Table of Contents
The Significance of Frequency Analysis in Modern Data Science
Frequency analysis serves as a fundamental pillar within the realm of descriptive statistics, offering critical insights into the distribution and recurring nature of data points within a specific dataset. By identifying the most frequent numbers, analysts can uncover underlying patterns, detect potential anomalies, and synthesize large volumes of raw information into manageable, actionable insights. In the professional landscape of data analysis, the ability to isolate these recurring values is essential for making informed decisions across diverse fields such as finance, healthcare, and information technology.
In the context of Microsoft Excel, which remains the industry standard for spreadsheet management, determining the top five most frequent numbers allows for a deeper understanding of historical trends and predictive modeling. This process is not merely about counting occurrences; it is about identifying the central tendency of data which may not be immediately apparent through a simple mean or median calculation. Advanced users leverage these techniques to refine their quantitative research, ensuring that the results are both statistically significant and practically relevant to their organizational goals.
Furthermore, the utility of finding the most frequent values extends to quality control and inventory management, where identifying the most common error codes or the most frequently purchased items can lead to significant operational improvements. By utilizing specific functions within Microsoft Excel, such as COUNTIF and MODE, users can automate the extraction of this data, reducing the likelihood of human error and increasing the efficiency of their analytical workflows. This strategic approach to data management ensures that stakeholders are provided with a clear and concise summary of the most impactful numerical values within their repositories.
Theoretical Foundations of the MODE Function
The concept of the mode is defined as the value that appears most often in a set of data. While Microsoft Excel provides basic functions to find a single mode, extracting a ranked list of the top five most frequent numbers requires a more sophisticated approach involving nested logical statements and array-like behaviors. Understanding the underlying algorithm of these formulas is crucial for any analyst who wishes to move beyond basic data entry into the sphere of professional data modeling and Big Data processing.
Historically, the MODE function in older versions of Microsoft Excel was limited to identifying only the single most frequent value. However, modern analytical requirements often necessitate identifying the second, third, or fifth most frequent values to understand the full scope of data distribution. This is where the integration of Boolean logic and error-handling functions becomes vital, allowing the user to exclude previously identified modes and find the next most frequent value in a sequential and automated manner.
By employing a combination of functions, users can create a dynamic list that updates automatically as the source data changes. This level of automation is a hallmark of high-level data mining, where the goal is to create robust systems that require minimal manual intervention. The theoretical framework of these formulas relies on the ability of Microsoft Excel to evaluate ranges of data against specific criteria, a capability that transforms a simple table into a powerful engine for business intelligence and statistical discovery.
Understanding the Complex Formula Logic
To identify the top five most frequent numbers in a dataset, we utilize a specialized formula that combines the MODE function with IF, ISERROR, and MATCH. This nested structure serves a specific purpose: it checks the range for the most frequent number while simultaneously cross-referencing a list of already identified numbers. If a number has already been found, the formula ignores it, effectively moving to the next most frequent value in the hierarchy.
The specific syntax for this advanced operation is as follows:
=MODE(IF(ISERROR(MATCH($A$2:$A$24,C$1:C1,0)),$A$2:$A$24))
This particular formula is designed to operate within the range A2:A24. The core logic hinges on the MATCH function, which searches for the current value within the results already produced in column C. When the MATCH function fails to find a value (meaning it hasn’t been listed yet), the ISERROR function returns TRUE, allowing the IF function to pass that number to the MODE function for evaluation.
By dragging this formula down across five cells, the user creates an iterative process. Each subsequent cell references an expanding range in column C, ensuring that each new result is unique. This methodology is particularly effective for managing numerical analysis where duplicate values are expected and must be accounted for without skewing the final ranking of the most frequent entries.
