Table of Contents
Identify Influential Data Points Using Cook’s Distance
An Introduction to Diagnostic Analytics via Cook’s Distance
In the sophisticated realm of regression analysis, ensuring the integrity of a predictive model requires more than just fitting a line to a cloud of points; it necessitates a rigorous diagnostic process to identify observations that disproportionately sway the results. Cook’s distance, frequently denoted as Di, serves as a premier statistical metric designed to pinpoint these influential data points. By evaluating how much the estimates of a linear regression model change when a specific observation is removed, researchers can determine whether their findings are robust or merely artifacts of a few anomalous entries. This objective measure of influence is essential for maintaining the reliability of statistical inferences and the overall predictive power of the model.
Understanding the distinction between a simple outlier and an influential observation is paramount for any data scientist or statistician. While an outlier is defined by its substantial deviation from the general trend of the data, an influential point is one that specifically alters the slope or intercept of the regression line. Cook’s distance provides a standardized way to quantify this impact, allowing for a systematic approach to data cleaning that transcends subjective visual inspection. By calculating a score for every individual observation within a dataset, this technique highlights those points that possess high leverage or large residuals, both of which contribute to the total influence exerted on the fitted values of the model.
The application of this technique is a cornerstone of model validation, as it assists in identifying potential errors in data entry, sampling irregularities, or genuine phenomena that require specialized modeling techniques. Without such diagnostics, a multiple linear regression might produce coefficients that do not accurately represent the majority of the population, leading to flawed conclusions and ineffective decision-making. Consequently, the mastery of Cook’s distance is not merely a theoretical exercise but a practical necessity for anyone engaged in high-stakes quantitative research or business analytics.
The Mathematical Foundation of Influential Metrics
To grasp the utility of this diagnostic tool, one must examine the mathematical components that comprise the formula for Cook’s distance. The metric effectively combines information regarding the magnitude of the residual and the degree of leverage to produce a comprehensive score of influence. By integrating these two distinct aspects of data behavior, the formula offers a more nuanced view than either metric could provide in isolation, ensuring that points far from the mean of the predictor variables are scrutinized alongside those with extreme response values.
The standardized formula for Cook’s distance is expressed as follows:
Di = (ri2 / p*MSE) * (hii / (1-hii)2)
Within this equation, several critical variables are at play, each representing a specific attribute of the data point in relation to the model:
- ri represents the ith residual, which quantifies the vertical distance between the observed value and the predicted value.
- p is the total number of coefficients included in the regression analysis, encompassing the intercept and all independent variables.
- MSE stands for the mean squared error, providing a measure of the average squared difference between estimated values and actual observations.
- hii is the ith leverage value, derived from the hat matrix, which identifies how far an independent variable value is from its mean.
While the intricacies of this formula may appear daunting at first glance, contemporary statistical software packages have streamlined the computation process, allowing researchers to generate these values with minimal manual effort. The primary objective of the calculation is to determine the aggregate change in all fitted values of the model that would occur if the ith observation were omitted from the dataset. This sensitivity analysis is the core function of the metric, providing a clear indication of which observations are essentially “driving” the model’s parameters and potentially masking the true underlying relationships between variables.
Interpreting Influence and the Threshold for Intervention
Once the Cook’s distance values have been calculated for a dataset, the next step involves interpreting these scores to make informed decisions about model refinement. A large value for an observation indicates that its presence significantly shifts the regression coefficients. In practical terms, this means that the model would look substantially different if that specific point were not included, which raises questions about the generalizability of the results. To assist in this interpretation, statisticians often employ heuristic rules to differentiate between standard variations and truly influential anomalies.
A widely accepted rule of thumb suggests that any data point possessing a Cook’s distance greater than 4/n, where n represents the total number of observations, should be flagged for closer examination. Other practitioners may use a more conservative threshold of 1.0, though the 4/n approach is often preferred in smaller datasets where even moderate deviations can have a profound impact. Identifying these points is the first step toward understanding the unique characteristics of the data that might be skewing the statistical model and potentially leading to Type I or Type II errors in hypothesis testing.
It is vital to recognize that the identification of an influential point does not automatically mandate its deletion. An influential observation might be a perfectly valid data point that represents a rare but real phenomenon, or it could be the result of a measurement error. Before taking corrective action, a thorough investigation into the source of the outlier is necessary. If the point is found to be a recording error, removal or correction is justified; however, if it represents a unique segment of the population, it might suggest that the current linear model is insufficient and that a non-linear or robust regression approach might be more appropriate.
