to detect potential influential observations.
Example: Detecting Influential Observations
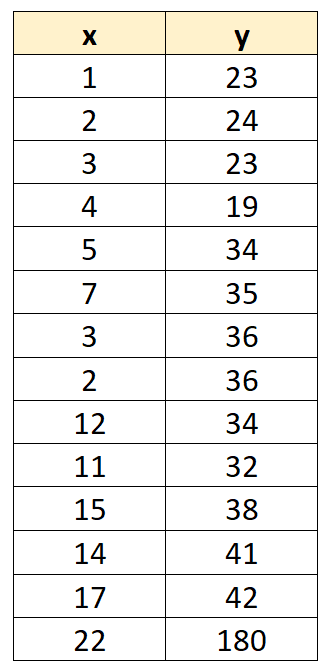
Suppose we have the following dataset with 14 values:

Now suppose we fit a . The regression output is shown below:

Using statistical software, we can calculate the following values for Cook’s distance for each observation:

Notice that the last observation has a value significantly greater than 1 for Cook’s distance, which tells us that it’s an influential observation.
Suppose we remove this value from the dataset and fit a new simple linear regression model. The output for this model is shown below:

Notice that the regression coefficients for the intercept and x both changed dramatically. This tells us that removing the influential observation from the dataset completely changed the fitted regression model.
The following plots show the difference between these two fitted regression equations:

Notes
It’s important to note that Cook’s distance should be used as a way to identify potentially influential observations. However, just because an observation is influential doesn’t necessarily mean that it should be deleted from the dataset.
First, you should verify that the observation isn’t a result of a data entry error or some other odd occurrence. If it turns out to be a legit value, you can then decide to deal with it in one of the following ways:
- Delete it from the dataset.
- Leave it in the dataset.
- Replace it with an alternative value like the mean or median.
Depending on your specific scenario, one of these options may make more sense than the others.
How to Calculate Cook’s Distance in Practice
The following tutorials explain how to calculate Cook’s distance for a given dataset in Python and R:
Cite this article
stats writer (2024). What constitutes an influential observation in statistics?. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-constitutes-an-influential-observation-in-statistics/
stats writer. "What constitutes an influential observation in statistics?." PSYCHOLOGICAL SCALES, 28 Apr. 2024, https://scales.arabpsychology.com/stats/what-constitutes-an-influential-observation-in-statistics/.
stats writer. "What constitutes an influential observation in statistics?." PSYCHOLOGICAL SCALES, 2024. https://scales.arabpsychology.com/stats/what-constitutes-an-influential-observation-in-statistics/.
stats writer (2024) 'What constitutes an influential observation in statistics?', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-constitutes-an-influential-observation-in-statistics/.
[1] stats writer, "What constitutes an influential observation in statistics?," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, April, 2024.
stats writer. What constitutes an influential observation in statistics?. PSYCHOLOGICAL SCALES. 2024;vol(issue):pages.