Practical Demonstration: Finding the Top 5 Frequent Numbers
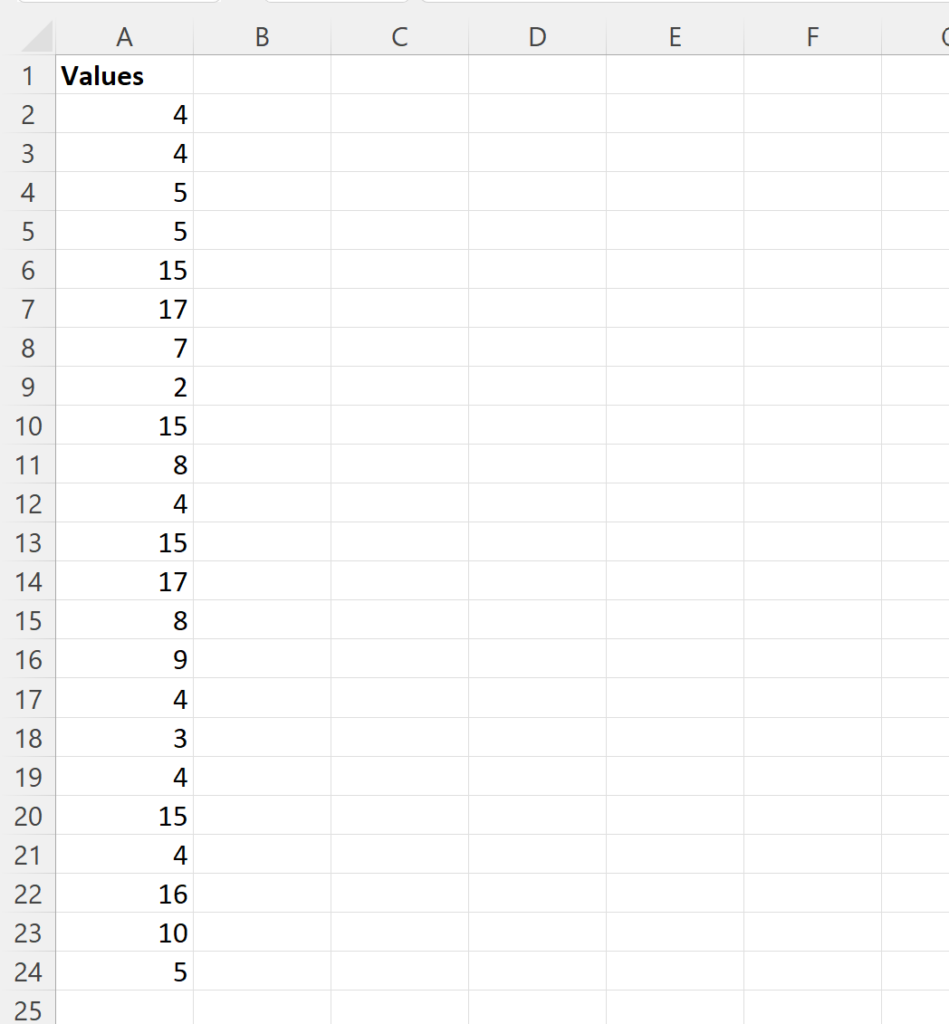
To better illustrate the application of this technique, let us consider a practical example involving a raw list of numerical data. Suppose we have a series of observations or measurements recorded in an Excel worksheet. Our objective is to determine which five numbers appear most often, which will help us understand the primary drivers or most common outcomes within our study.
Suppose we have the following list of numbers in Excel:

In this scenario, we wish to systematically extract the five most frequent numbers without manually sorting the data. Manual sorting is not only time-consuming but also prone to error, especially when dealing with large databases. Instead, we implement the dynamic formula to provide a real-time summary of the most prevalent data points. This approach is highly valued in financial auditing and scientific research for its objectivity and repeatability.
To begin the extraction process, we input our specialized formula into cell C2, which serves as the starting point for our frequency list. The formula effectively “scans” the target range and identifies the first mode while setting the stage for subsequent calculations. This step is critical as it establishes the reference point for the iterative logic that follows in the subsequent rows of the analysis column.
Executing the Multi-Value Extraction
Once the initial formula is established in cell C2, the user must extend this logic to find the remaining four values. This is achieved by utilizing the fill handle in Microsoft Excel to drag the formula down to the next four cells (C3 through C6). As the formula is copied, the relative reference C$1:C1 expands to include the cells above it, effectively “filtering out” the values already identified as the most frequent.
=MODE(IF(ISERROR(MATCH($A$2:$A$24,C$1:C1,0)),$A$2:$A$24))
We can then click and drag this formula to four more cells in column C:

Upon completing this action, Column C will display the five most frequently occurring numbers from Column A in descending order of their frequency. This visual representation allows for immediate data visualization of the primary modes. It is important to note that if there is a tie in frequency, Excel will typically return the value that appears first in the dataset, a nuance that analysts should keep in mind during statistical inference.
This method of extraction is far superior to basic filtering because it maintains the integrity of the original data while providing a separate, clean summary table. Analysts can then use this summary to generate reports, create charts, or perform further predictive analytics. The ability to isolate the most significant numbers in this fashion is a key skill for anyone working in business administration or technical research roles.