Implementing Computational Diagnostics in the R Environment
The R programming language provides a robust environment for conducting these diagnostics through its extensive library ecosystem and built-in statistical functions. To demonstrate the practical application of Cook’s distance, we can construct a controlled environment using the ggplot2 and gridExtra packages. This allows for the simultaneous visualization of datasets with and without influential anomalies, highlighting the dramatic shifts that outliers can induce in a standard regression line.
The initial phase of the analysis involves loading the necessary libraries and establishing the datasets. In the following example, we create two distinct data frames to serve as the basis for our comparison: one representing a clean dataset and another containing intentional outliers designed to test the sensitivity of the model.
library(ggplot2) library(gridExtra)
By defining these data frames, we can simulate real-world scenarios where data collection might be compromised by extreme values. The R code below establishes these data structures, setting the stage for a side-by-side comparison of their regression properties.
#create data frame with no outliers
no_outliers <- data.frame(x = c(1, 2, 2, 3, 4, 5, 7, 3, 2, 12, 11, 15, 14, 17, 22),
y = c(22, 23, 24, 23, 19, 34, 35, 36, 36, 34, 32, 38, 41,
42, 44))
#create data frame with two outliers
outliers <- data.frame(x = c(1, 2, 2, 3, 4, 5, 7, 3, 2, 12, 11, 15, 14, 17, 22),
y = c(190, 23, 24, 23, 19, 34, 35, 36, 36, 34, 32, 38, 41,
42, 180))Visualizing the Distortion Caused by Influential Points
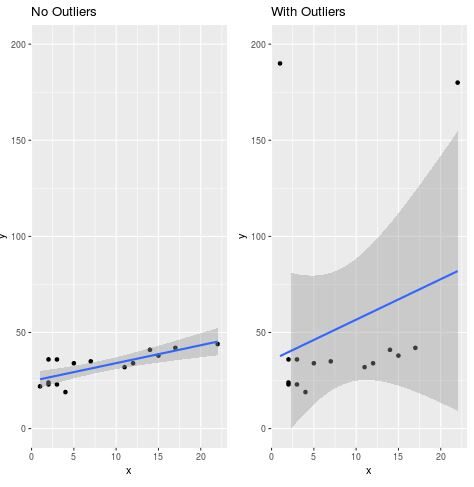
Visualization is a powerful tool for understanding the impact of influential observations on linear regression models. By utilizing a scatterplot, we can observe how the regression line attempts to minimize the distance to all points, including those that are clearly not representative of the main data cluster. When influential points are present, they act like a magnetic force, pulling the line away from the majority of the data and increasing the residuals for the remaining points, thereby degrading the model’s accuracy.
To illustrate this, we generate two plots using ggplot2. The first plot displays a consistent trend, while the second shows the distortion caused by the outliers we introduced in the previous step. The use of the geom_smooth function with the method = lm argument allows us to see the fitted regression line directly on the plot.
#create scatterplot for data frame with no outliers
no_outliers_plot <- ggplot(data = no_outliers, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = lm) +
ylim(0, 200) +
ggtitle("No Outliers")
#create scatterplot for data frame with outliers
outliers_plot <- ggplot(data = outliers, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = lm) +
ylim(0, 200) +
ggtitle("With Outliers")
#plot the two scatterplots side by side
gridExtra::grid.arrange(no_outliers_plot, outliers_plot, ncol=2)
The resulting visual output clearly demonstrates the negative influence of outliers. In the second plot, the regression line is noticeably flatter and less representative of the linear trend seen in the first plot. This visual evidence underscores why identifying such points via Cook’s distance is a critical step in any analytical pipeline, as it provides a quantifiable basis for what the eye can clearly perceive as a lack of fit.
Quantifying Influence and Applying Cutoff Thresholds
Beyond visual inspection, we must use the cooks.distance() function in R to generate specific scores for each observation. This algorithmic approach is more scalable and less prone to human error than visual analysis alone. Once the Cook’s distance values are generated, they can be plotted against an index of observations, with a horizontal line representing the 4/n threshold. This diagnostic plot makes it immediately apparent which specific data points are exceeding the acceptable limits of influence.
The following code snippet demonstrates how to fit a model, calculate the distances, and create a diagnostic plot to identify the problematic observations. By explicitly calculating the threshold as 4/n, we ensure that our criteria for influence are dynamically adjusted based on the size of our sample size.
