Table of Contents
The Standard Deviation is a fundamental metric in statistics used to quantify the amount of variation or dispersion of a set of values. When working within Google Sheets, calculating this measure is straightforward, provided you select the correct function based on whether your data represents a full population or merely a sample. For analyzing a subset of data, known as the sample standard deviation, you must utilize the function =STDEV.S(). Conversely, if your data encompasses the entire group of interest, or the population, you should employ the function =STDEV.P(). In both cases, you simply specify the range of cells containing your numerical data within the parentheses. Understanding the distinction between these two statistical contexts—sample versus population—is paramount for ensuring the accuracy and validity of your statistical analysis.
The Role of Standard Deviation in Data Analysis
The Standard Deviation is one of the most common and effective ways to measure the dispersion within a data set. It tells us, on average, how much the values deviate from the mean (the average). A low standard deviation indicates that the data points tend to be close to the mean, while a high standard deviation indicates that the data points are spread out over a wider range of values. This metric provides essential context for understanding the distribution shape and overall variability of a given data stream.
Understanding variance is critical across many disciplines, from finance, where volatility is measured, to quality control, where consistency is paramount. For instance, in analyzing investment returns, a stock with a low standard deviation of returns is generally considered less volatile and thus less risky than a stock with a high standard deviation. In academic research, measuring standard deviation helps researchers determine if observed effects are consistent or merely random fluctuations within the data.
While standard deviation is closely related to variance (it is the square root of the variance), it is generally preferred for interpretation because it is expressed in the same units as the original data. This characteristic makes it much easier to relate back to the raw measurements. Since Google Sheets provides specialized functions to handle the complex calculations involved, users can focus solely on interpreting the results and applying statistical principles correctly.
Differentiating Population vs. Sample Standard Deviation
The calculation of standard deviation depends critically on whether the data you possess represents the entire group you are interested in (the population) or just a subset of that group (the sample). These two scenarios require slightly different formulas to account for statistical bias, leading to the use of two distinct functions in Google Sheets: STDEV.P and STDEV.S, respectively.
The Population Standard Deviation (denoted by the Greek letter sigma, σ) is calculated when every single observation of interest is included in your data set. This is often feasible only when dealing with small, discrete groups, such as the ages of all employees in a small company or the test scores of every student in a single classroom. Since the entire population is known, the calculation provides the true measure of spread.
In contrast, the Sample Standard Deviation (denoted by the Latin letter s) is used far more frequently in practical statistics. It is calculated when the data you have collected is merely a representative selection taken from a much larger population. Because a sample rarely perfectly represents the full population, the formula uses a technique known as Bessel’s correction (dividing by n – 1 instead of N) to provide an unbiased estimate of the true population standard deviation. This adjustment compensates for the fact that sample data inherently tends to underestimate the overall variability of the larger population from which it was drawn.
Calculating Population Standard Deviation (σ): Formula Breakdown
When working with a complete population, the goal is to find the exact spread of the data points relative to the population mean (μ). The process involves calculating the squared difference between each data point and the mean, summing these squared differences, dividing by the total number of observations (N), and finally taking the square root of the result. This ensures that the population parameters are measured accurately.
The mathematical expression for the population standard deviation, denoted as σ, is:
σ = √Σ(xi – μ)2 / N
In this formula, the following components are defined:
- Σ: This is the summation symbol, indicating that you must sum all the calculated values.
- xi: Represents the ith individual value in the data set.
- μ: Denotes the population mean, which is the average of all values in the data set.
- N: Represents the population size, which is the total count of observations in the data set.
For large populations, manually performing these calculations is incredibly time-consuming and error-prone. This is precisely why tools like Google Sheets are invaluable, automating the entire sequence of operations through the highly reliable STDEV.P function.
Calculating Sample Standard Deviation (s): Formula Breakdown
The calculation of the sample standard deviation differs slightly from the population calculation due to the incorporation of Bessel’s correction, which adjusts for the loss of a degree of freedom when estimating the population mean from the sample data. This correction involves dividing by n – 1 instead of n, making the resulting standard deviation a slightly larger, more conservative estimate of the spread.