Calculating Frequency Counts with COUNTIF
Identifying the most frequent numbers is only the first half of the process; to provide a complete analysis, one must also quantify exactly how many times each of these numbers appears. This provides a clear metric of the “strength” of each mode. For this task, the COUNTIF function is the ideal tool, as it is designed to count the number of cells within a range that meet a single criterion.
To find the frequency of each identified number, we enter the following formula into cell D2:
=COUNTIF($A$2:$A$24, C2)
By dragging this formula down to the remaining cells in column D, we create a corresponding list of counts for each of our top five numbers. This step transforms our list of values into a comprehensive frequency distribution table, which is a standard requirement in academic writing and professional data analysis reports.

The resulting table provides a dual-layered insight: the numbers that occur most often and the specific magnitude of their occurrence. This combination is particularly useful when performing a Pareto analysis, where the goal is to identify the “vital few” factors that contribute to the majority of an outcome. By quantifying the frequency, the analyst can prioritize which data points require the most attention or investigation.
Interpreting the Analytical Results
With the data successfully processed and the counts established, the final step involves interpreting the results to draw meaningful conclusions. The output provides a clear hierarchy of the data’s most common characteristics. In our specific example, the analysis reveals a clear concentration of certain numerical values, which can then be used to inform broader decision-making processes.
From the final output, we can observe the following statistical insights:
- The number 4 occurs most frequently in the list, with a total of 6 occurrences, indicating it is the primary mode of the dataset.
- The number 15 ranks as the second most frequent value, appearing 4 times within the specified range.
- The number 5 is identified as the third most frequent, occurring 3 times.
These findings allow researchers to focus their efforts on these specific values. For instance, in a sales environment, if these numbers represented product IDs, the business would know which items are the most popular. In a technical environment, if these represented error codes, the software engineering team would know which bugs are most prevalent and require immediate patching.
By following this structured approach, users can ensure their Excel workbooks remain sophisticated and highly functional. The transition from raw data to a ranked frequency list is a powerful demonstration of how logical formulas can be used to extract high-value intelligence from standard spreadsheets.
Advanced Considerations for Larger Datasets
While the formulas discussed are highly effective for small to medium-sized datasets, larger Big Data sets may require even more robust solutions. In such cases, Microsoft Excel users might consider using Pivot Tables or the Power Query tool. These features provide a more scalable way to handle hundreds of thousands of rows while maintaining high performance and data integrity.
Furthermore, it is essential to ensure that the data being analyzed is clean and free of formatting errors. Non-numeric characters or hidden spaces can cause the MODE and MATCH functions to return incorrect results or errors such as #N/A. Therefore, a preliminary step of data cleansing is always recommended to ensure the accuracy of any statistical output generated in Excel.
As information technology continues to evolve, the integration of Python and R scripts directly into Excel provides even more avenues for complex frequency analysis. However, for the majority of professional tasks, mastering the logic of nested formulas remains a critical and highly sought-after competency in the modern workplace.
Summary and Further Learning
In conclusion, finding the five most frequent numbers in Excel is a multi-step process that involves identifying modes, excluding duplicates through logical checks, and quantifying occurrences with counting functions. This systematic approach ensures that the analysis is objective, accurate, and easily reproducible. By mastering these techniques, individuals can significantly enhance their data analysis capabilities and provide more valuable insights to their organizations.
The following tutorials and resources offer additional information on how to manage frequencies and perform advanced statistical operations within Excel. For those looking to further expand their knowledge, exploring the official Microsoft Support documentation is an excellent next step to master the nuances of spreadsheet algorithms and logical functions.
Continuous learning in this field is essential as new versions of Excel introduce dynamic array functions like UNIQUE and SORT, which can complement the legacy methods described here. Staying updated on these developments ensures that your analytical skills remain at the cutting edge of information technology and business intelligence standards.
Cite this article
stats writer (2026). How to Find the 5 Most Frequent Numbers in Excel. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-are-the-5-most-frequent-numbers-in-excel/
stats writer. "How to Find the 5 Most Frequent Numbers in Excel." PSYCHOLOGICAL SCALES, 27 Feb. 2026, https://scales.arabpsychology.com/stats/what-are-the-5-most-frequent-numbers-in-excel/.
stats writer. "How to Find the 5 Most Frequent Numbers in Excel." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-are-the-5-most-frequent-numbers-in-excel/.
stats writer (2026) 'How to Find the 5 Most Frequent Numbers in Excel', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-are-the-5-most-frequent-numbers-in-excel/.
[1] stats writer, "How to Find the 5 Most Frequent Numbers in Excel," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Find the 5 Most Frequent Numbers in Excel. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.