#fit the linear regression model to the dataset with outliers model <- lm(y ~ x, data = outliers) #find Cook's distance for each observation in the dataset cooksD <- cooks.distance(model) # Plot Cook's Distance with a horizontal line at 4/n to see which observations#exceed this thresdhold n <- nrow(outliers) plot(cooksD, main = "Cooks Distance for Influential Obs") abline(h = 4/n, lty = 2, col = "steelblue") # add cutoff line

The diagnostic plot highlights that the first and last observations in our dataset significantly exceed the 4/n threshold. These points are thus flagged as influential. In a professional data analysis workflow, this would be the moment where the researcher pauses to investigate these specific rows in the dataset to understand why they are exerting such extreme influence over the regression model.
Refining the Model through Strategic Observation Removal
After identifying influential data points, the researcher must decide on the most appropriate course of action. If the investigation reveals that these points are indeed erroneous or non-representative of the population being studied, the most common solution is to remove them from the dataset and refit the model. This process of data cleansing can lead to a much more accurate and stable model that better reflects the underlying trends of the majority of the data.
In R, we can easily filter out these observations by identifying their indices and creating a new data frame that excludes them. This programmatic approach ensures that the removal process is documented and reproducible, which is a key requirement for rigorous scientific research.
#identify influential points influential_obs <- as.numeric(names(cooksD)[(cooksD > (4/n))]) #define new data frame with influential points removed outliers_removed <- outliers[-influential_obs, ]
With the influential points removed, we can now generate a final comparison. By plotting the regression line with and without these points, we can see the dramatic improvement in the model’s fit. The second plot in the following sequence represents a much more reliable linear regression, where the slope and intercept are determined by the consistent relationship between the variables rather than being skewed by anomalous outliers.
#create scatterplot with outliers present
outliers_present <- ggplot(data = outliers, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = lm) +
ylim(0, 200) +
ggtitle("Outliers Present")
#create scatterplot with outliers removed
outliers_removed_plot <- ggplot(data = outliers_removed, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = lm) +
ylim(0, 200) +
ggtitle("Outliers Removed")
#plot both scatterplots side by side
gridExtra::grid.arrange(outliers_present, outliers_removed_plot, ncol = 2)
The visual evidence is conclusive: removing the influential data points has restored the integrity of the regression analysis. The model now provides a much more faithful representation of the data’s central tendency, demonstrating the critical importance of Cook’s distance as a diagnostic tool for ensuring model validity and statistical significance.
Best Practices and Technical Considerations
Effective regression analysis involves a continuous cycle of fitting, diagnosing, and refining. While Cook’s distance is a powerful metric, it should be used in conjunction with other diagnostic tools, such as residual plots and Q-Q plots, to ensure a comprehensive understanding of the model’s performance. Furthermore, analysts must remain cognizant of the context in which their data was collected, as some “influential” points may contain the most valuable information in the entire dataset.
When dealing with influential points, several strategies are available to the analyst beyond simple deletion:
- Detailed Investigation: Examine the source of the data to check for measurement error or data entry mistakes.
- Data Transformation: Apply logarithmic or square root transformations to variables to reduce the impact of extreme values.
- Robust Regression: Utilize robust regression techniques that naturally down-weight the influence of outliers.
- Sensitivity Reporting: Keep the points in the model but report the results both with and without the influential observations to provide full transparency.
In conclusion, Cook’s distance is an indispensable diagnostic for anyone performing linear regression. By quantifying the influence of each observation, it allows for a more rigorous and objective approach to model building. Whether you are using R, Python, or traditional statistical software, incorporating this metric into your workflow will significantly enhance the quality, accuracy, and defensibility of your analytical findings.
Cite this article
stats writer (2026). How to Identify Influential Data Points Using Cook’s Distance. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-cooks-distance-be-used-to-identify-influential-data-points/
stats writer. "How to Identify Influential Data Points Using Cook’s Distance." PSYCHOLOGICAL SCALES, 4 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-cooks-distance-be-used-to-identify-influential-data-points/.
stats writer. "How to Identify Influential Data Points Using Cook’s Distance." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-cooks-distance-be-used-to-identify-influential-data-points/.
stats writer (2026) 'How to Identify Influential Data Points Using Cook’s Distance', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-cooks-distance-be-used-to-identify-influential-data-points/.
[1] stats writer, "How to Identify Influential Data Points Using Cook’s Distance," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Identify Influential Data Points Using Cook’s Distance. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.