Table of Contents
Understanding R’s Default Behavior When Importing Data
When importing a CSV file into R, users often encounter automatic modifications to column headers, particularly when those headers contain non-standard characters like spaces. By default, R is designed to ensure that all column names meet the criteria for being valid variable names within its environment. This is a crucial feature designed to simplify subsequent data manipulation and analysis, as standard variable names avoid the need for special syntax.
The standard function used for this purpose, read.csv(), automatically calls a housekeeping function internally. If you import a CSV file that contains column names with spaces (e.g., “Customer ID”), R will replace these spaces with periods (dots). Thus, “Customer ID” becomes “Customer.ID”. This substitution is part of R’s effort to create syntactically correct identifiers that can be easily referenced without special notation during coding, ensuring compatibility with most analytical functions and packages.
While this automatic conversion is beneficial for maintaining code hygiene and preventing syntax errors during typical analytical workflows, it can sometimes be confusing if the user strictly requires the original column names to be preserved exactly as they appeared in the source file, perhaps for reporting consistency, integration with legacy systems, or direct presentation outputs. Therefore, understanding how to override this default behavior is essential for precise data preparation tasks in R.
Overriding the Default: The Role of check.names=FALSE
To successfully import a CSV file into R while preserving column names exactly as they are—including any spaces or special characters that would normally be converted—you must explicitly instruct the read.csv() function to skip its name validation process. This is achieved by setting the optional argument check.names to FALSE.
The check.names argument is a logical parameter within the read.csv() function (and related functions like read.table). When set to its default value of TRUE, R verifies that the column names are syntactically valid variable names, replacing invalid characters such as spaces, parentheses, or operators. By setting it to FALSE, we disable this check, allowing the column names to be imported verbatim, spaces and all, directly into the resulting data frame.
Using this specific argument is the definitive method for maintaining original header formatting within R. The core syntax for this operation is as follows:
df <- read.csv("my_data.csv", check.names=FALSE)
This command ensures that the structure of the column headers remains identical to the source file, regardless of any embedded spaces or unusual characters that R would typically standardize.
Detailed Example: Data Setup and Default Import Behavior
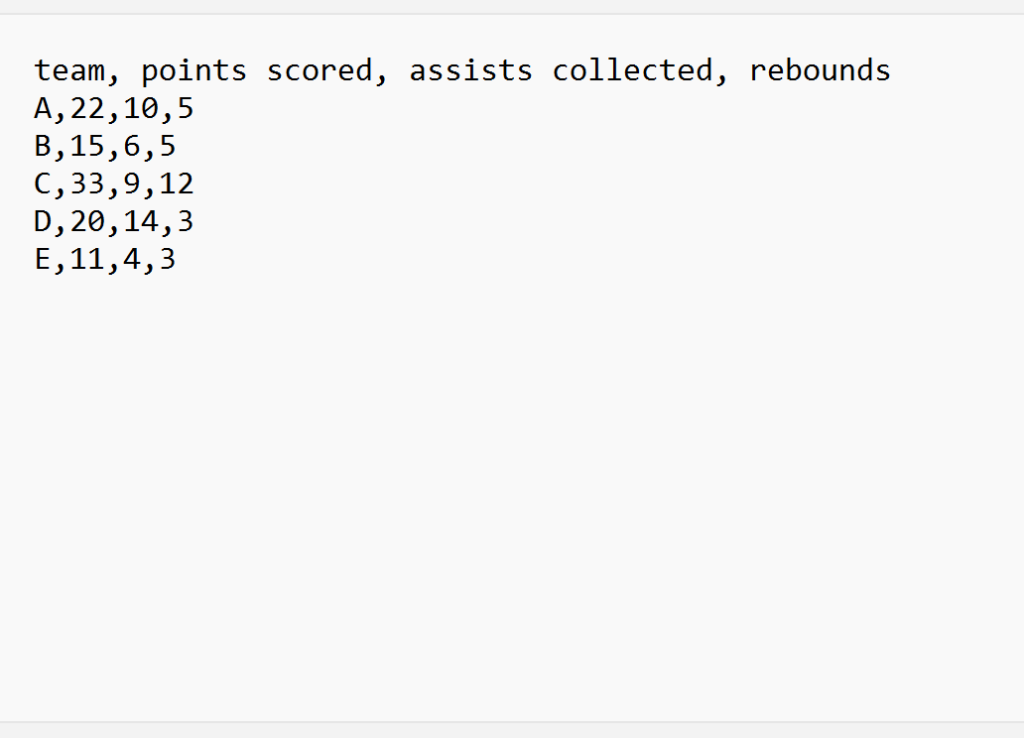
To illustrate the necessity of check.names=FALSE, let us examine a practical scenario involving sports data. Suppose we have a source file named basketball_data.csv, which contains descriptive headers that intentionally include spaces for clarity in the original spreadsheet format.
The contents of our CSV file are structured as follows:

We are particularly interested in the headers: team, points scored, assists collected, and rebounds. The second and third columns clearly contain spaces. If we attempt a standard import using the basic read.csv() function without specifying any arguments, R applies its default validation routine, sanitizing the names:
# Import CSV file using default settings
df <- read.csv('basketball_data.csv')
# View the resulting data frame structure
df
team points.scored assists.collected rebounds
1 A 22 10 5
2 B 15 6 5
3 C 33 9 12
4 D 20 14 3
5 E 11 4 3
As observed, the spaces in “points scored” and “assists collected” have been automatically converted to periods, resulting in the new column names points.scored and assists.collected. This output confirms the standard R behavior of ensuring that all column names are valid variable names, which are essential for seamless integration with R’s internal data processing architecture.