The mathematical expression for the sample standard deviation, denoted as s, is:
s = √Σ(xi – x̄)2 / (n – 1)
The components of the sample formula are defined as follows:
- Σ: The summation symbol, indicating the sum of all calculated values.
- xi: The ith individual value observed in the sample data.
- x̄: The sample mean, which is the average of the observed sample values.
- n: Represents the sample size, which is the total count of observations within the sample.
It is crucial to use this formula, or the corresponding STDEV.S() function in Google Sheets, any time you are working with a subset of data intended to generalize findings back to the larger target population. Failure to use the correction factor (n – 1) would result in a systematically biased, low estimate of the true population spread.
Implementation in Google Sheets: Using STDEV.S for Sample Data
The most common scenario in data analysis is collecting a sample and calculating its standard deviation. Google Sheets simplifies this task significantly through the use of the STDEV.S() function. This function automatically applies Bessel’s correction, providing an unbiased estimate of the population standard deviation based on your subset of data. Furthermore, it is important to note that the older, un-suffixed function, STDEV(), is equivalent to STDEV.S() and will also return the sample standard deviation.
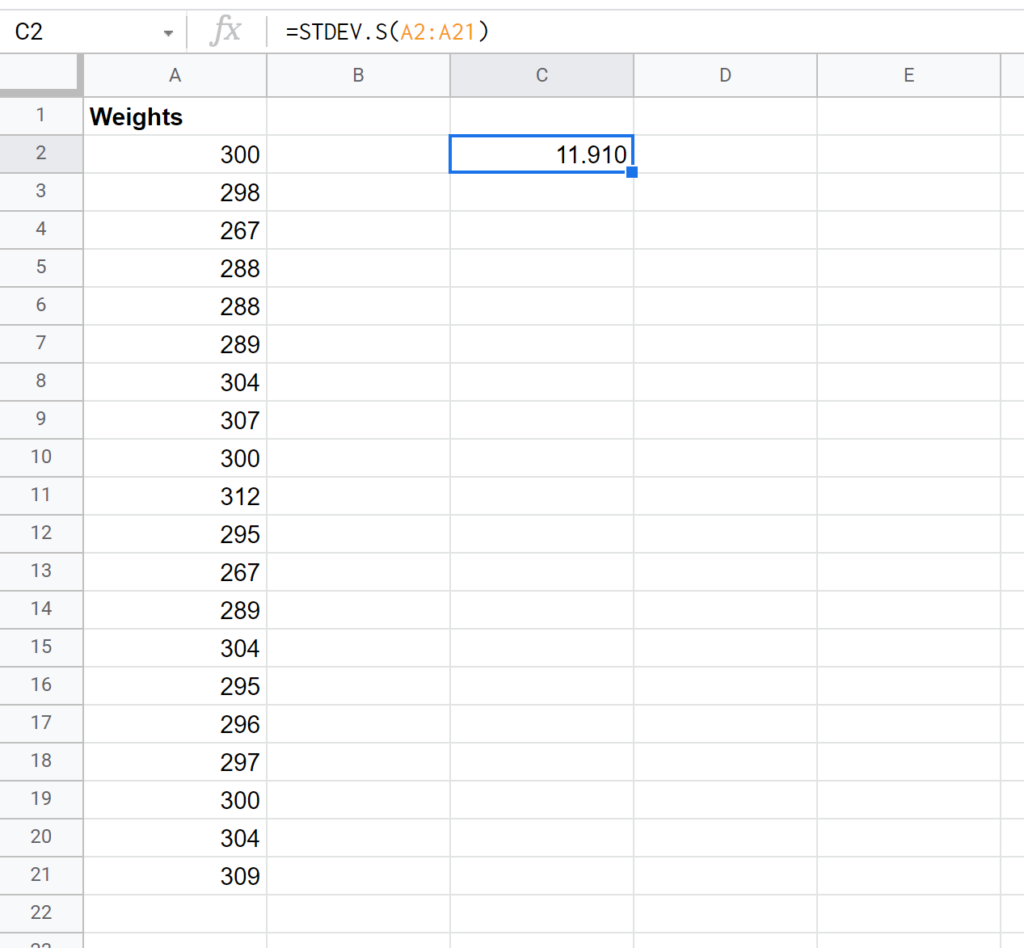
Consider a scenario where a biologist has collected data on the weights of 20 turtles, which represents only a small portion of the entire species population she is studying. Since this data is a sample, she must use STDEV.S() to accurately summarize the weight variability. If the data points are stored in a range, say from cell A2 to A21, the required formula in Google Sheets would be: =STDEV.S(A2:A21).