Implementing the Solution: Preserving Spaces in Column Names
To ensure strict preservation of the original column headers, we must rerun the import command, explicitly employing the check.names=FALSE argument. This is the mechanism that forces R to bypass the default naming validation step and accept the column names exactly as they are defined in the external file.
We apply this critical modification within the read.csv() call, providing the full instruction set to the function:
# Import CSV file and keep spaces in column names
df <- read.csv('basketball_data.csv', check.names=FALSE)
# View the data frame to confirm structure
df
team points scored assists collected rebounds
1 A 22 10 5
2 B 15 6 5
3 C 33 9 12
4 D 20 14 3
5 E 11 4 3
Upon viewing the resulting data frame, we can confirm that the column names points scored and assists collected now retain their original spacing. This demonstrates the effectiveness of the check.names=FALSE argument. While this achieves the goal of preserving names, users must be immediately aware that this choice necessitates a specific syntax when interacting with these columns later in the analytical workflow.
The Critical Requirement for Back-Quotes in Operations
The successful retention of spaces in column names comes with a significant requirement when performing subsequent operations in R. Because the column names are no longer syntactically valid R variable names (due to the embedded spaces), they cannot be accessed directly using the standard dollar sign ($) notation followed immediately by the name.
To correctly reference a column name containing spaces, the entire name must be enclosed in single back-quotes (`). The back-quote functions as an escape mechanism, instructing the R interpreter to treat the enclosed string as a literal identifier, overriding the usual parsing rules that would otherwise break upon encountering a space. Failure to use back-quotes when referencing these non-standard names will invariably result in a syntax error, halting execution of the script.
For instance, if we attempt to calculate the sum of the values in the points scored column without utilizing the mandatory back-quotes, R will report an error:
# Attempt to calculate sum of points scored column
sum(df$points scored)
Error: unexpected symbol in "sum(df$points scored"
The error, Error: unexpected symbol, arises because R interprets the space as a delimiter, treating points and scored as separate, unexpected elements in the function call syntax.
Executing Code on Non-Standard Column Names
To successfully execute any function or operation on a column name containing spaces, the back-quote syntax is essential. This ensures that the entire string, including the spaces, is interpreted as a single, valid identifier referring to the desired column within the data frame.
The correction requires surrounding the entire column name with back-quotes:
# Calculate sum of points scored column correctly
sum(df$`points scored`)
[1] 101
The successful output confirms that the back-quotes are the necessary mechanism for handling non-standard column names that were imported using check.names=FALSE. This requirement applies universally, whether you are subsetting rows, manipulating data with packages like dplyr, or building statistical models. Consistent adherence to this syntax is crucial to prevent runtime errors in subsequent data analysis steps.
Best Practices: Standardizing Names for Maintainable Code
While the check.names=FALSE argument provides flexibility, it often leads to less readable and more error-prone code due to the mandatory use of back-quotes. For production scripts, complex analyses, or collaborative environments, standardizing column names is strongly recommended.
Analysts typically follow one of two highly efficient strategies to ensure clean, valid variable names:
Embrace R’s Default Conversion: The simplest approach is to omit the
check.names=FALSEargument entirely. By allowingread.csv()to convert spaces to dots (e.g.,points.scored), you gain column names that are inherently syntactically valid and do not require any special escaping syntax. Many R users consider dot separation a standard convention for multi-word identifiers.Post-Import Cleaning with Packages: If you prefer a different convention, such as snake_case (e.g.,
points_scored), the most efficient solution is to import the data using default settings and then immediately use a dedicated utility package to sanitize the names. Thejanitorpackage, specifically itsclean_names()function, is industry-standard for this task. It automatically converts names to a clean, consistent format (typically snake_case), handling spaces, special characters, and capitalization instantly.# Example using janitor package library(janitor) df <- read.csv('basketball_data.csv') df <- clean_names(df) # Output names will be: team, points_scored, assists_collected, rebounds
Resorting to check.names=FALSE should be limited to unique use cases where external consistency outweighs internal R coding clarity. In almost all general analytical workflows, standardization provides superior code quality and maintainability.
Summary of Data Import Guidelines
Successfully managing the import of data requires navigating R’s default naming rules. Here is a definitive recap of the approaches discussed:
Problem Identification: Column names in external files (like CSVs) often contain spaces or special characters that R converts to dots by default.
Solution for Preservation: To force R to keep the original spaces in column headers, use the argument
check.names=FALSEwhen callingread.csv().Post-Import Handling: Any subsequent code that references columns with spaces must use single back-quotes (
`) around the full column name to avoid syntax errors.Recommended Alternative: For streamlined and robust scripting, utilize packages like
janitoror accept R’s default dot conversion to ensure that column names are always syntactically valid and easy to reference without specialized escape characters.
For further information on data loading and manipulation in R, consider these related topics:
Cite this article
stats writer (2025). How to Easily Import a CSV File into R with Space-Containing Column Names. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-you-import-a-csv-file-into-r-with-column-names-that-contain-spaces/
stats writer. "How to Easily Import a CSV File into R with Space-Containing Column Names." PSYCHOLOGICAL SCALES, 21 Nov. 2025, https://scales.arabpsychology.com/stats/how-do-you-import-a-csv-file-into-r-with-column-names-that-contain-spaces/.
stats writer. "How to Easily Import a CSV File into R with Space-Containing Column Names." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-do-you-import-a-csv-file-into-r-with-column-names-that-contain-spaces/.
stats writer (2025) 'How to Easily Import a CSV File into R with Space-Containing Column Names', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-you-import-a-csv-file-into-r-with-column-names-that-contain-spaces/.
[1] stats writer, "How to Easily Import a CSV File into R with Space-Containing Column Names," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, November, 2025.
stats writer. How to Easily Import a CSV File into R with Space-Containing Column Names. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.