The following illustration demonstrates how to utilize the STDEV.S() function to calculate the sample standard deviation for a column of weights. The result derived from the sample weights is 11.91, offering a measure of how dispersed the turtle weights are relative to their sample mean.

This calculated value of 11.91 quantifies the typical deviation of any individual turtle’s weight from the average weight observed in this specific group of 20 turtles. This result is then used to infer the variability within the entire population of turtles.
Implementation in Google Sheets: Using STDEV.P for Population Data
While less frequent than sample analysis, situations arise where your collected data set truly encapsulates the entire population of interest. In these instances, using the STDEV.P() function is mandatory, as applying Bessel’s correction would introduce an upward bias in the calculation. The STDEV.P() function calculates the true standard deviation (σ) without any necessary correctional factors.
Imagine a basketball coach who is analyzing the points scored by the 12 players currently on his team’s roster. His scope of interest is limited strictly to these 12 individuals; he is not trying to generalize findings to all basketball players globally. Since his data set includes the scores of every player he cares about, it constitutes a complete population, and the function STDEV.P() must be used.
If the 12 players’ scores are listed in cells B2 through B13, the formula would be written as: =STDEV.P(B2:B13). This command executes the population standard deviation formula, providing the exact spread of scores for that specific team.
The following screenshot illustrates the calculation for the population standard deviation using the STDEV.P() function. The resulting population standard deviation is 7.331, which precisely describes the variability of scores within this particular group of 12 players.

Conclusion: Mastering Measures of Spread in Google Sheets
The ability to accurately calculate the Standard Deviation is a foundational skill for anyone working with data in Google Sheets. By correctly distinguishing between population data and sample data, and applying the corresponding functions—STDEV.P() or STDEV.S()—you ensure the statistical rigor of your analysis. This measure of spread is essential for moving beyond simple averages and gaining a deep understanding of data distribution and risk.
For users looking to expand their knowledge of statistical measures in spreadsheets, the following tutorials offer additional information about standard deviation calculations and related concepts:
- Understanding Variance: Exploring the square of the standard deviation.
- Z-Scores and Standard Deviation: How standard deviation is used for normalization.
- Confidence Intervals: Utilizing standard deviation to estimate parameter ranges.
Furthermore, Google Sheets offers various functions to calculate other crucial measures of data spread and centrality:
- Calculating Range: Using
MAX()andMIN()functions. - Calculating Quartiles: Using the
QUARTILE()function to understand distribution.
Cite this article
stats writer (2025). How to Easily Calculate Standard Deviation in Google Sheets. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-calculate-standard-deviation-in-google-sheets-sample-population/
stats writer. "How to Easily Calculate Standard Deviation in Google Sheets." PSYCHOLOGICAL SCALES, 3 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-calculate-standard-deviation-in-google-sheets-sample-population/.
stats writer. "How to Easily Calculate Standard Deviation in Google Sheets." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-calculate-standard-deviation-in-google-sheets-sample-population/.
stats writer (2025) 'How to Easily Calculate Standard Deviation in Google Sheets', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-calculate-standard-deviation-in-google-sheets-sample-population/.
[1] stats writer, "How to Easily Calculate Standard Deviation in Google Sheets," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Calculate Standard Deviation in Google Sheets. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.